中高数学+物理+プログラミングのオンライン勉強会¶
概要¶
勉強会用に準備した資料をせっかくなので公開. Zoom でやっていて動画も撮っているが, それは私以外の参加者の声も入っているので非公開.
もともとは次のコンテンツのブラッシュアップのためなどいくつかの目的で, 必要なことを教えるので協力してくれないか, という感じではじめた勉強会.
周辺知識を揃えないとつらくなってきたので, IT 関係の基礎知識も紹介するようになった. あと課題もあると嬉しいという話があり, 実際に中高生に勉強してもらうときも参考になるだろうと思い, 課題も毎回作って適当に解説もしている.
ipynb to md¶
必要なら nbconver で markdown 化. ブログにあげるときは面倒なので画像はアップしていない.
1 2 | |
企画趣旨¶
はじめに¶
いま, 1 年くらいの長期にわたって知人と少人数でゆるく統計学・機械学習系の勉強会をしている. そこからのスピンオフで Python と基本的な数学に関する勉強会をやろうと思っていて, その内容に関する事前説明資料として記事にする. 説明資料が長文になるのでその共有のためもあり, 他の人もそれぞれで同じようなことをやってほしいのもあり, この計画が参考になるだろうと思ったのもある. 私が持っているコンテンツを提供できるので, 必要なら連絡してほしい.
バリバリと進んだことがやりたい中高生向けの数学・物理・プログラミング教育を進めようと思っていて, いまちょうど新型コロナで話が潰れているが, 実際に地元の知り合いの政治家・自治体にも提案はしている. Jupyter notebook でコンテンツを作っていて, まだ完全にチェックできていないオンラインのプログラミング環境の検証も兼ねている. 経験上も慣れていない人がプログラミング環境をローカルに作るのは本当に大変なので, Google Colabolatory などプログラミング環境をオンラインで完結させたい. よくも悪くも時代がそうなっていくだろうというのもある.
言語として Python は好きではないが, 事実上の入門デファクトという感もあるので, とりあえずそこにした. 数学・物理系で入門レベルの情報がとても多く, それなりに質もあり, バリエーション豊かなところは最THE高とは思う
ちなみにさらなるコンテンツ作成のために次の GitHub リポジトリにコードをためていて, それで生成した動画は YouTube に上げている. 興味があればぜひ眺めてほしい.
- 数値計算関係の GitHub https://github.com/phasetr/mathcodes
- YouTube のプレイリスト https://www.youtube.com/playlist?list=PLSBzltjFopraTJUYDMXnj1GdYCdR0QyzU
さらに次のページに数学系の無料の通信講座をいくつか置いてある. 登録用のページだけでも数学・物理の勉強をする参考になると思うので, これも興味があれば眺めてほしい.
大方針¶
私の趣味・守備範囲もあるので, 数学・物理方面からプログラミングに入る. 基本的な方向性としては次の無料通信講座と, その続編として作ったコンテンツを基礎にして展開する.
次の大方針で進める.
- まずは細かいことはさておき, プログラミングでできることをゴリゴリ紹介する
- まずはお絵描き中心
- 離散化すれば四則演算でしかないので微分・積分をダイレクトに数値計算する形で進める
- まずは波動方程式・拡散方程式を見せる
- 波と拡散というイメージと視覚がマッチした対象だから
- まずは概要を掴むのが目的なので本質的な数学部分が難しくなるのは気にしない
- 何をするにも慣れが必要なので, とにかく浴びて慣れてもらうのが目的
- お絵描き+数値計算で Python プログラミングの気分を掴む
- 少しずつプログラムの詳細を見ていく
- 暴力的な量の四則演算を進めるだけなので「数学」の話は最低限に留めながら進める
- ある程度慣れてきた段階でプログラムと並行して数学の話をする
概要・議論の順番¶
いま考えているのは次のような感じ.
- ある意味での終着点, 波動方程式・拡散方程式の数値計算結果の動画を見る・作ってみる
- 偏微分方程式はわけわからなくても最終的に計算させる離散化の式はそれはそう, という感じのはずなのでそれを紹介する
- 他にも微分方程式でどんな現象が表せてどんなことができるか紹介する
- 常微分方程式の紹介
- ホジキン-ハクスレー方程式 (大雑把に言ってノーベル医学・生理学賞の対象 (らしい)
- フィッツヒュー・南雲方程式
- 放射性物質の崩壊の方程式
- ロジスティック方程式
- 単振動の方程式
- 微分方程式の数値計算の観点から見た中高数学の復習とプログラムへの落とし込み
- 常微分方程式の紹介
- 中高数学の復習をしつつ Python プログラムへの落とし込み
いったん別のところで組み上げたコンテンツがあるので, それをブラッシュアップしつつ進める予定. その意味では目次もある: 中高数学の復習の部分が詳しいだけではある. 質疑応答しつつ, 適当にプログラミングについても補足説明を入れていく.
ちなみに波動方程式や拡散方程式の数値計算結果は次のような感じ.
とりあえずはこんなところか. 録画しておいて, YouTube にも公開する予定. 他の人が勉強会をする参考になるはずだから, 質問・コメントが来たらこちらにも回答を追加していこう.
2020-04-19課題¶
はじめに¶
- コンテンツの案内ページ
- GitHub へのリンク
00-introduction_02_jupyter.ipynbを一通り読んで Jupyter notebook(大雑把には Google Colab も同じ)の概要を把握してください。特に次の点に注意して読んでください。- コードセルとテキストセルがあること
- 文章を書く(まさに「このセル」)はテキストセル
- プログラムを書くのはコードセル
- コードセルには「実行」という概念・操作がある
- Colab の操作についての参考ページメモ
- コードセルとテキストセルがあること
- テキストセルを作ってください。
- テキストセルに何か文章を書いてみてください。文章は「あ」だけでも構いません。
- TeX 形式で次のような式を打ってみてください。「このセル」をダブルクリックで開くとどうすれば式が打てるかわかるので、そのコピペで構いません。他にも資料を漁ってどんな風に書くとどう表示されるか眺めてみるといいでしょう。
$$\int_0^1 f(x) \, dx$$
- コードセルを作ってください。
01-basic_01_fundamental.ipynbを参考にprint("Hello, World!")を実行してみてください。「実行結果出力欄」に「Hello, World!」と出れば成功です。
- もう 1 つコードセルを作ってください。
01-basic_03_matplotlib.ipynbを参考に、グラフを 1 つ書いてみてください。コピペでグラフが出てくることを確認するだけで十分です。- お好みでの追加タスク:いろいろ推測しながらプログラムを少しいじってみて、直線以外のグラフを描いたり、グラフを描く範囲を変えてみてください。
プログラムを勉強するときの注意¶
- プログラミング「言語」と言われるように、いわゆる語学を勉強するときのコツがある程度流用できます。
- 「英作文は英借文」というように、既に動いている(通じる)「例文」をコピペしてみましょう。そこからパーツを少し変えてみてどうなるか試します。
- プログラミング言語は機械が意味を判定するので、文法に厳格に沿っていないと「きちんと文法通りに話せ」と怒られます。
- ある程度まで来たらこの文法もきちんと勉強する必要があります。
- よほどの趣味を持っていない限り、文法の勉強は初学の段階であまり面白いものでもないので、まずは
01-basic_01_fundamental.ipynbに書いてあることを雑に眺めて気分を掴んでください。 - 公式のチュートリアルも参考になります。
- Web 上の資源の問題として、リンクがたくさん張られている関係でいろいろな所に飛ばされる(飛びたくなる)ことがあります。本だと自分でページを飛ばさない限り一直線の道を歩むしかないので、Web 上の資源で勉強すると気が散るなら本を買ってざっと眺めるのも一手です。
- 一般の語学でも実際に読み書きしないと身につかないように、プログラムも実際に読み書きしないと身につきません。Jupyter notebook 配布のいいところはすぐにコード実行できるところにあります。パチパチ実行してみてください。
解答例¶
参考:TeX¶
$f(x)$のように 1 つのドルマークで囲むと地の文に普通に埋め込まれる式として $\int f(x) dx$ が書けます。$$\int f(x) dx, \left{a\in A \mid a>0, b>0 \text{かつ} c>0\right}$$と 2 つのドルマークで囲むと別行立ての式 $$\int f(x) dx$$ が書けます。\begin{align} \int f(x) dx \end{align}などと書くと、数式環境下での式が書けます。 \begin{align} \int f(x) dx \end{align}- 複数行ある複雑な式を書くときは数式環境下で式を書きます:参考リンク。
- 数式環境と
$$\int f(x)dx$$型との違い・使い分けについては次のように考えましょう. $$\int f(x) dx$$はあくまで地の文に埋め込みたいが縦・横に長い式なので別行立ての方が見やすい場合に使う\begin{align} \int f(x) dx \end{align}は複数行にわたるハードな式展開・計算を書くときに使う.
$\epsilon$ $\varepsilon$
$$A = (a_{ij}) = \begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1n} \ a_{21} & a_{22} & \cdots & a_{2n} \ \vdots & \vdots & \ddots & \vdots \ a_{m1} & a_{m2} & \cdots & a_{mn} \end{pmatrix}.$$
参考:Markdown¶
- テキストセルは TeX の他, markdown という形式で書けます.
- 参考リンク
- 参考リンク
- 参考リンク
- 段落分けや文字の強調などはこの形式に沿っています.
- 主に技術系の文書を書くために使われる書式なので, 過度な装飾はできません (そもそもそういう機能がない).
コード例¶
- sympy のサンプルを紹介します。
- Google Colab 上ではオリジナルの Jupyter より面倒で、追加処理が必要です。
- オリジナルの Jupyter では動くのに Google Colab 上では動かない (らしい) プログラムもあります
- 例:4 次方程式の解の公式の表示.
- 実際に一通り眺めて sympy をできる限り Google Colab 上でも動くようにするのはこの勉強会の目的の 1 つです.
```python !pip install --upgrade sympy
import sympy as sp from sympy.plotting import plot from IPython.display import display
def custom_latex_printer(expr, options): from IPython.display import Math, HTML from google.colab.output._publish import javascript url = "https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/MathJax.js?config=TeX-AMS_CHTML" javascript(content="""window.MathJax = { tex2jax: { inlineMath: [ ['$','$'] ], processEscapes: true } };""") javascript(url=url) return sp.latex(expr, options)
sp.init_printing(use_latex="mathjax", latex_printer=custom_latex_printer)
x = sp.Symbol('x') expr = x*2-12x+8 display(expr) ```
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
$\displaystyle x^{2} - 12 x + 8$
python x = sp.Symbol('x') y = sp.Symbol('y') expr1 = 2*x + 3*y - 6 expr2 = 3*x + 2*y - 12 display(expr1) display(expr2) #display(sp.solve((expr1, expr2))) # Math Processing error になる
1 | |
$\displaystyle 2 x + 3 y - 6$
1 | |
$\displaystyle 3 x + 2 y - 12$
python display(sp.solve((expr1, expr2)))
1 | |
$\displaystyle \left{ x : \frac{24}{5}, \ y : - \frac{6}{5}\right}$
- 上の方程式は厳密解として $x=4.8,y=-1.2$ を持つ。
- これの近似解として例えば $x=4.78888888,y=-1.1999999$
python p = plot(-(2/3)*x - 2, - (3/2)*x - 6, legend=True, show=False) p[0].line_color = 'b' p[1].line_color = 'r' p.show()
1 2 3 4 5 6 | |
```python eq1 = x2 + y2 - 1 eq2 = x - y
plot1 = sp.plot_implicit(eq1, line_color="blue", show=False) plot2 = sp.plot_implicit(eq2, line_color="green", show=False) plot1.extend(plot2) plot1.show() ```
1 2 3 4 5 6 7 8 9 10 11 12 | |
```python import sympy as sp from sympy.plotting import plot from IPython.display import display
def custom_latex_printer(expr, options): from IPython.display import Math, HTML from google.colab.output._publish import javascript url = "https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.7/MathJax.js?config=TeX-AMS_CHTML" javascript(content="""window.MathJax = { tex2jax: { inlineMath: [ ['$','$'] ], processEscapes: true } };""") javascript(url=url) return sp.latex(expr, options)
a,b,c,d,x = sp.symbols('a,b,c,d,x') expr = ax3 + bx*2 + cx + d
display(sp.solve(expr, x, dict=True)) ```
$\displaystyle \left[ \left{ x : - \frac{- \frac{3 c}{a} + \frac{b^{2}}{a^{2}}}{3 \sqrt[3]{\frac{\sqrt{- 4 \left(- \frac{3 c}{a} + \frac{b^{2}}{a^{2}}\right)^{3} + \left(\frac{27 d}{a} - \frac{9 b c}{a^{2}} + \frac{2 b^{3}}{a^{3}}\right)^{2}}}{2} + \frac{27 d}{2 a} - \frac{9 b c}{2 a^{2}} + \frac{b^{3}}{a^{3}}}} - \frac{\sqrt[3]{\frac{\sqrt{- 4 \left(- \frac{3 c}{a} + \frac{b^{2}}{a^{2}}\right)^{3} + \left(\frac{27 d}{a} - \frac{9 b c}{a^{2}} + \frac{2 b^{3}}{a^{3}}\right)^{2}}}{2} + \frac{27 d}{2 a} - \frac{9 b c}{2 a^{2}} + \frac{b^{3}}{a^{3}}}}{3} - \frac{b}{3 a}\right}, \ \left{ x : - \frac{- \frac{3 c}{a} + \frac{b^{2}}{a^{2}}}{3 \left(- \frac{1}{2} - \frac{\sqrt{3} i}{2}\right) \sqrt[3]{\frac{\sqrt{- 4 \left(- \frac{3 c}{a} + \frac{b^{2}}{a^{2}}\right)^{3} + \left(\frac{27 d}{a} - \frac{9 b c}{a^{2}} + \frac{2 b^{3}}{a^{3}}\right)^{2}}}{2} + \frac{27 d}{2 a} - \frac{9 b c}{2 a^{2}} + \frac{b^{3}}{a^{3}}}} - \frac{\left(- \frac{1}{2} - \frac{\sqrt{3} i}{2}\right) \sqrt[3]{\frac{\sqrt{- 4 \left(- \frac{3 c}{a} + \frac{b^{2}}{a^{2}}\right)^{3} + \left(\frac{27 d}{a} - \frac{9 b c}{a^{2}} + \frac{2 b^{3}}{a^{3}}\right)^{2}}}{2} + \frac{27 d}{2 a} - \frac{9 b c}{2 a^{2}} + \frac{b^{3}}{a^{3}}}}{3} - \frac{b}{3 a}\right}, \ \left{ x : - \frac{- \frac{3 c}{a} + \frac{b^{2}}{a^{2}}}{3 \left(- \frac{1}{2} + \frac{\sqrt{3} i}{2}\right) \sqrt[3]{\frac{\sqrt{- 4 \left(- \frac{3 c}{a} + \frac{b^{2}}{a^{2}}\right)^{3} + \left(\frac{27 d}{a} - \frac{9 b c}{a^{2}} + \frac{2 b^{3}}{a^{3}}\right)^{2}}}{2} + \frac{27 d}{2 a} - \frac{9 b c}{2 a^{2}} + \frac{b^{3}}{a^{3}}}} - \frac{\left(- \frac{1}{2} + \frac{\sqrt{3} i}{2}\right) \sqrt[3]{\frac{\sqrt{- 4 \left(- \frac{3 c}{a} + \frac{b^{2}}{a^{2}}\right)^{3} + \left(\frac{27 d}{a} - \frac{9 b c}{a^{2}} + \frac{2 b^{3}}{a^{3}}\right)^{2}}}{2} + \frac{27 d}{2 a} - \frac{9 b c}{2 a^{2}} + \frac{b^{3}}{a^{3}}}}{3} - \frac{b}{3 a}\right}\right]$
2020-04-19オンライン数学勉強会用イントロ¶
はじめに¶
まとめ¶
- 勉強会の案内ページ
- コンテンツの案内ページ
- GitHub へのリンク
- 目次の順序で進める
- 時間が余ったら適当に今回出てきた数学またはプログラミングの話を詳しく
事前準備:sympy インストールとチェック¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
1 | |
$$x^{2} - 12 x + 8$$
はじめの注意¶
- 吃音があるので聞きにくいと思います。
- 言いにくい場合は文字で書きます。
- いろいろ試験的な取り組みです。
- この資料はあとで配ります。
大方針¶
- Python でプログラミング
- 将来に向けたいろいろなテストを兼ねる
- 中高生または中高数学復習用に作ったコンテンツのテスト・流用
- 試験的に Google Colabolratory を利用
- いま使っている「これ」
- ローカルの環境構築がいらない
- TeX の形式を使うと式もきれいに書ける:$$\int_\Omega f(x) \, dx$$
- 何回くらい・どのくらいの期間になるかは不明
- なるべくゆっくり・ゆるく進める
- 日々いろいろなタスクがある大人向けの勉強会なのでゴリゴリにやると疲れ果てて続かない
- その代わり長期戦でのんびりやる
- 予習はやりたければやる
- 無理がない範囲で、長続きさせることを第一に
- 復習は勉強会の中でやる
- その分ペースも遅くなる
- その遅さが気になるなら予習をしよう
- 復習を自力でやれるくらいならはじめから独学できていると思う
勉強のコツ¶
- 「すぐに理解する・できる」という幻想を捨てる
- 同じことを何度も繰り返して、少しずつ慣れる
- 究極的には「独学」が必要
- そのサポートをするのがこの勉強会の目的
- 細部が詳しい本はたくさんあり、いろいろなレベルの本がたくさんある
- この勉強会の当面の主目的は概要を掴むこと
- 細かいことが気になったら都度調べるなり質問するなりしてもらう
- そしてすぐにわからなくても気にしない
進め方の方針¶
- 細かいことはさておき, プログラミングでできることをゴリゴリ紹介する
- まずはお絵描き中心:微分方程式を解く
- 後の内容も「中高数学のネタを視覚化する」方向で進める。
- 微分方程式に関して
- 高校数学の最終目的地の微分・積分に直結する
- 微分・積分は統計学をはじめとしたその他いろいろな応用でも主力
- 離散化すれば四則演算でしかないので微分・積分をダイレクトに数値計算する形で進める
- 今回、イメージづくりで波動方程式・拡散方程式を見せる
- 波と拡散というイメージと視覚がマッチした対象だから
- まずは概要を掴むのが目的なので本質的な数学部分が難しくなるのは気にしない
- 何をするにも慣れが必要なので, とにかく浴びて慣れてもらうのが目的
- お絵描き+数値計算で Python プログラミングの気分を掴む
- 少しずつプログラムの詳細を見ていく
- 暴力的な量の四則演算を進めるだけなので「数学」の話は最低限に留めながら進める
- ある程度慣れてきた段階でプログラムと並行して数学の話をする
基礎コンテンツの紹介¶
- 中高数学をプログラミングを軸にまとめた。
- この講座ではプログラミング、特に Python については深くは解説しない
- 必要ならその時々の新しい本で勉強すること。
- 古い本を選んでしまうと、最新の環境でその本に書かれたプログラムが動かない可能性がある。
講座の構成¶
- 数学に関わる Python の基礎
- 重要なライブラリ numpy のまとめ
- 重要なライブラリ matplotlib のまとめ
- 重要なライブラリ sympy のまとめ
- 上記ライブラリを使った数学プログラミングのまとめ
- 線型代数:ベクトルと行列
- 微分積分
- 確率
- 統計
- 常微分方程式
- 偏微分方程式
大まかな説明¶
- 最初の第 1 章:Python を使ってどんなことができるかを説明
- 特に Python 自体の基本的な機能とライブラリの使い方を説明
- 必要なコードは各箇所に書かれているので、ここは飛ばしてすぐに本編に進んでも問題ない
- 線型代数以降の各章から、数学・プログラミングが混然一体になった本編がはじまる。
- 常微分方程式の章を先に読んでみるのもおすすめします。
- 次の無料講座を Jupyter の形式にまとめ直したコンテンツ
- 応用からの中高数学再入門 自然を再現しよう 中高数学駆け込み寺
- この講座の前段ともいえる講座で、応用の視点から中高数学の大事な部分を大掴みに説明
- 上記リンク先の登録ページ自体も勉強の参考になるはず。
- 「大事なことは何度でも」の精神
注意・当面の進めるイメージ¶
- 下の 2 つを先にざっと眺める
- 既に無料講座として公開している常微分方程式の章を少しずつ詳しく進める
- 微分積分をやる
環境構築¶
Google Colab¶
- いわゆる gmail のアカウントがあれば使える。
- 「google colaboratory」でググってトップに出てくるページを開けば開くはず
- 公式のチュートリアルもあるので、それを見よう
Python のインストール¶
- インストールのことを「環境構築」とも呼ぶことにする
- 将来の対応を考えて、勉強会では Google Colaboratory で進めてみる
- ローカル(自分の PC)にインストールしたいなら、適当にやる
- 経験上、「素人」の状態で環境構築は本当に大変
- プログラミング・環境構築に慣れていない状態で数学と絡めた環境構築がしたいなら、Anaconda でインストールするのが楽
- Google Colab 前提なのでこれ以上詳しくは触れない
- 本格的にプログラミングするならローカルに環境を作るのは必須
本題:数学とアニメーション¶
定積分のアニメーション¶
- 定積分はグラフが囲む領域の面積
- いわゆる区分求積法:次のように定義する
\begin{align} \int_0^1 f(x) dx &= \lim_{n \to \infty} \frac{1}{n} \sum_{k=0}^{n-1} f \left( \frac{k}{n} \right), \ n = 2 &\Rightarrow \frac{1}{2} \left(f\left(\frac02\right) + f\left(\frac12\right)\right) \ n = 3 &\Rightarrow \frac{1}{3} \left(f\left(\frac03\right) + f\left(\frac13\right) + f\left(\frac23\right)\right) \end{align}
- 右辺に注目する
- $\frac{1}{n}$ は単なる割り算
- $\sum_{k=0}^{n-1}$ は $n$ 項足しているだけ
- $\lim$ は $n$ をどんどん大きくしている
- 数値計算でやること
- 十分大きな $n$ で右辺を計算する
- だいたい面積が近似できることを確認する
アニメーション用の基本関数¶
- 次の関数でいろいろやっている:今回詳しくは触れない
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
底辺と高さ 1 の直角三角形の面積¶
- 底辺×高さ / 2 = 1/2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
1 2 3 4 5 6 7 | |
参照用¶
\begin{align} \int_0^1 f(x) dx &= \lim_{n \to \infty} \frac{1}{n} \sum_{k=0}^{n-1} f \left( \frac{k}{n} \right), \ n = 2 &\Rightarrow \frac{1}{2} \left(f\left(\frac02\right) + f\left(\frac12\right)\right) \ n = 3 &\Rightarrow \frac{1}{3} \left(f\left(\frac03\right) + f\left(\frac13\right) + f\left(\frac23\right)\right) \end{align}
二次関数¶
- $x^2$ を $[0,2]$ で積分
- 面積は $\int_0^2 x^2 dx = 8/3 = 2.6666...$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
1 2 3 4 5 6 7 | |
定積分の大雑把なまとめ¶
- どんどん細かくしていくと、細かさに応じて近似がよくなる。
- 近似を上げていった最果てで厳密な値が得られるとみなす。
- 視覚的に確認すると定義の意図が見えやすくなる
- 定義の意図がわかっていないとプログラムを書くのも難しい
1 次元の波動方程式¶
- ひもの左端を揺らしたときのひもの振動(波)の様子を見る
- 波が右端まで行くと反射するところも見られる
偏微分方程式としての波動方程式¶
\begin{align} u_{tt} = c^2 u_{xx}, \quad \frac{\partial^2 u}{\partial t^2} = c^2 \frac{\partial^2 u}{\partial x^2}. \end{align}
- ここで $c$ は定数で物理的には波の速度。
- 物理だとこれをどうやって導出するかも問われる。
- ここではそうした議論はせず、とにかく数値的に解いてみて波を表している様子を眺める
\begin{align} \frac{\partial u}{\partial t} &= \lim_{\Delta t \to 0}\frac{u(t + \Delta t, x) - u(t,x)}{\Delta t} \ &\simeq \frac{u(t + \Delta t, x) - u(t,x)}{\Delta t} \end{align}
\begin{align} \frac{\partial^2 u}{\partial t^2} = \frac{\partial}{\partial t} \frac{\partial u}{\partial t}= \frac{u_t(t+\Delta t,x) - u_t(t,x)}{\Delta t} &\simeq \frac{\frac{u(t + \Delta t, x) - u(t,x)}{\Delta t} - \frac{u(t , x) - u(t- \Delta t,x)}{\Delta t}}{\Delta t} \end{align}
最終的に計算する式¶
\begin{align} u(t + \Delta t, x ) = 2 u(t,x) - u(t - \Delta t, x) + \left(\frac{c \Delta t}{\Delta x}\right)^2 \left(u(t, x + \Delta x) - 2 u(t,x) + u(t, x - \Delta x) \right). \end{align}
- 次の時刻 $t + \Delta t$ の値を計算するのに現在時刻 $t$ とひとつ前の時刻 $t - \Delta t$ の値を使っている。
- 最終的には四則演算だけ
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | |
1 | |
1 次元の拡散方程式¶
- 真ん中に置いておいた物質が周囲に拡散していく様子を見る
偏微分方程式としての拡散方程式¶
\begin{align} \frac{\partial u}{\partial t}= \nu \frac{\partial^2 u}{\partial x^2}. \end{align}
最終的に計算する式¶
\begin{align} u(t+ \Delta t, x) = u(t, x) + \nu \frac{\Delta t}{(\Delta x)^2} (u(t, x + \Delta x) - 2u(t,x) + u(t, x - \Delta x)). \end{align}
- これも四則演算だけ。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
2 次元の波動方程式¶
- イメージとしては膜の振動
- 真ん中を振動させてその波の伝播を見る
偏微分方程式としての波動方程式¶
\begin{align} u_{tt} = c^2 (u_{xx} + u_{yy}). \end{align}
- ここで $c$ は定数で物理的には波の速度
- 1 次元のときとの違いは $u_{yy}$ の追加
- 物理的には次元に依存する議論もあってそれほど簡単ではない
最終的に計算する式¶
\begin{align} &u(t + \Delta t, x, y) \ &= 2 u(t,x,y) - u(t - \Delta t, x, y) \ \quad &+ \left(\frac{c \Delta t}{\Delta x}\right)^2 \left(u(t, x + \Delta x,y) - 2 u(t,x,y) + u(t, x - \Delta x,y) \right) \ \quad &+ \left(\frac{c \Delta t}{\Delta y}\right)^2 \left(u(t, x,y + \Delta y) - 2 u(t,x,y) + u(t, x,y - \Delta y) \right) \ \end{align}
- 右辺の時刻は $t$ と $t - \Delta t$、つまり過去の時刻しか出てこない
- 過去の時間での情報さえわかれば未来の挙動がわかる
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 | |
微分方程式の大雑把なまとめ¶
- (いろいろな都合によって)物理では無限に細かいところで方程式を立てている
- そのままでは計算機に計算させられない
- 微分係数・導関数を定義によって有限化:差と商にわける。
- 有限に落とした部分は無限に細かくしていけば元の微分係数・導関数を近似できていると期待する
次回以降¶
- 常微分方程式のところをのんびり進める
- まずは微分方程式で何ができるのかをのんびり
- 微分方程式で記述できる現象を説明したあと、近似計算の数理を追う
- プログラムに落とし込む工夫を見る
- 数値計算プログラムを大雑把に眺める
- 講座・コンテンツ本体を眺める
質疑応答¶
- 今の時点での目標が何かとか
- こんな感じで進めてほしいとか
- こんなネタを扱ってほしいとか
要望メモ¶
- 小さな課題が欲しい。
- 成功体験を積もう。
- 予習の範囲を出す。
- 式とグラフの対応。いろいろお絵描きしてみる。どうやってプログラムに落とすか確認する。
アンケート¶
毎回アンケートを取っています. 質問や要望がある場合もこちらにどうぞ.
アンケートは匿名なので気楽にコメントしてください. 直接返事してほしいことがあれば, メールなど適当な手段で連絡してください.
2020-04-26 課題¶
はじめに¶
- コンテンツの案内ページ
- GitHub へのリンク
- 少なくとも英語・フランス語・ドイツ語・ウクライナ語・スペイン語では別行立ての式に句読点がついていました. 式に句読点がついている外国語, 特に英語の文献を探してみてください. 英語については arxiv が探しやすいでしょう. ドイツ語についてはアインシュタインの論文, フランス語では Serre の論文あたりが探しやすいだろうと思います.
- 引き続き TeX でいろいろな式を書いてみましょう. arxiv を彷徨って格好よさそうな式を https://mathpix.com/ で TeX 化してみると楽しいかもしれません.
- 引き続きプログラムをいろいろいじってみましょう. 例えば次のような方針があります. コンテンツからのコピペで構いません. 適切にコピペして動かすだけでも割と大変なので.
- (numpy を使って) いろいろな関数のグラフを描いてみましょう.
- (sympy を使って) いろいろな連立方程式を解いてみましょう.
- いろいろな微分方程式を解いてみましょう. 実際にコンテンツでも紹介しているように, 分点を自分でも変えていじってみるとのが第一歩です.
- (難しいのでやらなくても構いません) 近似について考えてみましょう. もとの関数 $f$ がほとんど 0 であるにも関わらず, 導関数が 0 とはかけ離れた関数を考えてみてください.
- 近似の基準として差の絶対値の最大値, つまり $\max_x |f(x) - g(x)|$ を取ることにします. この量が小さくても, 導関数に対する $\max_x |f'(x) - g'(x)|$ が小さいとは限らない関数を具体例を作ることで示したことにあたります. エネルギーは適当な導関数によって定義されるので, 近似に関する微妙なさじ加減が少し体験できます. (エネルギーは積分が絡むので実はもう少し面倒です.)
- 数値計算と微分方程式の近似解法についてはシンプレクティック積分法などの話題もあります.
$F(x)=0$ という関数があったとする。 これは導関数の $F'(x)$ も $F'(x)=0$ である。
自分用メモ¶
- 遅延型方程式に対するコメント追加
- 06 の introduction と overview の統合
- 人口論の説明のブラッシュアップ
- import に関する実演:めんどいのでローカルの Jupyter で。
解答例:忘れる前にメモしておく¶
句読点問題¶
- 英語: https://arxiv.org/pdf/2004.10785.pdf
- ドイツ語: Einstein, Zur Elektrodynamik bewegter Körper
- フランス語: Serre, Géométrie algébrique et géométrie analytique
TeX でいろいろな式を書こう¶
\begin{align} \int_0^\infty x^{2n} e^{-ax^2} \, dx &= \frac{(2n+1)!!}{2^{n+1}} \sqrt{\pi} a^{- n - 1/2}. \end{align}
\begin{align} \langle f, e^{-tH} g \rangle = \int_{\mathbb{R}^d} \mathbb{E}_W^x \left[ \overline{f(B_0)} g(B_t) e^{- \int_0^t V(B_s) ds} \right] dx. \end{align}
$\mathrm{R}$
いろいろなプログラムを書こう¶
numpy でのグラフ¶
1 2 3 4 5 6 7 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1 2 3 4 5 | |
1 2 | |
sympy での連立方程式¶
実際に解があるか目で見て確かめる。
1 2 3 4 5 6 7 8 9 10 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
1 | |
$$\left [ \frac{1}{2} + \frac{\sqrt{5}}{2}, \quad - \frac{\sqrt{5}}{2} + \frac{1}{2}\right ]$$
微分方程式¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | |
関数の近似¶
例¶
十分大きな $n$ に対する次の関数があります。 \begin{align} f(x) &= \frac{1}{n} \sin (e^n x), \ f'(x) &= \frac{e^n}{n} \cos (e^n x). \end{align} グラフを描いてみましょう。
1 2 3 4 5 6 7 8 9 10 11 | |
コメント¶
これは次のように思ってください。
- 関数 $f_n$ は元の関数 $f_0 = 0$ を(最大値ノルムで)よく近似できている。
- 関数 $f'_n$ は元の関数の導関数 $f'_0 = 0$ をよく近似できていない.
関数の近似はいろいろ難しいところがあって, それだけで論文になるレベルです. 同じ事情はベクトルの近似にもあります. いま流行りの統計学の応用としての自然言語処理でも, 言語の近さを量的にどう判定するかという問題があり, これはまさに言葉をどうベクトルで表現するか, 表したベクトルの近さを何でどう判定するかが問われています. 例えば, よくある「変換候補」遊びは, ある単語を打ち込んだとき, その人の入力の癖という観点から次にどのような語が来るか (どのような語が近いか) を統計的に判定する自然言語処理の事情が絡んでいます. このあたり, 既に「身近」なテーマで, そして身近なことは本当に難しいのでちょっと考えた程度でわかるような話ではありません. 何せ十分な精度で使いやすくかつ役に立ってもらわないといけないので.
2020-05-03 課題¶
- コンテンツの案内ページ
- GitHub へのリンク
- matplotlib の公式ドキュメントを見ていろいろ遊んでみてください。例えば次のようなことを試してみてください。
- 線の色を変えてみる。
- 点にマーカーをつける。
- 公式のサンプルやチュートリアルを試してみる。
- 引き続き TeX でいろいろな式を書いてみましょう。式が書けると数学系のコミュニケーションがだいぶ楽になります。
- 引き続きプログラムをいろいろいじってみましょう. 例えば次のような方針があります. コンテンツからのコピペで構いません. 適切にコピペして動かすだけでも割と大変なので.
- (numpy を使って) いろいろな関数のグラフを描いてみましょう.
- (sympy を使って) いろいろな連立方程式を解いてみましょう. グラフを描くのもおすすめです.
- いろいろな微分方程式を解いてみましょう. 実際にコンテンツでも紹介しているように, 分点を自分でも変えていじってみるとのが第一歩です.
自分用メモ¶
- 遅延型方程式に対するコメント追加
- import に関する実演
- Jupyter (IPython)でのはまりどころ解説を作ろう
- いったん変数を作ると他のセルでも読み込める(読み込めてしまう)
- 「セルを上から順に読み込まないと動かない」問題の原因
- カーネル再起動まで変数は残り続ける
解答例¶
プログラムのコピペの功罪¶
- プログラムをコピペしているだけだと自力で組み上げる力がつかない
- 私の作るコンテンツは基本的に「世のいろいろなコンテンツのギャップを埋める」ことを目的にする
- 大きな展望を見えるようにする
- 中規模の目標を作る
- 初学の段階で小さいプログラムしか書けないのもつまらない
- 世にある「まとも」なプログラム(numpy などのライブラリ)は規模が大きいので読む・勉強するのが大変
- どのくらいの規模のプログラムでどのくらいのモノが作れるのかを見たい
- コピペであってもプログラムが動けばそれだけで面白い(こともある)
- ある程度先まで見通せないと面白さも見えず、やる気が続かない
- 程々の規模のプログラムをコピペして動かしてみて様子を掴もう
matplotlib¶
- 公式サンプル
- これも公式:サンプルコードもある。
- 次のコードはコッホ曲線のサンプルから。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
TeX でいろいろな式を書こう¶
Poisson 積分¶
\begin{align} u\left(z_{0}\right) &= \frac{1}{2 \pi} \int_{0}^{2 \pi} u\left(e^{i \psi}\right) \frac{1-\left|z_{0}\right|^{2}}{| z_{0}-e^{\left.j \phi\right|^{2}}} d \psi, \ u(x, y) &= \frac{1}{2 \pi} \int_{0}^{2 \pi} u(a \cos \phi, a \sin \phi) \frac{a^{2}-R^{2}}{a^{2}+R^{2}-2 a R \cos (\theta-\phi)} d \phi, \ u(x, y, z)&=\frac{1}{4 \pi a} \int_{S} u \frac{a^{2}-R^{2}}{\left(a^{2}+R^{2}-2 a R \cos \theta\right)^{3 / 2}} d S. \end{align}
いろいろなプログラムを書こう¶
numpy でのグラフ¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
sympy¶
- Colab 上でもローカルの Jupyter でも動くようにしたい。
- $n=-1$ の場合分けも勝手にやってくれてすごい。
1 2 3 4 | |
1 2 3 4 5 | |
1 2 3 4 5 | |
$$\int_{0}^{x} x^{n}\, dx$$
1 2 | |
1 2 3 4 5 | |
$$\begin{cases} \log{\left (x \right )} + \infty & \text{for}\: n = -1 \- \frac{0^{n + 1}}{n + 1} + \frac{x^{n + 1}}{n + 1} & \text{otherwise} \end{cases}$$
1 2 | |
1 2 3 4 5 | |
$$\begin{cases} \log{\left (x \right )} + \infty & \text{for}\: n = -1 \\frac{x^{n + 1}}{n + 1} & \text{otherwise} \end{cases}$$
1 2 3 4 | |
微分方程式¶
- フィッツヒュー・南雲方程式
- ホジキン-ハクスレー理論で出てきたモデルの簡略化
- ヤリイカの巨大神経細胞軸索を用いた研究をもとに定式化した神経興奮に関する基礎理論 (Journal of Physiology 117(1952)500-ほか)
- この業績で 1963 年にノーベル賞(生理学医学賞)を受賞
\begin{align} y_{t}&=c\left(y-\frac{y^{3}}{3}-x+I(t)\right),\x_{t}&=y-bx+a. \end{align}
- $I$ は時間の関数で構わないが、以下のシミュレーションでは定数にしている。
- $I$ が 0.34 以上かどうかで解のふるまいが定性的に変わる。
- 力学系の話。
- Colab 上で動画を表示させるところまでできなかったので作った動画は YouTube で:Rust 版動画
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | |
質問メモ¶
- numpy:モジュール名と関数名を「.」でつなぐ
np.array()関数 - クラスとオブジェクトの話。
- じ
シューティングゲーム - 敵の弾(概念):クラス:弾がどこにあるか x,y - 具体的に画面に現れる弾: x=1, y=1
1 2 3 | |
1 | |
1 2 | |
1 | |
1 2 | |
2020-05-10 課題¶
- コンテンツの案内ページ
- GitHub へのリンク
- 曲線を線分で近似できる気分を自分なりに説明してみてください。
- 手書きで絵を描くだけでも構いません。
- 一定のルールにしたがって描かれた曲線を適当な近似的ルールで描くのがプログラミングで描く曲線です。
- 「自分でお絵かきできるようになろう」講座なので、お絵描き用ライブラリに慣れ親しむのが大事です。そこで matplotlib の公式ドキュメントを見ていろいろ遊んでみてください。例えば次のようなことを試してみてください。
- 引き続き TeX でいろいろな式を書いてみましょう。式が書けると数学系のコミュニケーションがだいぶ楽になります。
- 引き続きプログラムをいろいろいじってみましょう. 例えば次のような方針があります. コンテンツからのコピペで構いません. 適切にコピペして動かすだけでも割と大変なので.
- (numpy を使って) いろいろな関数のグラフを描いてみましょう.
- (sympy を使って) いろいろな連立方程式を解いてみましょう. グラフを描くのもおすすめです.
- いろいろな微分方程式を解いてみましょう. 実際にコンテンツでも紹介しているように, 分点を自分でも変えていじってみるとのが第一歩です.
自分用メモ¶
- 常微分方程式で漸化式から微分方程式に流れる部分の書き直し
- 数値計算に関わるクラス・オブジェクトの説明
- まずは辞書・構造体の拡大版として導入するか?
- 変な誤解を生まないような書き方を考える
- 遅延型方程式に対するコメント追加
- import に関する実演
- matplotlib 回では実際に matplotlib のチュートリアルを読もう
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- Jupyter (IPython)でのはまりどころ解説を作ろう
- いったん変数を作ると他のセルでも読み込める(読み込めてしまう)
- 「セルを上から順に読み込まないと動かない」問題の原因
- カーネル再起動まで変数は残り続ける
オブジェクトについて¶
今日は具体的なプログラムというより、今日のメインの話とも少し関係する形でオブジェクトについて少し眺める機会にする。
- オブジェクト指向のオブジェクトの話ではない。
- 必ずしもいつもかっちりした定義のもとに議論されているわけでもない。
- 各プログラミング言語ごとの用語の事情もある。
第一級のオブジェクト¶
第一級オブジェクト(ファーストクラスオブジェクト、first-class object)は、あるプログラミング言語において、たとえば生成、代入、演算、(引数・戻り値としての)受け渡しといったその言語における基本的な操作を制限なしに使用できる対象のことである。
問題になる例:言語によっては関数が第一級のオブジェクトになる。(最近の言語は割とこの傾向があるように思う。) 関数が第一級のオブジェクトの言語では「関数の関数」みたいな概念が考えられる。 高階関数と呼ばれる。
「関数の関数」として python の map を紹介しておく。
python #リスト `lst1` の要素を二倍する lst1 = [1, 2, 3, 4] lst2 = [] for a in lst1: lst2.append(a*2) print(lst2)
1 | |
```python #次のように map で書ける def prod2(a): return a*2
lst1 = [1, 2, 3, 4] lst2 = list(map(prod2, lst1)) #map はイテレーターを返すので list() でリスト化する print(lst2) ```
1 | |
python #参考:ラムダ式 lst1 = [1,2,3,4] lst2 = list(map(lambda x: x*2, lst1)) print(lst2)
1 | |
python #参考:リスト内法表記 lst1 = [1,2,3,4] lst2 = [a*2 for a in lst1] print(lst2)
1 | |
```python lst1 = [1,2,3,4] lst2 = []
lst3 = [1,2,3,4] for a in lst3: lst2.append(a*2) print(lst2) ```
1 | |
```python lst1 = [1,2,3,4] lst2 = []
lst3 = [1,2,3,4]
for a in lst3: lst2.append(a*2) print("") print("")
print(lst2) ```
1 2 3 4 | |
なぜ(Python で)map の返り値がイテレーターか¶
- 巨大なリストを処理する場合、リストが返るとメモリを大量に消費するから。
- この手の話をきちんと考えるにはコンピューターアーキテクチャなり、データ構造なり、プログラミング言語に関する諸々の知識がいる(のでその辺のプログラミング言語入門みたいな本ではふつう出てこない)。
- この手の「入門」は大学の情報科学系の入門書にはきちんと書いてある。
オブジェクトとインスタンス¶
オブジェクト¶
だいたい次のような性質を持っています。 - 何らかの型がある。 - 変数に代入できる。 - 関数(メソッド)の引数にできる。 - 関数(メソッド)の戻り値にできる。 - それ自体が式であり、任意の式の一部になる。
インスタンス¶
これはオブジェクト指向だけの概念です。クラス(プロトタイプベースの場合はプロトタイプとなるオブジェクトになりますが、以下クラスとまとめて考えます)はオブジェクトの雛形です。その雛形から実際のデータをもつオブジェクトにすることを実体化(インスタンス化)と言い、そのオブジェクトはそのクラスのインスタンスと言われます。
python import matplotlib.pyplot as plt fig = plt.figure() #a = A.new()
関数とメソッド¶
言語によっていろいろありはする。
- サブルーチン
- 関数、手続き
- 何らかの処理をまとめたモノ
- 数学の関数とは必ずしも関係ない
- メソッド:メソッド (method) あるいは メンバー関数 (-かんすう, member function) とはオブジェクト指向プログラミング言語において、あるクラスないしインスタンスに所属するサブルーチンを指す。
第一級関数(だいいっきゅうかんすう、英: first-class function、ファーストクラスファンクション)とは、関数を第一級オブジェクトとして扱うことのできるプログラミング言語の性質、またはそのような関数のことである。
```python #値を返す「関数」 def f(): return 1
#値を返さない「関数」 def g(): print(1) g() ```
1 | |
```python class TestClass: x = "変数1"
1 2 3 4 5 6 7 8 9 10 11 | |
a = TestClass("y") print(a.gety())
b = TestClass("b") print(b.gety())
a.test_method1() b.test_method1() ```
1 2 3 4 | |
解答例¶
matplotlib¶
TeX でいろいろな式を書こう¶
python def f(): return {"a": "a"} print(f().keys())
1 | |
いろいろなプログラムを書こう¶
numpy でのグラフ¶
sympy¶
python #colab の場合 from IPython.display import Math, HTML def load_mathjax_in_cell_output(): display(HTML("<script src='https://www.gstatic.com/external_hosted/mathjax/latest/MathJax.js?config=default'></script>")) get_ipython().events.register('pre_run_cell', load_mathjax_in_cell_output)
微分方程式¶
2020-05-17 課題¶
はじめに¶
- コンテンツの案内ページ
- GitHub へのリンク
- 前回使った ipynb のプログラムを実際に実行してみて、実数の数値計算上で起こる問題を実感してみてください。
- 「自分でお絵かきできるようになろう」講座なので、お絵描き用ライブラリに慣れ親しむのが大事です。そこで matplotlib の公式ドキュメントを見ていろいろ遊んでみてください。例えば次のようなことを試してみてください。
- 引き続き TeX でいろいろな式を書いてみましょう。式が書けると数学系のコミュニケーションがだいぶ楽になります。
自分用メモ¶
- 常微分方程式で漸化式から微分方程式に流れる部分の書き直し
- 勉強のおすすめ:AtCoder はどうか?C++の解説もあるし、仕事・評価にも割と直結するし、具体的な問題つきで勉強できる。
- https://atcoder.jp/contests/apg4b
- C++のコードをPythonで書き直してみるだけでもかなりの勉強になるはず
- Python によるアルゴリズム https://qiita.com/cabernet_rock/items/cdd12b07d213b67d0530
- https://atcoder.jp/contests/apg4b
- 数値計算に関わるクラス・オブジェクトの説明
- まずは辞書・構造体の拡大版として導入するか?
- 変な誤解を生まないような書き方を考える
- 遅延型方程式に対するコメント追加
- import に関する実演
- matplotlib のチュートリアルを読もうの会
- matplotlib 回では実際に matplotlib のチュートリアルを読もう
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- Jupyter (IPython)でのはまりどころ解説を作ろう
- いったん変数を作ると他のセルでも読み込める(読み込めてしまう)
- 「セルを上から順に読み込まないと動かない」問題の原因
- カーネル再起動まで変数は残り続ける
プログラミングの一般論¶
イテレーターとジェネレーター¶
- 参考
- この間イテレーターとジェネレーターを勘違いして話してしまったのでやり直し
基本¶
- イテレータ: 要素を反復して取り出すことのできるインタフェース
- 例:リスト、配列、タプル、辞書など
- 「要素をたくさん持っているデータ構造」
- ジェネレータ: イテレータの一種であり、1要素を取り出そうとする度に処理を行い、要素を生成する。Pythonではyield文を使った実装を指すことが多い
- ジェネレーターが必要になる理由
- とりあえずリストを想定する
- 要素すべてをあらかじめ計算しておく/取得してくるのが大変
- 例:何十GBもある巨大なイテレータはメモリにのせられない
- HDD・SSD に載せるのも大変(速度なり何なりいろいろ)
- ふつう 1 つ 1 つの要素自体は小さい
- 要素を 1 つ 1 つ生成すればメモリをそんなに食わない
- 1 つ 1 つ作ろう
1 つ 1 つ作る?¶
rangeがイメージしやすそうな気がする- 一度にドカッとリストを作る必要はなく、1 つ 1 つの整数を都度作ってくればいい
1 2 3 4 | |
1 2 3 4 5 6 7 8 9 10 11 | |
- イテレータ(リスト)の要素数が $10^{1000000}$ くらいになるとそもそもリストが作れない
- 一気に作らずに 1 つずつ要素を生成すれば問題なく処理は回る
- $10^{1000000}$ 個の要素を処理しないといけない点で時間自体はどうしてもかかる
- これは本質的な問題で、ジェネレーターを使う・使わないに関係ない
- メモリに載るか載らないかではなく処理の所要時間の問題
Python のジェネレーターの簡単な例¶
yieldを使ってみる
1 2 3 4 5 6 7 | |
1 | |
1 2 3 4 5 6 7 8 9 | |
1 2 3 | |
- 4 回呼ぶと怒られる
forで呼び出すと怒られるところでループを止めてくれる
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 3 4 5 6 7 8 | |
1 2 3 | |
クラス¶
- 念頭に置くのは Python のクラス・オブジェクト(オブジェクト指向の意味のオブジェクト)
- データとそれを処理する「関数」のペア
- まずは「辞書」または「リスト」の拡張だと思おう
例¶
- ある学生
sのテストの点に関していろいろ統計的な処理をしたい - 学生
sのテストの点を次のようにリストで持つ- 国語・数学・英・理科・社会の順に点数を並べるとする
- 平均点を計算したい
1 2 3 4 5 | |
1 | |
- リストだと何も情報がなくて、何番目が何の科目だったか覚えていられない
- コメントもあるが、何かの都合で仕様が変わったりしたらどうする?
- 具体的に名前で持たせればいい:辞書を使おう
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
1 | |
- 関数
calc_meanは(本質的には)成績の持たせ方と連動した関数である - 値と処理をバラバラにしないでワンセットにしたい:クラス化
- いまは単なる平均だからご利益が何も感じられない
- もっと複雑なことを考えると「ワンセット」にご利益が出てくる
- それこそ「辞書のクラス・メソッド」などを考えてみよう
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1 | |
- ほかの生徒の成績も考えたいとき、簡単に各生徒用のオブジェクトが作れる
- オブジェクトは
s1やs2
- オブジェクトは
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
1 2 | |
アルゴリズムとデータ構造¶
アルゴリズムとデータ構造でプログラミングを勉強する¶
- https://atcoder.jp/?lang=ja
- プログラミングのコンテストサイト
- 競技プログラミング
- C++ の勉強も兼ねた勉強用ページ https://atcoder.jp/contests/APG4b
- 初心者向け練習問題 https://atcoder.jp/contests/abs
- 探せば他にも練習問題特集はある
いいところ¶
- 簡単な問題なら 10 行もあれば書ききれる
- 自分で何か作ったりしなくても問題演習という形でプログラミングに触れられる
- 基本的には実際のプログラミングに即役立つタイプの問題
- ランキング上位者は本当にプログラミングで食っていけるレベルの腕でもある
- 良くも悪くも、コンピューターの基礎みたいな部分に触れざるを得ない面がある
- リストと配列は何が違うのか?
- どういうときにどちらを使えばいいのか?
- メモリ上のデータの配置が違う
- 「低レイヤー」の話とも向き合う必要が出る可能性
自分に合った勉強法・勉強内容を探そう¶
- 最終的な目的・目標と勉強に対する最善のアプローチが一致するとは限らない
- 私の場合は物理・数学系だと勉強しやすかったが、皆が皆そうというわけでもない
- 課題を競プロから出してみて様子を見るか?
2020-05-31 課題¶
はじめに¶
- コンテンツの案内ページ
- GitHub へのリンク
- 01-01 ipynb のプログラムを実際に実行してみて、実数の数値計算上で起こる問題を実感してみてください。
- 「自分でお絵かきできるようになろう」講座なので、お絵描き用ライブラリに慣れ親しむのが大事です。そこで matplotlib の公式ドキュメントを見ていろいろ遊んでみてください。例えば次のようなことを試してみてください。
- 引き続き TeX でいろいろな式を書いてみましょう。式が書けると数学系のコミュニケーションがだいぶ楽になります。
- 実際に競プロの問題をいくつか解いてみましょう。例えばここのページを一通り眺めてみてください。Pythonで10問解いてみた記事もあるので参考にしてください。
自分用メモ¶
- 常微分方程式で漸化式から微分方程式に流れる部分の書き直し
- 勉強のおすすめ:AtCoder はどうか?C++の解説もあるし、仕事・評価にも割と直結するし、具体的な問題つきで勉強できる。
- https://atcoder.jp/contests/apg4b
- C++のコードをPythonで書き直してみるだけでもかなりの勉強になるはず
- Python によるアルゴリズム https://qiita.com/cabernet_rock/items/cdd12b07d213b67d0530
- https://atcoder.jp/contests/apg4b
- 文と式の説明
- IT 基礎知識みたいなやつ
- 数値計算に関わるクラス・オブジェクトの説明
- まずは辞書・構造体の拡大版として導入するか?
- 変な誤解を生まないような書き方を考える
- 遅延型方程式に対するコメント追加
- import に関する実演
- matplotlib のチュートリアルを読もうの会
- matplotlib 回では実際に matplotlib のチュートリアルを読もう
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- Jupyter (IPython)でのはまりどころ解説を作ろう
- いったん変数を作ると他のセルでも読み込める(読み込めてしまう)
- 「セルを上から順に読み込まないと動かない」問題の原因
- カーネル再起動まで変数は残り続ける
競プロを 2 題解いてみる¶
- https://qiita.com/KoyanagiHitoshi/items/c5e82841b8d0f750851d の最初の2題
ABC 086 A - Product¶
- 標準入力から取るのが本筋(
input) - 面倒なのでここでは入力部分をハードコードする
```python input_str = "1 3"
print("input_str") print(input_str)
print("======") print(input_str.split())
print("======") print(map(int, input_str.split()))
print("======") print(list(map(int, input_str.split())))
a, b = map(int, input_str.split()) print(a) print(b)
######################## a, b = map(int, input_str.split()) if a*b % 2 == 0: print("Even") else: print("Odd") ```
1 2 3 4 5 6 7 8 9 10 11 | |
python s = "1" print(s) print(type(s)) print(int(s)) print(type(int(s)))
1 2 3 4 | |
map オブジェクトはイテレーター¶
python input_str = "1 3" a = map(int, input_str.split()) print(a.__next__()) print(a.__next__()) print(a.__next__())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
参考:標準入力¶
- 果てしなくめんどい
- 低レイヤーの話に突撃する:コンソール・ターミナル、リダイレクトなどなど
- 「特殊 ( スペシャル ) ファイル」
- 「ソケット」
- http://e-words.jp/w/%E3%82%BD%E3%82%B1%E3%83%83%E3%83%88.html
- 特定の通信相手(IPネットワーク上の場合はIPアドレスとポートの組み合わせ)と紐付いた通信端点をプログラム上に生成し、これを通じてコネクションの確立やデータの送受信、切断などの処理を行う。具体的な通信方式や通信相手の指定方式が複数用意されており、同じコンピュータ上の他のプロセスとも、TCP/IPなどを利用して他のコンピュータ上のプログラムとも通信できる。
- 標準入力について参考ページ
- 低レイヤーとは何か
- 参考
- 「低レイヤーとは 「生の」コンピュータに近いことを意味します。」
- OS やら CPU やらメモリやら何やら
- 「ハードウェアに近い話」みたいにも言えるかもしれない
- 簡単とか世間的な意味での「低レベル」とは関係ない
- 参考:「高レイヤー」は Web アプリなど
- 参考:OSI 7階層参照モデル
- この辺は基本情報技術者試験などで「基礎知識」として問われたりする
第二問 ABC 081 A - Placing Marbles¶
- 文字列は文字からなるリスト(配列)とみなす
count()の説明は例えばここ- 解説が何を言っているかよくわからないこともよくある
- サンプルをいくつか動かす方が早いこともよくある
- 数学でもよくある:一般論・抽象論ばかりではなく例をいじろう
python input_str = "101" print(input_str.count("1"))
1 | |
python input_str = "abcabcab" print(input_str.count("a"))
1 | |
python input_str = "abcabcab" print(input_str.count("abc"))
1 | |
プログラミングの一般論¶
インポートまわりの話¶
- 「お行儀」の問題もいろいろある。
- コーディングルールとして言及されることはよくある。
- たくさん読み書きしてはじめてわかることもある。
- ある程度の量はこなさないと見えない世界がある
初心者にありがちな話:モジュールの内容を全部インポートする¶
- 「いちいち必要なのだけ選ぶのはめんどい」
- 「楽でいいじゃない」
python from sympy import * from numpy import * x,y,z = symbols("x,y,z")
問題点¶
- 知らないモジュールのインポートがたくさんあると、どのクラス・関数がどのモジュールから来ているのかわからない
- 似た名前の関数やクラスなどもたくさんある
- 他人も読むコードではやめてほしい
- 将来、詳細を忘れた自分が読むのも厳しい
- 「わけがわからないので、使うクラスや関数だけインポートしてほしい」
- 例:使うものだけインポート
- https://github.com/django/django/blob/master/django/middleware/cache.py#L48-L50
- 例:使うものだけインポート
- 「使うクラス・メソッドだけインポートするか、
asで呼ぶかする」といった規約をつけていることもよくある- sympy, numpy あたりはお行儀がよくて、必要なモノだけインポートするよう徹底されている模様
python import numpy as np import matplotlib.pyplot as plt
いろいろなインポートの指定¶
- 状況に合わせて都合がいいからそうする
- 状況に合わせた方法もいろいろ準備されている
- 必要だったから体系化されて盛り込まれている
python from fractions import Fraction q = Fraction(3,4) print(q)
1 | |
python import fractions r = fractions.Fraction(3,4) print(r)
1 | |
- 内容は同じだが後者は長い
- 書くのが面倒
- 読むときも余計なものまで読まされる
- シンプルにしたい
- ケースバイケースでいろいろやる
- クラスだけ直接インポート:
from fractions import Fraction asで短くする:import fractions as f
- クラスだけ直接インポート:
python import fractions as f a = f.Fraction(3,4) print(a)
1 | |
python from numpy import * linspace(0, 10, 11)
1 | |
python import numpy numpy.linspace(0, 10, 11)
1 | |
全体像をつかもう¶
- ある程度大きな姿を捕まえないと局所的に何をやっているかもわからないことはよくある
- 料理でも下ごしらえとか
- 「やらなくてもいいが、やらないと美味しくない」
- フグの調理で毒を避けて処理する
- 「死にたいならやればいい」
- 料理でも下ごしらえとか
- 知識や見えている範囲が狭い中で考えて判断しようとしても無駄なことはよくある
- 意味がわかるかはさておき、ある程度たくさん知っておかないといけないことはよくある
- 単純な知識問題もよくある
- はまることや立ち止まることに意味がない
- 何かを調べたいとき、対応する言葉を知らないと調べようがなければ聞きようもない
- 単純な知識問題もよくある
- 本を読んでいるなら、とにかく四の五の言わずに 2-3 週読んでみるとかした方がいいこともよくある
- プログラミングはちょっと突っ込むだけでいきなりコンピューター関係の基礎知識を大量に要求されるので、さっさと諦めてそれらを勉強する
- 基礎からやったところですぐにわかるようになるわけもないが、それらを諦めるところまで込めて諦める
膨大な量の経験が大事¶
- 経験を積むと「こうした方がいい」「これはやめてほしい」というのがいろいろたまってくる
- コーディングルールとしてノウハウがまとまっていたりする
- 数学でもε-δで「なぜこんなεを取るのか」みたいな話はよくあるし、「何でこんな概念を導入するのか」みたいな話はよくある。
- 「便利だから」とか言われてもその便利なところを実感できるのはだいぶ慣れ親しんでから。
- この苦労を経ないとその辺の意味やご利益もわからないことはよくある
- プログラミングでも同じ
- ある程度は量をこなそう
楽しく量をこなすには?¶
- 楽しいと思えることを探すしかない
- 何が楽しいかは自分しかわからない
- はじめつまらなくてもやっているうちに楽しくなることもあれば、何かのきっかけで目覚めることもある
- いい方向が見つかるまでは試行錯誤するしかない
- この中で自然と頭を使いつつ(質を高めつつ)量もこなす必要が出てくる
2020-06-14 課題¶
- コンテンツの案内ページ
- GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。まずは Beginners' selection をやっていきます。
- 今回は ABC081B と ABC086C (最後の難しめの問題)をやってみましょう。
- Pythonで10問解いてみた記事もあるので参考にしてください。
- 他にもここのページを一通り眺めてみてください。
自分用メモ¶
- 常微分方程式で漸化式から微分方程式に流れる部分の書き直し
- 勉強のおすすめ:AtCoder はどうか?C++の解説もあるし、仕事・評価にも割と直結するし、具体的な問題つきで勉強できる。
- https://atcoder.jp/contests/apg4b
- C++のコードをPythonで書き直してみるだけでもかなりの勉強になるはず
- Python によるアルゴリズム https://qiita.com/cabernet_rock/items/cdd12b07d213b67d0530
- https://atcoder.jp/contests/apg4b
- 文と式の説明
- IT 基礎知識みたいなやつ
- 数値計算に関わるクラス・オブジェクトの説明
- まずは辞書・構造体の拡大版として導入するか?
- 変な誤解を生まないような書き方を考える
- 遅延型方程式に対するコメント追加
- import に関する実演
- matplotlib のチュートリアルを読もうの会
- matplotlib 回では実際に matplotlib のチュートリアルを読もう
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- Jupyter (IPython)でのはまりどころ解説を作ろう
- いったん変数を作ると他のセルでも読み込める(読み込めてしまう)
- 「セルを上から順に読み込まないと動かない」問題の原因
- カーネル再起動まで変数は残り続ける
Matplotlib¶
- とりあえず本当に簡単な図を描く
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
1 | |
勉強ネタ紹介¶
- 前回も言ったように、自分に合った、楽しめるネタを探す必要がある
- 勉強しなければいけないことと、やっていて楽しめること・長続きすることが一致しないこともよくある
- 教材がある事案
- 統計学 100 本ノック系:本もある
- 自然言語処理 100 本ノック系:例えばこのページ
- 離散数学:The Haskell Road To Logic, Maths And Programming
- Project Euler
- 最近の私の趣味と実益を兼ねた対象がデータ構造とアルゴリズムなので、ここでもその辺を試してみている
- 例えば上の中でも興味のあるネタがあればそれは取り上げるので、要望があれば挙げてほしい。
- 自然言語処理の UNIX コマンドとか
競プロを 2 題解いてみる¶
- https://qiita.com/KoyanagiHitoshi/items/c5e82841b8d0f750851d の 3 題目と最後の問題
- AOJ も勉強用にお勧め
- 素因数分解など数学ネタもある
- これをもとにした本もある
- 言語が C/C++ なのが難点といえば難点
- C/C++ の方が低レイヤーを意識しやすくなる利点はある
- 最近は Python によるデータ構造とアルゴリズムの本も出ているし、ネット上に資料もある
ABC081B、Shift only¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
1 2 3 | |
Python の all¶
Pythonでリストやタプルなどのイテラブルオブジェクトの要素がすべてTrue(真)か、いずれか一つでもTrueか、あるいは、すべてFalse(偽)かを判定するには組み込み関数all(), any()を使う。
1 2 | |
1 2 | |
ABC086C、Traveling¶
- 止まれない条件
- 止まってよければ問題は簡単:時間に関する制約だけでいい
- 非現実的な問題設定にしたおかげで難しくなっている
- cf. たいていの場合は現実が難しすぎるから簡単にした問題を解く
- 「距離」
- 京都・札幌・マンハッタンのような碁盤目状に道が整備された街での 2 点間の距離をどう測るといいか?
- 普通の2点間の距離(ユークリッド距離)$\sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2}$ では不適切。
- $|x_1 - x_2| + |x_1 - x_2|$ で測る方が適切。
- 機械学習でも $L^1$ 正則化などで出てくる。
- 情報系(?)だとマンハッタン距離と呼ぶ。
- 数学では $L^1$ ノルムと呼ぶ。
- 一般には $L^p$ ノルムという概念がある
- 京都・札幌・マンハッタンのような碁盤目状に道が整備された街での 2 点間の距離をどう測るといいか?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
1 2 3 | |
1 2 3 4 5 6 7 8 | |
現実的なスケジューリングの問題¶
- Google Map の経路探索
- Yahoo 路線情報などの経路探索
- 野球・サッカーなどの年間試合日程
- PASMO などでの運賃清算
PASMO などの運賃計算¶
- 論文が出るほどの問題
- 解説記事
- https://www.orsj.or.jp/~archive/pdf/j_mag/Vol.54_J_001.pdf
- https://www.seikei.ac.jp/university/rikou/pdf/JFST440213.pdf
- https://ci.nii.ac.jp/naid/110008913789
- 何が難しいか:乗車情報を使って東京の複雑な路線図から「最安運賃」を即座に計算させる
- 使える時間は 0.2 秒
- 運賃が高く計算されたら怒られる
- 安ければ文句がでない
- いくらでも変な経路がありうる
- 余計な枝をはじいて重要な部分だけ計算する
- どうやって:これがアルゴリズム研究
- ほぼ純粋なプログラムだけの問題
- テストの視点
- どんな始点・終点であっても問題なく動くか、プログラムを検証する問題もある
- 検証すべきパターンは $10^{40}$ 程度あるとか:解説記事
プロスポーツのスケジュール決定¶
- OR の研究課題
- 多数のステークホルダーの利害調整問題
- ドームなどはコンサートもある
- 著名アイドル・歌手の結成何周年イベントなどは「この時期、できれば第何週」というレベルで細かい指定が入る
- ドル箱はもちろん優先
- 春夏の甲子園の時期は高校野球に占拠される
- 各チームが過酷な移動スケジュールにならないような配慮
- 「九州から北海道に順に移動していき、逆順に移動していく」みたいな形だと移動の負担は少ない
- 必ずしもそううまくは組めない
- 長時間移動だけでも体力消費があり選手パフォーマンスに影響する
- 旅費もかさむ
- ドームなどはコンサートもある
- どうするか?
- これも組み合わせは膨大で、電車ほど激しくはないが短時間で計算させたい
- 最終的には人間の目も入れる必要があるだろう
- コンピューターにいくつか候補を計算させたい
- 適当にイベントと時期に重みづけ(ペナルティ)をつけて「一定程度以上ペナルティが積まれたスケジュールはもう考えない」といった工夫がいる
- いい感じのスケジュールにならなければパラメータ調整して再計算させたい
- このサイクルはなるべく早く回したい
- 高速計算の需要
- この辺は最近はやりの機械学習でもまさに同じような事情がある
プログラミングの一般論¶
- Web システムを例にした速度問題
- データ構造とアルゴリズム
- 連結リストと配列:どんな特性があるか?
- スタックとキュー:いつどこで使うか?どう実装するか?
web システムの事例¶
- 参考
- システムが重いというときどこにどんな原因があるか?
- ソシャゲでもよくある「障害発生」はどこでどう起こるか?
- どこかのサーバーが物理的に壊れることもある
- データ構造とアルゴリズム(いわゆる「プログラミング」)がかかわるのはどこか?
- web サーバーでの処理(プログラム)
- データベースの(インデックス)設計
- ソフトによる問題なら基本的にはどこにでもありうる
データ構造とアルゴリズム¶
- 鶏と卵で、同時に考えるべきテーマ:何かをするためにはどうデータを持ってどんな処理をすれば効率がいいか?
- 効率にもいろいろある
- 単純な処理速度・メモリ消費量・計算量
(連結)リストと配列¶
- 何が違うのか?
- メモリ上の配置やデータの「つなぎ方」
- 状況によって使い分ける
リストの特徴¶
- 要素数は変わることが前提
- データを(先頭に)追加するのは簡単
- データの削除も比較的簡単
- 先頭から 1 つずつ順に処理するならそれなり
- 検索やデータの書き換えが遅い:連結構造をたどる必要がある
配列の特徴¶
- 要素数は固定
- データの追加・削除が重め
- データの参照・書き換えが速い:アドレスが連続なので先頭さえわかれば「そこから何番先」と直指定できる
- 「リストで遅ければ配列で書き直す」みたいなことはよくある
ベクター(参考)¶
- 「要素数可変の配列」
- リストのように要素追加・削除が比較的低コストで、要素の参照・書き換えも配列のように速い
- 何が問題か:要素の追加が楽なように余計なメモリ領域を確保する
- ハードウェア組み込みプログラムのように、メモリがカツカツの状況では使えない
- 「メモリがカツカツ」という意味が理解できるか?
2020-06-20 課題¶
- コンテンツの案内ページ
- GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。まずは Beginners' selection をやっていきます。
- 今回は ABC087B と ABC083B です。
- Pythonで10問解いてみた記事もあるので参考にしてください。
- 他にもここのページを一通り眺めてみてください。
メモ:先に進む前に録画してあるか確認しよう¶
自分用メモ¶
- 常微分方程式で漸化式から微分方程式に流れる部分の書き直し
- 勉強のおすすめ:AtCoder はどうか?C++の解説もあるし、仕事・評価にも割と直結するし、具体的な問題つきで勉強できる。
- https://atcoder.jp/contests/apg4b
- C++のコードをPythonで書き直してみるだけでもかなりの勉強になるはず
- Python によるアルゴリズム https://qiita.com/cabernet_rock/items/cdd12b07d213b67d0530
- https://atcoder.jp/contests/apg4b
- 文と式の説明
- IT 基礎知識みたいなやつ
- 数値計算に関わるクラス・オブジェクトの説明
- まずは辞書・構造体の拡大版として導入するか?
- 変な誤解を生まないような書き方を考える
- 遅延型方程式に対するコメント追加
- import に関する実演
- matplotlib のチュートリアルを読もうの会
- matplotlib 回では実際に matplotlib のチュートリアルを読もう
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- Jupyter (IPython)でのはまりどころ解説を作ろう
- いったん変数を作ると他のセルでも読み込める(読み込めてしまう)
- 「セルを上から順に読み込まないと動かない」問題の原因
- カーネル再起動まで変数は残り続ける
Matplotlib¶
- とりあえず本当に簡単な図を描く
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
自然言語処理100本ノック¶
- この間紹介したらやってみたくなったので、(勉強会の課題ネタ競プロを放棄して眺めてみた)
- URL: 言語処理100本ノック 2020 (Rev 1)
- 文字列に限定した競プロの趣もある
第1章: 準備運動 00. 文字列の逆順¶
文字列"stressed"の文字を逆に(末尾から先頭に向かって)並べた文字列を得よ.
1 2 | |
1 2 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
第1章: 準備運動 01. 「パタトクカシーー」¶
- 「パタトクカシーー」という文字列の1,3,5,7文字目を取り出して連結した文字列を得よ.
1 | |
1 | |
1 | |
1 | |
02. 「パトカー」+「タクシー」=「パタトクカシーー」¶
「パトカー」+「タクシー」の文字を先頭から交互に連結して文字列「パタトクカシーー」を得よ.
1 2 3 4 5 6 7 8 9 10 11 12 | |
1 2 3 4 5 6 | |
03 円周率¶
"Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics."という文を単語に分解し,各単語の(アルファベットの)文字数を先頭から出現順に並べたリストを作成せよ.
1 2 | |
1 | |
1 2 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
1 2 | |
1 | |
1 2 3 4 5 6 7 8 9 10 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
04. 元素記号¶
"Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can."という文を単語に分解し,1, 5, 6, 7, 8, 9, 15, 16, 19番目の単語は先頭の1文字,それ以外の単語は先頭の2文字を取り出し,取り出した文字列から単語の位置(先頭から何番目の単語か)への連想配列(辞書型もしくはマップ型)を作成せよ.
(言っていることがよくわからなくて何度も読み返した。)
1 2 3 4 5 6 7 8 9 | |
1 | |
1 2 3 4 5 | |
内包表記をループで書き直した¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | |
プログラミングの一般論¶
- Web システムを例にした速度問題
- データ構造とアルゴリズム
- 連結リストと配列:どんな特性があるか?
- スタックとキュー:いつどこで使うか?どう実装するか?
web システムの事例¶
- 参考
- システムが重いというときどこにどんな原因があるか?
- ソシャゲでもよくある「障害発生」はどこでどう起こるか?
- どこかのサーバーが物理的に壊れることもある
- データ構造とアルゴリズム(いわゆる「プログラミング」)がかかわるのはどこか?
- web サーバーでの処理(プログラム)
- データベースの(インデックス)設計
- ソフトによる問題なら基本的にはどこにでもありうる
データ構造とアルゴリズム¶
- 鶏と卵で、同時に考えるべきテーマ:何かをするためにはどうデータを持ってどんな処理をすれば効率がいいか?
- 効率にもいろいろある
- 単純な処理速度・メモリ消費量・計算量
(連結)リストと配列¶
- 何が違うのか?
- メモリ上の配置やデータの「つなぎ方」
- 状況によって使い分ける
リストの特徴¶
- 要素数は変わることが前提
- データを(先頭に)追加するのは簡単
- データの削除も比較的簡単
- 先頭から 1 つずつ順に処理するならそれなり
- 検索やデータの書き換えが遅い:連結構造をたどる必要がある
配列の特徴¶
- 要素数は固定
- データの追加・削除が重め
- データの参照・書き換えが速い:アドレスが連続なので先頭さえわかれば「そこから何番先」と直指定できる
- 「リストで遅ければ配列で書き直す」みたいなことはよくある
ベクター(参考)¶
- 「要素数可変の配列」
- リストのように要素追加・削除が比較的低コストで、要素の参照・書き換えも配列のように速い
- 何が問題か:要素の追加が楽なように余計なメモリ領域を確保する
- ハードウェア組み込みプログラムのように、メモリがカツカツの状況では使えない
- 「メモリがカツカツ」という意味が理解できるか?
2020-06-28 課題¶
- コンテンツの案内ページ
- GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- URL: 言語処理100本ノック 2020 (Rev 1)で Unix コマンドと正規表現のところを眺めてみましょう。適当にいくつかやります。
- (次回以降で対応)実際に競プロの問題をいくつか解いてみましょう。まずは Beginners' selection をやっていきます。
- 今回は ABC087B と ABC083B です。
- Pythonで10問解いてみた記事もあるので参考にしてください。
- 他にもここのページを一通り眺めてみてください。
メモ:先に進む前に録画してあるか確認しよう¶
- メモ:東大の AWS クラウド講義資料
- https://tomomano.gitlab.io/intro-aws/#_hands_on_5_bashoutter
- これを眺めてみるのもいいかもしれない
自分用メモ¶
- 常微分方程式で漸化式から微分方程式に流れる部分の書き直し
- 勉強のおすすめ:AtCoder はどうか?C++の解説もあるし、仕事・評価にも割と直結するし、具体的な問題つきで勉強できる。
- https://atcoder.jp/contests/apg4b
- C++のコードをPythonで書き直してみるだけでもかなりの勉強になるはず
- Python によるアルゴリズム https://qiita.com/cabernet_rock/items/cdd12b07d213b67d0530
- https://atcoder.jp/contests/apg4b
- 文と式の説明
- IT 基礎知識みたいなやつ
- 数値計算に関わるクラス・オブジェクトの説明
- まずは辞書・構造体の拡大版として導入するか?
- 変な誤解を生まないような書き方を考える
- 遅延型方程式に対するコメント追加
- import に関する実演
- matplotlib のチュートリアルを読もうの会
- matplotlib 回では実際に matplotlib のチュートリアルを読もう
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- Jupyter (IPython)でのはまりどころ解説を作ろう
- いったん変数を作ると他のセルでも読み込める(読み込めてしまう)
- 「セルを上から順に読み込まないと動かない」問題の原因
- カーネル再起動まで変数は残り続ける
Matplotlib¶
- とりあえず本当に簡単な図を描く
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
TeX の記録¶
量子力学の1粒子ハミルトニアン。 \begin{align} \hat{H} = \frac{1}{2m} \hat{p}^2 + V(x). \end{align}
自然言語処理100本ノック¶
- この間紹介したらやってみたくなったので、(勉強会の課題ネタ競プロを放棄して眺めてみた)
- URL: 言語処理100本ノック 2020 (Rev 1)
- 文字列に限定した競プロの趣もある
第2章 Unix コマンド¶
- 要検討:ローカルでやった方がデモンストレーションとしてはいいかもしれない
- 参考ページ
- ここでは
pandasを使っている - これはこれで覚えると便利
- Excel が処理できる
- ここでは
- Google Colab 上では
!lsのように!をつけると Unix (Linux) コマンドが実行できる。 - Mac ならターミナルから直接実行できる
- Windows でも適当な手段でインストールできる
- ただし OS の違いから純粋な Windows では意味を持たないコマンドもある
- chown や chmod などの権限管理とか
- すさまじく大量にあり、各コマンドはオプションも死ぬほどたくさんある。
- 毎日ゴリゴリに使い込まければ覚えられるものではない。
- 大事なコマンドをいくつか見て慣れ親しむことだけが目的。
補足¶
- cd, ls などの(もっと)基本的なコマンドはカバーされていない。
- 参考リスト:とりあえずこのくらい知っておくといい(名前だけ何となく覚えていればいい)
- Python にも対応する関数がある
- mv は shutil.move: https://note.nkmk.me/python-shutil-move/
- shutil はたぶん shell utilities の略
- Ruby だと「わかりやすさ」を考えて Linux コマンドと同じ名前の関数・メソッドで定義されている
- cf. chown
準備¶
1 | |
1 2 3 4 5 6 7 8 9 10 | |
1 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
10. 行数のカウント¶
行数をカウントせよ.確認にはwcコマンドを用いよ.
1 | |
1 | |
1 2 3 4 | |
1 | |
補足:wc コマンドの調査¶
- 参考
- 実際にターミナルで実演してみよう
11. タブをスペースに置換¶
タブ1文字につきスペース1文字に置換せよ.確認にはsedコマンド,trコマンド,もしくはexpandコマンドを用いよ.
1 | |
1 2 3 4 5 | |
s/何とか/実はこう書きたかった/
1 | |
1 2 3 4 5 | |
12. 1列目をcol1.txtに,2列目をcol2.txtに保存¶
各行の1列目だけを抜き出したものをcol1.txtに,2列目だけを抜き出したものをcol2.txtとしてファイルに保存せよ.確認にはcutコマンドを用いよ.
Linux コマンド¶
1 2 3 4 5 | |
1 2 3 4 5 6 7 8 9 10 | |
Python¶
1 2 3 4 5 6 7 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
第 3 章 正規表現¶
正規表現の簡単な話¶
- 分厚い本が何冊も出るくらいのごつい話
- 例:「イギリス」という言葉が出てくる文章を調べたい
- 単なる検索でいい
- 例:「イギリス+単語」という言葉が出てくる文章を、その単語セットとともに調べたい。
- 例えばイギリスではなく「イギリス連邦」「イギリスの勝利」のような形で調べたい
- ここで正規表現が出てくる
- もう少し web でよくある例
- メールアドレスのバリデーション
- 「メインの文字列@gmail.com」みたいなのをチェックする
- メンテナンスが魔界
- 正規表現は死ぬほど複雑で簡単な部類でさえすでに読みにくい
- 複雑なものは本当に何もわからない
- 時間が経つと書いた当人でさえ判別できないことはよくある
ファイル取得¶
1 | |
1 2 3 4 5 6 7 8 9 10 | |
展開(解凍)¶
1 | |
行数確認¶
1 | |
1 | |
先頭行の確認¶
1 | |
1 | |
20. JSON データの読み込み¶
Wikipedia記事のJSONファイルを読み込み,「イギリス」に関する記事本文を表示せよ.問題21-29では,ここで抽出した記事本文に対して実行せよ.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 | |
21. カテゴリ名を含む行を抽出¶
記事中でカテゴリ名を宣言している行を抽出せよ.
^はデフォルトでは文字列全体の先頭にのみマッチ- 今回はすべての行をチェックしたい
- MULTILINEオプションで
^を各行の先頭にマッチさせる
1 2 3 4 5 | |
1 2 3 4 5 6 7 8 9 | |
22. カテゴリ名の抽出¶
記事のカテゴリ名を(行単位ではなく名前で)抽出せよ.
- 一部のカテゴリ名に含まれる「カテゴリ名|記号」の|以降を拾わないようにするしたい。
- カッコ内の正規表現にマッチはするが拾ってはこない
?:...を使う
1 2 3 | |
1 2 3 4 5 6 7 8 9 | |
IT 一般論¶
- シンプルなシステムからの成長
- ハード構成の基礎:CPU・メモリ・HDD、キャッシュ
- データ構造とアルゴリズム
- 連結リストと配列:どんな特性があるか?
- スタックとキュー:いつどこで使うか?どう実装するか?
1 2 3 | |
そもそもなぜ IT 一般論の話をしだしたか¶
- データ構造の話をするため
- メモリの話をしないとリストと配列(とベクター)の違いが説明できない
- 一言でいうと、リストと配列はメモリ上にどうデータを置くかが違う
- データの置き方によってデータアクセスの仕方が変わり、「何が得意か」が変わる
- リスト:要素の追加・削除に都合がいいが、ランダムアクセスと値の更新処理に弱い
- 配列:要素の追加・削除は不便だが、ランダムアクセスと値の更新処理に強い
- ベクター:要素の追加・削除に比較的強く、ランダムアクセスと値の更新処理も強い
- 単純にベクターだけ使っていればいいわけでもない:メモリ効率という観点
- メモリ単独の話をしても多分わからない
- 統計学がらみの話は割とすぐにパフォーマンス(速度)の話になる
- いわゆるビッグデータというやつで、大量のデータを何回も計算しないといけない
- 計算を速くしないとやっていられない
- GPU 使うなり何なり割とすぐにハード面の話が出てくる
シンプルなシステムからの成長¶
- 適当な Web システムを考える。
- 具体的にはショッピングサイトなどをイメージすればいい。
- 何を考えても大きくは変わらない話をする。
- サーバー構成やインフラ設計という言葉で調べると色々出てくる
- サーバー構成の画像:Google 画像検索
大事で面倒な話:「サーバー」とは何か?¶
- 何でもいいが、とりあえず一つ参考ページ
- 物理的なモノとソフトウェア両方ある
- 1 つの物理的なサーバーの中に複数のソフトウェアとしてのサーバーが入っていることがある
- 小規模システムならよくある
- 仮想化・コンテナみたいな話をしだすともっと面倒なことになる
- 今回も多少は詳細化するが、まずは「一度は聞いたことがある」レベルにするのが目的。
{kind=link}
基本構成¶
- ソフトウェアとしてのサーバーが 3 つ
- 基本的な構成の画像
- Web サーバー
- アプリケーションサーバー
- データベースサーバー
- Web サーバー:Apache・Nginx:単純に HTML を返すサーバー
- アプリケーションサーバー:いわゆる「アプリケーション」。プログラマーがプログラムを書く部分で、ログインユーザーごとに処理が分かれるとか。最終的に Web サーバーがクライアントに返す HTML の形でデータをまとめる。もちろんここでデータベースのアクセスもある。
- データベースサーバー:顧客情報や製品情報を持っている。
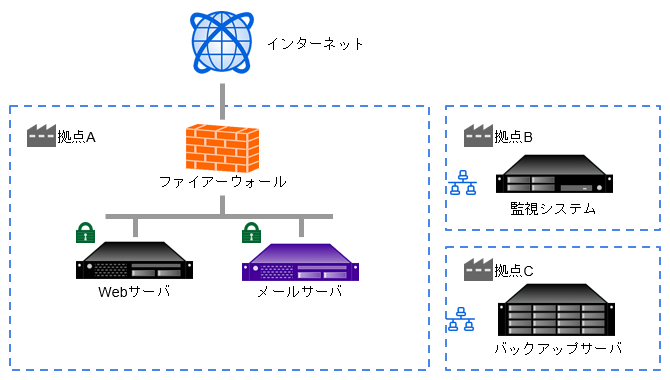{kind=link}
一番単純¶
- 物理サーバーは 1 つ
- ソフトウェアとしての Web サーバー・アプリケーションサーバー・データベースサーバーが載っている。
- 開発者が開発するときは実際にこういう状況で開発している(こともある)
状況に応じていろいろ分かれる¶
- 例えば実際にシステムにかかる負荷によって変わる
- データベースの負荷が高い
- 物理サーバーを追加してデータベースサーバーをそちらに載せ替える。
- Web のリクエストがさばききれないとき
- Web サーバーを切り分けた上で 2 台にわける
- アプリケーションサーバー・データベースサーバーは 1 つの物理サーバーに載せる。
他の状況¶
- データベースの読み込み負荷が高い:Memcache や Redis のようなキャッシュサーバーを(物理サーバーごと)追加する。
- セキュリティが気になってきた:Web サーバーの前にセキュリティ用のファイアーウォール
- セキュリティが絡むとサーバー構成がまた複雑になる。
- 上記画像参考
- 直接外とやり取りするところに外部向けファイアーウォール
- DMZ の中で外部とやり取りするサーバーが置かれる:いわゆるアプリケーションサーバー
- アプリケーションサーバーと「内部」がやり取りするところにまたファイアウォールを置く
- 「内部」というのは顧客データベースなどの社外に公開しないサーバー
- ファイアウォールを二重に置くことで、絶対に触ってはいけないところに対して二重の防御を敷く
- 外部公開しているサーバーがクラックされても内部にアクセスできないようにする
- 内部から危険な情報を外に出せないようにする
{kind=link}
ハードウェア構成の基礎¶
- CPU、キャッシュ(キャッシュメモリ)、メモリ、HDD・SSD、キーボード・マウスくらいまでの大まかな話
コンピューター構成の5大要素¶
- 参考
- 制御装置:各装置を制御。担当は CPU
- 人間でいうと脳やせき髄
- 演算装置:データを処理。担当は CPU
- 人間でいうと脳
- 記憶装置:データを保存。担当はメモリ・ハードディスク・SSD
- 人間でいうと脳(短期記憶)、「机」、「本棚」
- それぞれの「記憶装置」に意味がある
- 短期記憶は容量が小さいが高速に計算に回せる
- 机は本が置けて、データを本棚に取りに行く手間は省ける分だけ速い
- 本棚は取りに行くのは大変だが、たくさんモノが置ける
- 入力装置:データを受けつける。担当はキーボード・マウスなど
- 出力装置:データや処理の結果を外に出す。ディスプレイ・プリンタ等
CPU からキャッシュ¶
- 参考の図
- CPU もコアという概念がある
- 最近の分散コンピューティングで重要な要素
- 「コロナの解析のためにあなたのマシンパワーを貸してください」
- 「ブロックチェーン・ビットコインの計算をさせていた」
- 参考ページ
- レジスターやら何やら細かく見ていくといろいろある
複数のキャッシュレベル¶
- 前にやったレイテンシー比較
- 計算速度からの重要性
- 「暗算できれば一番速い」
- どれだけキャッシュで処理できるかが勝負
- 数値計算でも大事
- データベースでも大事
- キャッシュの話いろいろ
- 計算速度からの重要性
- 参考ページ:なぜCPUにはL1・L2・L3というように複数のキャッシュレベルがあるのか?
「それぞれのキャッシュには役割があるから」
「キャッシュは容量が大きいほどデータ転送速度が遅く、記憶密度が高く、省電力という性質を持つため、必要性に応じて異なる種類のキャッシュを使い分けるのが有利だから」
補足:キャッシュ¶
- キャッシュはいろいろなところにある
- webシステムでのメモリデータベース(メモリキャッシュ)
- データベースを使うときのデータベースサーバーでのメモリキャッシュ(Redis などのメモリデータベースのキャッシュとはまた違う)
- ブラウザのキャッシュ:一度読み込んだwebサイトのデータを取っておいて次に読み込むときのロードを速くする
- ブラウザのキャッシュについては、「ブラウザが重くなった時」などで調べると「キャッシュを削除しよう」みたいな話が出てくる。
- cf. このページ
- 「GoogleのWebブラウザ「Chrome(クローム)」が重いときに考えられる原因には、キャッシュや履歴などの問題が考えられます。」
- cf. このページ
データ構造とアルゴリズム¶
- 鶏と卵で、同時に考えるべきテーマ:何かをするためにはどうデータを持ってどんな処理をすれば効率がいいか?
- 効率にもいろいろある
- 単純な処理速度・メモリ消費量・計算量
(連結)リストと配列¶
- 何が違うのか?
- メモリ上の配置やデータの「つなぎ方」
- 状況によって使い分ける
リストの特徴¶
- 要素数は変わることが前提
- データを(先頭に)追加するのは簡単
- データの削除も比較的簡単
- 先頭から 1 つずつ順に処理するならそれなり
- 検索やデータの書き換えが遅い:連結構造をたどる必要がある
配列の特徴¶
- 要素数は固定
- データの追加・削除が重め
- データの参照・書き換えが速い:アドレスが連続なので先頭さえわかれば「そこから何番先」と直指定できる
- 「リストで遅ければ配列で書き直す」みたいなことはよくある
ベクター(参考)¶
- 「要素数可変の配列」
- F# だと ResizeArray
- リストのように要素追加・削除が比較的低コストで、要素の参照・書き換えも配列のように速い
- 何が問題か:要素の追加が楽なように余計なメモリ領域を確保する
- ハードウェア組み込みプログラムのように、メモリがカツカツの状況では使えない
- 「メモリがカツカツ」という意味が理解できるか?
2020-07-12 課題¶
- コンテンツの案内ページ
- GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。まずは Beginners' selection をやっていきます。
- 今回は ABC087B と ABC083B です。
- Pythonで10問解いてみた記事もあるので参考にしてください。
- 他にもここのページを一通り眺めてみてください。
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。
- 自分の宿題(気になるので調べる)
- SSD の話:記憶の仕方、書き込み耐性
- HDD の最小単位
メモ:先に進む前に録画してあるか確認しよう¶
自分用メモ¶
- 勉強のおすすめ:AtCoder はどうか?C++の解説もあるし、仕事・評価にも割と直結するし、具体的な問題つきで勉強できる。
- https://atcoder.jp/contests/apg4b
- C++のコードをPythonで書き直してみるだけでもかなりの勉強になるはず
- Python によるアルゴリズム https://qiita.com/cabernet_rock/items/cdd12b07d213b67d0530
- https://atcoder.jp/contests/apg4b
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- とりあえず本当に簡単な図を描く
- 今回はシグモイド関数
\begin{align} \sigma(x) = \frac{1}{1 + e^{-x}}. \end{align}
- ついでなのでこれの TeX も紹介する
1 2 3 4 5 6 7 8 9 10 11 12 | |
TeX の記録¶
- 凸不等式
- geq, nabla, langle, rangle
\begin{align} f(y) \geq f(x) + \langle \nabla f(x), \, y-x \rangle. \end{align}
競プロ、AtCoder¶
- 実際に競プロの問題をいくつか解いてみましょう。まずは Beginners' selection をやっていきます。
- 今回は ABC087B と ABC083B です。
- Pythonで10問解いてみた記事もあるので参考にしてください。
- 他にもここのページを一通り眺めてみてください。
ABC087B - Coins¶
あなたは、500 円玉を A 枚、100 円玉を B 枚、50 円玉を C 枚持っています。 これらの硬貨の中から何枚かを選び、合計金額をちょうど X 円にする方法は何通りありますか。 同じ種類の硬貨どうしは区別できません。2 通りの硬貨の選び方は、ある種類の硬貨についてその硬貨を選ぶ枚数が異なるとき区別されます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
1 2 | |
注意¶
ブール値は True = 1、False = 0 として足せるらしい。
1 | |
1 | |
上のコードをリスト内包表記で簡潔に¶
1 2 3 4 5 6 7 8 9 10 11 12 | |
1 2 | |
ABC083B¶
1 以上 N 以下の整数のうち、10 進法での各桁の和が A 以上 B 以下であるものの総和を求めてください。
サンプル¶
- 20 以下の整数のうち、各桁の和が 2 以上 5 以下なのは 2,3,4,5,11,12,13,14,20 です。これらの合計である 84 を出力します。
1 | |
1 | |
1 2 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
1 2 3 | |
わからなければ分解しよう¶
- これ、すぐわかる?
1 | |
- 数値を文字列に変換
-
「文字列」を「文字のリスト」とみなして各要素に
intを作用させている -
文字:char (character)
- 文字列:string
1 2 3 4 5 6 7 | |
1 | |
1 2 3 4 5 6 7 8 9 | |
1 2 3 4 | |
1 2 3 4 | |
1 | |
リスト内包表記で簡潔に¶
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 3 | |
IT 一般論¶
- シンプルなシステムからの成長
- ハード構成の基礎:CPU・メモリ・HDD、キャッシュ
- データ構造とアルゴリズム
- 連結リストと配列:どんな特性があるか?
- スタックとキュー:いつどこで使うか?どう実装するか?
前回¶
- システムの成長についていろいろ見た
- ちょっと復習してからハードの構成へ
そもそもなぜ IT 一般論の話をしだしたか¶
- データ構造の話をするため
- メモリの話をしないとリストと配列(とベクター)の違いが説明できない
- 一言でいうと、リストと配列はメモリ上にどうデータを置くかが違う
- データの置き方によってデータアクセスの仕方が変わり、「何が得意か」が変わる
- リスト:要素の追加・削除に都合がいいが、ランダムアクセスと値の更新処理に弱い
- 配列:要素の追加・削除は不便だが、ランダムアクセスと値の更新処理に強い
- ベクター:要素の追加・削除に比較的強く、ランダムアクセスと値の更新処理も強い
- 単純にベクターだけ使っていればいいわけでもない:メモリ効率という観点
- メモリ単独の話をしても多分わからない
- 統計学がらみの話は割とすぐにパフォーマンス(速度)の話になる
- いわゆるビッグデータというやつで、大量のデータを何回も計算しないといけない
- 計算を速くしないとやっていられない
- GPU 使うなり何なり割とすぐにハード面の話が出てくる
- 「メモリを積もう」みたいな話も出てくる
- 計算速度は直接には CPU の役割だったり
シンプルなシステムからの成長¶
- 適当な Web システムを考える。
- 具体的にはショッピングサイトなどをイメージすればいい。
- 何を考えても大きくは変わらない話をする。
- サーバー構成やインフラ設計という言葉で調べると色々出てくる
- サーバー構成の画像:Google 画像検索
大事で面倒な話:「サーバー」とは何か?¶
- 何でもいいが、とりあえず一つ参考ページ
- 物理的なモノとソフトウェア両方ある
- 1 つの物理的なサーバーの中に複数のソフトウェアとしてのサーバーが入っていることがある
- 小規模システムならよくある
- 仮想化・コンテナみたいな話をしだすともっと面倒なことになる
- 今回も多少は詳細化するが、まずは「一度は聞いたことがある」レベルにするのが目的。
基本構成¶
- ソフトウェアとしてのサーバーが 3 つ
- 基本的な構成の画像
- Web サーバー
- アプリケーションサーバー
- データベースサーバー
- Web サーバー:Apache・Nginx:単純に HTML を返すサーバー
- アプリケーションサーバー:いわゆる「アプリケーション」。プログラマーがプログラムを書く部分で、ログインユーザーごとに処理が分かれるとか。最終的に Web サーバーがクライアントに返す HTML の形でデータをまとめる。もちろんここでデータベースのアクセスもある。
- データベースサーバー:顧客情報や製品情報を持っている。
一番単純¶
- 物理サーバーは 1 つ
- ソフトウェアとしての Web サーバー・アプリケーションサーバー・データベースサーバーが載っている。
- 開発者が開発するときは実際にこういう状況で開発している(こともある)
状況に応じていろいろ分かれる¶
- 例えば実際にシステムにかかる負荷によって変わる
- データベースの負荷が高い
- 物理サーバーを追加してデータベースサーバーをそちらに載せ替える。
- Web のリクエストがさばききれないとき
- Web サーバーを切り分けた上で 2 台にわける
- アプリケーションサーバー・データベースサーバーは 1 つの物理サーバーに載せる。
他の状況¶
- データベースの読み込み負荷が高い:Memcache や Redis のようなキャッシュサーバーを(物理サーバーごと)追加する。
- セキュリティが気になってきた:Web サーバーの前にセキュリティ用のファイアーウォール
- セキュリティが絡むとサーバー構成がまた複雑になる。
- 上記画像参考
- 直接外とやり取りするところに外部向けファイアーウォール
- DMZ の中で外部とやり取りするサーバーが置かれる:いわゆるアプリケーションサーバー
- アプリケーションサーバーと「内部」がやり取りするところにまたファイアウォールを置く
- 「内部」というのは顧客データベースなどの社外に公開しないサーバー
- ファイアウォールを二重に置くことで、絶対に触ってはいけないところに対して二重の防御を敷く
- 外部公開しているサーバーがクラックされても内部にアクセスできないようにする
- 内部から危険な情報を外に出せないようにする
ハードウェア構成の基礎¶
- CPU、キャッシュ(キャッシュメモリ)、メモリ、HDD・SSD、キーボード・マウスくらいまでの大まかな話
コンピューター構成の5大要素¶
- 参考
- 制御装置:命令の実行・周辺装置の制御。担当は CPU
- 人間でいうと脳やせき髄
- 演算装置:データを処理。担当は CPU
- 人間でいうと脳
- 記憶装置:データを保存。担当はメモリ・ハードディスク・SSD
- 人間でいうと脳(短期記憶)、「机」、「本棚」
- それぞれの「記憶装置」に意味がある
- 短期記憶は容量が小さいが高速に計算に回せる
- 机は本が置ける
- 本棚に取りに行く手間が省ける分だけデータを取り出すのは速い
- もちろん脳内短期記憶から取り出すよりは遅い
- 本を置ける量は本棚より少ない
- 本棚はたくさん本が置ける
- データを本棚まで取りに行くのは大変(時間がかかる)
- たくさんモノが置ける
- 入力装置:データを受けつける。担当はキーボード・マウスなど
- 出力装置:データや処理の結果を外に出す。ディスプレイ・プリンタ等
CPU からキャッシュ¶
- 参考の図
- 次のセルでもう少し細かい説明

補足コメント¶
- CPU にはコアという概念がある
- 「CPU がクアッドコア」とか何とかいうときの「コア」
- 最近の分散コンピューティングで重要な要素
- 他人の CPU を借りることもよくある
- 「コロナの解析のためにあなたのマシンパワーを貸してください」
- 「ブロックチェーン・ビットコインの計算をさせていた」
- 各コアが計算の単位:コアがたくさんあると並列に計算させられて、処理速度が上がる(類の処理もある)
- コアがたくさんある CPU を使うと個人のコンピューターレベルでもある程度並列処理できる
- 構成はいろいろあるが「スパコン」でも適当な意味で CPU をたくさん並べて使っている
- 1 つ 1 つのスペックが高いコンピューターをたくさん並べる
- 1 つ 1 つのスペックは大したことがないかもしれないが、冗談のようなコンピューター数・並列数で性能を出す
- Google などではトラックに「PC」レベルのコンピューターを大量に積み込み、それで並列計算させていることもあるらしい
- しばらく使っていると各トラックごとにどんどんマシンが壊れていく
- いくつ以上のマシンが壊れたらトラックに積んであるマシンをすべて廃棄して全取り換えする、みたいな話を見たことがある
- どれが故障しているかをいちいち調べるよりも一定の稼働率から下がったら全部つぶす方が「コスパが高い」
- トヨタなどで「不良品のねじが入ったらその箱は全部捨てる」みたいなエピソードを聞くが、まさにそういう感じ
- スケールによってコスパの概念自体が大きく変わるのも大事な認識
- コアに対してキャッシュがある
- 距離が近い順に L1, L2, L3
- キャッシュの容量が大きくなっていく順
- 速度は落ちていく
- キャッシュの後ろにいわゆるメモリがある
- 距離が近い順に L1, L2, L3
- 参考ページ
- レジスターやら何やら細かく見ていくといろいろある
- 大事なこと
- 何はともあれ、現実的にそういう風にできている
- 必要だからそうなっている:少なくとも何かしら、歴史的な理由はある
複数のキャッシュレベル¶
- 前にやったレイテンシー比較
- L1 cache reference
- Read 1 MB sequentially
- 次のセルで細かい説明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
追加説明¶
- 計算速度からの重要性
- 「暗算できれば一番速い」
- L1~L3 のキャッシュを使った計算がいわゆる暗算
- スピードのためにはどれだけキャッシュで処理できるかが勝負
- 数値計算でも大事
- データベースでも大事(なるべくオンメモリのデータですませたい)
- 「暗算できれば一番速い」
- キャッシュの話いろいろ
- 参考その1:次の補足で軽く触れる
- 参考:Wikipedia、記憶階層
- 参考:Wikipedia
- 参考ページ:なぜCPUにはL1・L2・L3というように複数のキャッシュレベルがあるのか?
「それぞれのキャッシュには役割があるから」
「キャッシュは容量が大きいほどデータ転送速度が遅く、記憶密度が高く、省電力という性質を持つため、必要性に応じて異なる種類のキャッシュを使い分けるのが有利だから」
- 省電力の意義:単純にエコなだけではない
- 省電力だと熱も出にくい
- 熱が高くなると熱暴走が起こりうる:逆に計算効率が悪くなる
- マシンを物理的に傷つけにくくので故障もしにくくなる
補足:いろいろなキャッシュ¶
- キャッシュはいろいろなところにある
- ブラウザのキャッシュ:一度読み込んだwebサイトのデータを取っておいて次に読み込むときのロードを速くする
- サイトのロゴなどの画像はそうそう変わらないうえ、画像ファイルは重い(容量が大きい)のでダウンロードにも時間がかかる
- それだけ保管しておく意義がある
- 「自分だけサイトが更新されない?」みたいなことがあったら、それはキャッシュを見ている可能性がある
- サイトのロゴなどの画像はそうそう変わらないうえ、画像ファイルは重い(容量が大きい)のでダウンロードにも時間がかかる
- webシステムでのメモリデータベース(メモリキャッシュ)
- データベースを使うときのデータベースサーバーでのメモリキャッシュ(Redis などのメモリデータベースのキャッシュとはまた違う)
- ブラウザのキャッシュ:一度読み込んだwebサイトのデータを取っておいて次に読み込むときのロードを速くする
- ブラウザのキャッシュについては、「ブラウザが重くなった時」などで調べると「キャッシュを削除しよう」みたいな話が出てくる。
- cf. このページ
- 「GoogleのWebブラウザ「Chrome(クローム)」が重いときに考えられる原因には、キャッシュや履歴などの問題が考えられます。」
- cf. このページ
- ここでコメントしたタイプの「キャッシュ」は日々の PC 利用を快適にする上でも大事
- 快適にする上での情報収集やその意味を理解する上で大事というべきか
補足その 2:「キャッシュ」があるとなぜ重くなる?¶
- ブラウザの話
- キャッシュが大量にあると必要なキャッシュを探す手間が出てくる
- 数十くらいの中ならまだしも、数百・数千・数万から探すとなると探すだけで時間がかかる
- ブラウザを長いこと使っていると、実際にキャッシュがそのくらいに膨れてくる
- 削除して余計な検索処理(計算)がなくなれば、かえって早くなる
- こういうところで「検索」「探索」問題が出てくる
- Google が出てきたのもある意味でこういう文脈
- 検索はデータ構造・アルゴリズムの中でも一番基本的なテーマ
補足¶
- 世の勉強系基本コンテンツの主流はたいてい次の 2 つ
- 論理的完全性
- 網羅性
- 前者の基本コンテンツとその内容は大事だが、構造的に全体像・そこから広がる世界の広がりが見えにくい
- もちろん各種テーマ特化型のコンテンツやオムニバス型のコンテンツもある
- 状況に合わせて適切なコンテンツを組み合わせて勉強するべき
- 複数の本をあえて並行して勉強する意義・意味もある
データ構造とアルゴリズム¶
- 鶏と卵で、同時に考えるべきテーマ:何かをするためにはどンな風にデータを持ってどんな処理をすれば効率がいいか?
- 効率にもいろいろな観点がある
- 単純な処理速度・メモリ消費量・計算量
- 「データの持ち方」「データ構造」に関して軽く
- 本棚をどう整理するか?
- 本の名前順
- 分野を分けたうえで名前順
- 手元に置くのはよく読む本、近い本棚には比較的読む本を分野ごとに名前順、あまり読まない本は押し入れに適当に詰め込む
- 図書館のような大規模なところでは「閉架」という概念がある
- 目的に応じて適切な本の置き方は変わる
- 蔵書の数や質でも変わる
- 図書館なのか本屋なのか
- 本屋だと平積み・面陳列といった概念もある
- 図書館情報学という分野さえある
- どんなデータ構造がいいかはその時々で変わる
- 本棚をどう整理するか?
(連結)リストと配列¶
- 何が違うのか?
- メモリ上のデータの配置やデータの「つなぎ方」
- メモ:zoom の機能で両方の図を描こう
- 状況によって使い分ける
リストの特徴¶
- 要素数は変わることが前提
- データを(先頭に)追加するのは簡単
- データの削除も比較的簡単
- 先頭から 1 つずつ順に処理するならそれなり
- 検索やデータの書き換えが遅い:連結構造をたどる必要がある
配列の特徴¶
- 要素数は固定
- データの追加・削除が重め
- 気分的にはその都度メモリ領域を確保しなおす必要がある:特に追加
- データの参照・書き換えが速い:アドレスが連続なので先頭さえわかれば「そこから何番先」と直指定できる
- 処理によっては「リストで遅ければ配列で書き直す」みたいなことはよくある
ベクター(参考)¶
- 「要素数可変の配列」
- F# だと ResizeArray
- リストのように要素追加・削除が比較的低コストで、要素の参照・書き換えも配列のように速い
- 何が問題か:要素の追加が楽なように余計なメモリ領域を確保する
- ハードウェア組み込みプログラムのように、メモリがカツカツの状況では使えない
- 「メモリがカツカツ」という意味が理解できるか?
シーケンシャルアクセス¶
- レイテンシーのところでも出てきた
- 配列でもリストでも、「先頭から順番になめていく」こと
参考:HDD でのシーケンシャルアクセス・断片化・ディスクデフラグ¶
- ストレージとして HDD しかなかった頃、「PC が重くなったらデフラグしてみよう」という記事はよくあった
- パソコンが重い原因は?PCを軽くする15個改善術と高速化の方法
デフラグとは、デフラグメンテーション(defragmentation)の略です。PCはハードディスクに読み書きを行っていますが、何度も繰り返すうちに連続した広い領域が確保できなくなり、狭い複数の領域に分散して書き込むようになります。データが分散している状態を「断片化」といい、断片化しているとファイルを読み込むのが遅くなり、PC速度が低下します。
断片化したデータを連続した状態に整理することをデフラグといいます。デフラグを定期的に行うことで、読み込み、書き込みが速くなるだけではなく、PC起動が早くなったり、ハードディスクの残り空き容量が増える、というメリットがあります。
なぜ遅くなるのか¶
- ディスク上でデータ断片化すると何が問題か?
- 例:動画が見たい
- 動画用のファイルが HDD 上でいろいろなところに散らばっている
- ある個所からある個所に行くとき、断片化していると、HDD の読み取りの針を物理的に移動させないといけない
- この時間が長い:処理が重くなる原因
- 気分的には「連結リスト」
- こうした話題は何だかんだで普段の PC ライフにも絡んでくる
- 最近は OS を入れる部分は SSD、データを大量に入れる部分は HDD という構成がよくある
- SSD はまだ高いので HDD は死んでいない
補足:なぜ空き容量が増えるのか¶
HDDにデータを書き込む時、データはセクタという最小単位(主に512バイトまたは4,096バイト)に切り分けられ、プラッタの同心円状に作られているトラックと呼ばれる領域に保管されます。
- データ書き込みには最小単位がある
- 断片化して「最小単位」未満のデータで書きこまれてしまっていると、その分容量が無駄になる。
- デフラグするとこの無駄が解放される
- 「配列では一括でズドンとメモリ領域を取る」という「ズドンと取った」状態はこんな感じ。
- 他に触らせない・触らせられないのでこの手の無駄ができる
- ベクターで無駄が出るといったのはこういう状況
2020-07-19 課題¶
- コンテンツの案内ページ
- GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。まずは Beginners' selection をやっていきます。
- 今回は ABC088B - Card Game for Two と ABC085B - Kagami Mochi です。
- Pythonで10問解いてみた記事もあるので参考にしてください。
- 他にもここのページを一通り眺めてみてください。
- 自分の宿題(気になるので調べる)
- SSD の話:記憶の仕方、書き込み耐性
- HDD の最小単位
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。
メモ:先に進む前に録画してあるか確認しよう¶
自分用メモ¶
- 勉強のおすすめ:AtCoder はどうか?C++の解説もあるし、仕事・評価にも割と直結するし、具体的な問題つきで勉強できる。
- https://atcoder.jp/contests/apg4b
- C++のコードをPythonで書き直してみるだけでもかなりの勉強になるはず
- Python によるアルゴリズム https://qiita.com/cabernet_rock/items/cdd12b07d213b67d0530
- https://atcoder.jp/contests/apg4b
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- とりあえず本当に簡単な図を描く
- 今回は減衰振動
\begin{align} x(t) = e^{-\gamma t} \sin \omega t. \end{align}
- ついでなのでこれの TeX も紹介する
```python import numpy as np import matplotlib.pyplot as plt
x = np.linspace(0, 10, 501) y = np.exp(-x) * np.sin(5*x)
plt.plot(x, y, label="dump wave")
plt.grid() plt.legend() #plt.axes().set_aspect('equal', 'datalim') # アスペクト比を合わせる plt.show() ```
TeX の記録¶
- 熱核
- まず名前が格好いい
\begin{align} k(x,y,t) = t^{N - \frac{m}{2}} e^{-\frac{d^2(x,y)}{4t}} \mathcal{K}(x,y,t). \end{align}
競プロ、AtCoder¶
- 実際に競プロの問題をいくつか解いてみましょう。まずは Beginners' selection をやっていきます。
- 今回は ABC088B - Card Game for Two と ABC085B - Kagami Mochi です。
- Pythonで10問解いてみた記事もあるので参考にしてください。
- 他にもここのページを一通り眺めてみてください。
ABC088B - Card Game for Two¶
$N$枚のカードがあります. $i$ 枚目のカードには, $a_i$ という数が書かれています. Alice と Bob は, これらのカードを使ってゲームを行います. ゲームでは, Alice と Bob が交互に 1 枚ずつカードを取っていきます. Alice が先にカードを取ります. 2 人がすべてのカードを取ったときゲームは終了し, 取ったカードの数の合計がその人の得点になります. 2 人とも自分の得点を最大化するように最適な戦略を取った時, Alice は Bob より何点多く取るか求めてください.
例¶
2 3 1
最初, Alice は 3 が書かれたカードを取ります. 次に, Bob は 1 が書かれたカードを取ります. 得点差は 3 - 1 = 2 となります.
説明¶
- 逆順(大きい順、
sorted(lst, reverse=True)に並べる - 最初からお互いに取っていく
- これで最適戦略になる
- 相互の得点をどう計算するかも重要
```python #N = int(input()) #a = sorted(map(int, input().split()))[::-1] def solve(lst): a = sorted(lst, reverse=True) print(a) return sum(a[::2]) - sum(a[1::2])
lst = [3, 1] print(solve(lst)) # 2
lst = [2, 7, 4] print(solve(lst)) # 5
lst = [20, 18, 2, 18] # 18 print(solve(lst)) ```
1 2 3 4 5 6 | |
ABC085B - Kagami Mochi¶
- いわゆるハノイの塔:ただし同じ半径の円盤が複数枚ある
$X$ 段重ねの鏡餅 ($X \geq 1$) とは、$X$ 枚の円形の餅を縦に積み重ねたものであって、どの餅もその真下の餅より直径が小さい(一番下の餅を除く)もののことです。例えば、直径 10、8、6 センチメートルの餅をこの順に下から積み重ねると 3 段重ねの鏡餅になり、餅を一枚だけ置くと 1 段重ねの鏡餅になります。 ダックスフンドのルンルンは $N$ 枚の円形の餅を持っていて、そのうち $i$ 枚目の餅の直径は $d_i$ センチメートルです。これらの餅のうち一部または全部を使って鏡餅を作るとき、最大で何段重ねの鏡餅を作ることができるでしょうか。
解法¶
- 重複をなくせば勝手に順序がつく
- 餅の積み方や積む順序を聞かれているわけではない
- 最大数しか聞かれていない
- 余計な計算をしないことも重要:高速化
仮定¶
- めんどいので実際の入力例とは違う入力を想定する。
- 縦に並んだ数を最初からリストにする
- 実際には次のように入力を取る必要がある
python N = int(input()) d = [input() for i in range(N)]
- これを次のように入力を取る
python d = [1,2,3]
```python def solve(lst): return len(set(lst)) # set で重複をつぶす
lst = [10, 8, 8, 6] print(solve(lst)) # 3
lst = [15, 15, 15] print(solve(lst)) # 1
lst = [50, 30, 50, 100, 50, 80, 30] print(solve(lst)) # 4 ```
1 2 3 | |
IT 基礎知識¶
- SSD の話:記憶の仕方、書き込み耐性
- HDD の最小単位
SSD の話¶
参考記事:SSDの寿命はどれくらい?SSDの寿命に関する情報(SSDの特徴・データ記憶媒体比較・故障予兆・故障症状・寿命延ばす対策)¶
- HDDと比べてSSDは読み書き速度が速い
- 使用環境によっては寿命が短くなってしまう
寿命¶
- SSDの寿命を決める要素は3つ
- 書き込み回数、空き容量、そして使用時間
- SSD:基本的には半導体
- NAND型フラッシュメモリ
- メモリーカードやスマートフォンの記憶媒体と同じタイプのメモリ
- 参考:HDD は磁気ディスク
- NAND型フラッシュメモリ
- データの上書きができない
- 「データの空き容量に新しいデータを書き込み、前のデータを消去する」
- これがSSDの寿命に大きく影響
- SSDは書き込み回数が増えると、次第に劣化
- ゴリゴリの物理の話なので省略:結論だけ受け入れる
- 書き込み可能回数はデータの保持形式にも依存
- TLC:低価格大容量SSDの場合
- 1セルあたりの書き込み可能回数は1千回
- TLC:Triple、1つのセルに電子3つ
- 単電子制御というのは尋常ではない
- 参考:SLC(シングルレベルセル、Single Level Cell)
- 最も耐久性が高い
- 1セルに電子が1つ:セルの中の電子の有無で01が記録
- 1セルに1ビットしか記録できない:データ容量は少ない→高価
- 10万回程度の書き込みに耐え、信頼性と速度は高くなる
- TLC:低価格大容量SSDの場合
- 長い間使っていても SSD は劣化
SSD・HDD・eMMC¶
- SSD(ソリッドステートドライブ)
- NAND型メモリにデータを記録
- 高速で読み書きできる、広く使われているフラッシュメモリ
- 近年大容量化と低価格化
- HDD(ハードディスクドライブ)
- プラッタと呼ばれる円盤型の磁気記憶媒体に磁気ヘッドでデータを書き込み・読み出し
- 構造上SSDに比べるとデータの読み書き速度が低速
- 物理的に複雑な構造
- SSDやeMMCにて比べて大型で重く、電源消費量が多い
- 衝撃に弱い:物理的に針を使っているため
- 大容量のデータを保持するのが得意で安価
- 速度にあまり影響されない画像や動画のバックアップ用
- eMMC(embedded Multi Media Card)
- SSDと同様:フラッシュメモリを使用した記憶ストレージ
- SSDと比較すると読み書きの速度は劣る
- 消費電力は3つの記憶媒体の中で一番低い
- SSDよりもさらに小型
- スマートフォンやタブレットなどモバイル端末用
- UMPC などにも詰まれている
SSDの寿命が近いときの症状とその対策¶
- SSDの寿命が近づいてくるといくつかの予兆がパソコンに現れる
- 処理速度が低下する
- 作業時にフリーズする
- SSDドライブが認識されない
- エラーメッセージが表示される
- ブルースクリーン画面(※)が表示される
- 個人メモ:デスクトップでよくブルースクリーンが出るようになった。画面にはメモリエラーと出ていたが、SSD がまずいかもしれない。
HDD の書き込み最小単位¶
- もともとの問題意識:なぜ最小単位があるのか?
セクタの話¶
- 参考記事
- セクタとは、ディスクに記録する最小記録単位の事です。
- 512 セクタと 4K セクタ
- 4K セクタのメリット:OSで扱える容量が格段に増える
- 今までの【WindowsXP】では、512セクタのハードディスクの場合、2TBまでしか認識できない
- 4Kセクタ対応ハードディスクを使うと大容量ハードディスクを認識できる
- 2TBバイトまでの認識問題
セクターとクラスター¶
- クラスタとは
- HDDなどのドライブにデータを記録して管理する際に使う最小の単位
- 「クラスタ」より小さい「セクタ」という単位がある
- クラスタは複数のセクタで作られる
- HDD上ではセクター単位ではなくクラスター単位でデータを管理
- なぜセクタではなくクラスタ単位でデータを管理するのか?
- HDDの容量が以前に比べて大きくなったため
- セクタのような小さな単位で読み書きをすると、時間がかかる
- 効率悪化
- 「1 ファイル」自体の容量も大きくなっている
- クラスタで処理しても問題は小さいはず
- クラスタのサイズは HDD 容量によって変わる
- 同容量の HDD を使ってもクラスタのサイズが小さい方がデータを効率的に管理できる
- HDD 内のデータの管理を行うファイルシステムがFATやNTFS
- 大昔「ファイルをフォーマットします。Macなどでは使えなくなります」とか出てきた理由がこれ:ファイルシステムが違う形でフォーマットするから
- 参考:実は危険??「exFATフォーマット」との付き合い方
2020-07-26 課題¶
- コンテンツの案内ページ
- GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。まずは Beginners' selection をやっていきます。
- 今回は次の 2 つです。
- Pythonで10問解いてみた記事もあるので参考にしてください。
- 他にもここのページを一通り眺めてみてください。
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
メモ:先に進む前に録画してあるか確認しよう¶
自分用メモ¶
- 勉強のおすすめ:AtCoder はどうか?C++の解説もあるし、仕事・評価にも割と直結するし、具体的な問題つきで勉強できる。
- https://atcoder.jp/contests/apg4b
- C++のコードをPythonで書き直してみるだけでもかなりの勉強になるはず
- Python によるアルゴリズム https://qiita.com/cabernet_rock/items/cdd12b07d213b67d0530
- https://atcoder.jp/contests/apg4b
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- とりあえず本当に簡単な図を描く
- 今回は有限フーリエ級数
\begin{align} f(x) = \frac{4}{\pi} \left( \sin x + \frac{1}{3} \sin 3 x + \frac{1}{5} \sin 5 x + \cdots \right) \end{align}
- ついでなのでこれの TeX も紹介する
```python import numpy as np import matplotlib.pyplot as plt
x = np.linspace(-3, 3, 1001) y = (4 / np.pi) * (np.sin(x) + np.sin(3x) / 3 + np.sin(5x) / 5 + np.sin(7x) / 7 + np.sin(9x) / 9) y1 = np.ones(len(x)) y2 = -1 * np.ones(len(x))
plt.plot(x, y, label="finite fourier") plt.plot(x, y1, label="y=1") plt.plot(x, y2, label="y=-1")
plt.grid() plt.legend() #plt.axes().set_aspect('equal', 'datalim') # アスペクト比を合わせる plt.show() ```
TeX の記録¶
- コンパクト多様体上のラプラシアンの固有値の漸近評価
\begin{align} \lambda_k = 4 \pi \left(\frac{\Gamma (\frac{m}{2} + 1)}{\binom{m}{p} \mathrm{vol}(M)} \right) k^{m/2} + o (k^{m/2}). \end{align}
競プロ、AtCoder¶
- 実際に競プロの問題をいくつか解いてみましょう。まずは Beginners' selection をやっていきます。
- 今回は次の 2 つです。
- Pythonで10問解いてみた記事もあるので参考にしてください。
- 他にもここのページを一通り眺めてみてください。
ABC085C - Otoshidama¶
日本でよく使われる紙幣は、10000 円札、5000 円札、1000 円札です。以下、「お札」とはこれらのみを指します。 青橋くんが言うには、彼が祖父から受け取ったお年玉袋にはお札が $N$ 枚入っていて、合計で $Y$ 円だったそうですが、嘘かもしれません。このような状況がありうるか判定し、ありうる場合はお年玉袋の中身の候補を一つ見つけてください。なお、彼の祖父は十分裕福であり、お年玉袋は十分大きかったものとします。
N 枚のお札の合計金額が Y 円となることがありえない場合は、
-1 -1 -1と出力せよ。 N 枚のお札の合計金額が Y 円となることがありうる場合は、そのような N 枚のお札の組み合わせの一例を「 10000 円札 x 枚、5000 円札 y 枚、1000 円札 z 枚」として、x、y、z を空白で区切って出力せよ。複数の可能性が考えられるときは、そのうちどれを出力してもよい。
入力・出力例 1¶
# 入力 9 45000 # 出力 4 0 5 お年玉袋に 10000 円札 4 枚と 1000 円札 5 枚が入っていれば、合計枚数が 9 枚、合計金額が 45000 円になります。 5000 円札 9 枚という可能性も考えられるため、0 9 0 も正しい出力です。
入出力例 2¶
不適格な場合の出力チェックにあたる。
# 入力 20 196000 # 出力 -1 -1 -1
合計枚数が 20 枚の場合、すべてが 10000 円札であれば合計金額は 200000 円になり、そうでなければ 195000 円以下になるため、196000 円という合計金額はありえません。
入出力例 4¶
変なアルゴリズムを組むと指定計算時間内に終わらない。
# 入力 2000 20000000 # 出力例 2000 0 0
基本方針¶
- 全探索をするしかないが一ひねりして計算量(ループの数)を減らす
- 合計 $Y$ 円が嘘かどうかであり、「何枚以下だったかもしれない」みたいな条件は付いていない
```python # N, Y = map(int, input().split()) def solve(N, Y): for x in range(N+1): for y in range(N-x+1): z = N-x-y # z のループはせずにこれで固定 if 0 <= z <= 2000 and 10000x+5000y+1000*z == Y: return "%s %s %s" % (x, y, z) exit() # ヒットしたので処理終了 # ここまで来たら不適格だったと判断 return "-1 -1 -1"
print(solve(9, 45000)) # 4 0 5 print(solve(20, 196000)) # -1 -1 -1 print(solve(1000, 1234000)) # 14 27 959 他にもありうるはず print(solve(2000, 20000000)) # 2000 0 0 ```
1 2 3 4 | |
ABC049C - 白昼夢¶
英小文字からなる文字列 $S$ が与えられます。 $T$ が空文字列である状態から始め、以下の操作を好きな回数繰り返すことで $S=T$ とすることができるか判定してください。
$T$ の末尾に
dream dreamer erase eraserのいずれかを追加する。
例¶
# 入力例 1 erasedream # 出力例 1 YES erase dream の順で T の末尾に追加することで S = T とすることができます。
# 入力例 2 dreameraser # 出力例 2 YES
# 入力例 3 dreamerer # 出力例 3 NO
```python import re #S = input() def solve(S): # 正規表現を使って特定 4 文字列の繰り返しだけかどうかを判定する return "YES" if re.match("^(dream|dreamer|erase|eraser)+$", S) else "NO"
print(solve("erasedream")) # YES print(solve("dreameraser")) # YES print(solve("dreamerer")) # NO ```
1 2 3 | |
メモ¶
- 正規表現マッチの速度:そんなに速いか?
- 正規表現自体をいろいろ調べないといけない
- ケースバイケースでの実測
- 公式の解説:後ろから文字列マッチしていく
文字列 S を dream, dreamer, erase, eraser に分解していくことを考えます。先頭から分解していこうとす ると、例えば dreamer まで読んだとき、dream で切るべきなのか、dreamer で切るべきなのか判定するこ とができません。(dreameraser は dream eraser と切らなければならないので、dreamer まで読んだときに dream で切らなければいけない場合が存在することが分かります) 逆に、後ろから読んでみましょう。4 つの単語を後ろから読むと、それぞれ maerd, remaerd, esare, resare となります。この 4 つの文字列は、ある文字列が他の文字列の接頭辞 (prefix) になっていないため、後ろか ら読んで当てはまるものが見つかれば即座に分解するしかありません。(参考: 語頭符号) S を最終的に分解す ることができなかった場合 NO を、そうでない場合 YES を出力します。
- 後ろからのマッチ:今の場合の文字列設定だからできることではある
- むしろ問題ごとにその勘所を見抜いて問題ごとに適切な手法を見つけて実装する
IT 基礎知識¶
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。
- これはこれで眺めると大事な用語・概念・操作などがわかる
- ハードル高そうなのでとりあえず保留
- 応用情報技術者試験の本を使って浅く広く眺めてみる
- 根本的にそういう試験
- 横のつながりを見つつ浅く広く知る
7 章 ネットワーク¶
- OSI基本参照モデル、TCP/IP、MACアドレスあたりの話と他のところの関係
- OSI 基本参照モデル
- 上の方が「アプリケーション」
- 下の方はハードウェア
- 例えばセキュリティの話をしているとポンと出てくる
- 「下の方(ハードウェア)」レベルでやった方が処理が速いが、複雑なことはできない
- 高負荷のシステムで手早く最低限の前処理だけしたい場合に有効
- 複雑なことをしない(できない)からこそ速い
- 「上の方(ソフトウェア)」レベルでやると処理は遅いが、複雑な処理ができる
- システムに多少負荷をかけてもいいから、セキュリティを高めたい
- 複雑な処理・計算が必要なのでその分時間がかかる
- 「下の方(ハードウェア)」レベルでやった方が処理が速いが、複雑なことはできない
OSI参照モデルとは|ファイアウォールの種類をわかりやすく解説¶
- レイヤー1:物理層 階層の1段階目は「物理層」です。ハードウェアに最も近い部分であり、電気信号やアナログ信号などによる通信を行っています。主にLANケーブルなどの回線を使って通信を行っています。カプセル化されたデータの単位は「ビット」です。
- レイヤー2:データリンク層 階層の2段階目は「データリンク層」です。同一ネットワーク上での通信を行う階層で、直接的に接続された通信のための規定です。この通信規定により、LANやWANの間の通信を実現できます。カプセル化されたデータの単位は「フレーム」です。
- レイヤー3:ネットワーク層 インターネットでの通信を実現するものが、第3階層である「ネットワーク層」です。この階層ではネットワーク間の通信に関する取り決めが行われています。主にIPアドレスが使われ、ルータによって通信が管理されている階層です。カプセル化されたデータの単位は「パケット」であり、この階層からファイアウォールで通信を制御しています。
- 遥か昔、「ケータイ」のころのパケット通信料は名前が同じだけで本質的には関係ない模様
セキュリティ¶
- パケットフィルタリング:レイヤー3・4で動作 パケットフィルタリング型のファイアウォールは「ネットワーク層」「トランスポート層」で動作します。
- レイヤー3の情報である「送信元IPアドレス」「宛先IPアドレス」をもとに判断することが可能です。このタイプのファイアウォールは構成がシンプルで、ほかの種類よりも処理が速いという特徴があります。
- しかし、安全性はほかの種類よりも低く、フィルタリングの設定が煩雑になることがデメリットです。
- サーキットゲートウェイ:レイヤー5で動作 セッション層で動作するファイアウォールが「サーキットゲートウェイ型」という種類です。
- 先程のパケットフィルタリングの動作に加え、ポート指定や制御ができます。使用するアプリケーションごとに細かく通信の制御を設定することが可能です。
- アプリケーションレベルゲートウェイ:レイヤー5・6・7で動作
- 比較的新しいタイプのファイアウォールが「アプリケーションレベルゲートウェイ」です。
- 主にレイヤー5から7までで動作を行い、アプリケーションレベルのデータをもとに通信を判断します。細かい単位で通信を判断するため、高度な識別が可能です。従来のファイアウォールよりも通信速度が少し落ちますが、なりすましなどの対策ができます。
もう 1 つ参考:ネットワーク各レイヤーのセキュリティを強化するには¶
- トランスポートモード:パケットのペイロードだけを暗号化し、それにIPヘッダを付けて開いて送信する。
トンネルモード:IPヘッダを含めて暗号化されるため、ネットワーク間の安全な接続に用いられる。
「SSL」「TLS」「SSH」といった第4層の通信プロトコルを使用すると、データを暗号化することによって傍受などから守ることが可能になる(「SSL」は「セキュア・ソケッツ・レイヤー」、「TLS」は「トランスポート・レイヤー・セキュリティ」、「SSH」は「セキュア・シェル」の略)。特に機器をリモートで管理するためにネットワーク接続を行う際に十分考慮に入れるべきものである。
- SSL:https の s
- SSH:Linux サーバーにログインするときによく使う。東大のクラウド講義資料でも「SSH で云々」というのがよく出てくる
- こういう感じで横断的にいろいろ出てくる
2020-08-01 課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。例えば次のあたりからアタックします。数学・物理系の話として、まずはマスターオブ整数を眺めてみます。今回は素数判定のA - 素数、コンテスト、素数を見ましょう。
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- 次回対応予定:7.4 ネットワーク層のプロトコルと技術
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 自分用 TODO:Julia 化をがんばる
メモ:先に進む前に録画してあるか確認しよう¶
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- とりあえず本当に簡単な図を描く
- 適当なランダムグラフ
```python import numpy as np import matplotlib.pyplot as plt
y = np.random.rand(100) x = np.linspace(1, 5, 101)
plt.plot(x, y,label="random data") plt.xlabel("time series") plt.ylabel("power") plt.title("sample graph")
plt.grid() plt.legend() #plt.axes().set_aspect('equal', 'datalim') # アスペクト比を合わせる plt.show() ```
TeX の記録¶
- 運動方程式
\begin{align} \dot{p} &= F, \ \frac{dp}{dt} &= F, \ m\ddot{x} &= F, \ m \frac{d^2 x}{dt^2} &= F. \end{align}
競プロ、AtCoder¶
- 実際に競プロの問題をいくつか解いてみましょう。例えば次のあたりからアタックします。数学・物理系の話として、まずはマスターオブ整数を眺めてみます。今回は素数判定のA - 素数、コンテスト、素数を見ましょう。
素数判定のA - 素数、コンテスト、素数¶
ARC N に出場できるとき、すなわち N が素数のときは YES、そうでないときは NO と一行に出力せよ。
- 要は素数判定
- $N$ が素数かどうかを判定するには $\sqrt{N}$ 以下の数までチェックすればいい:素直に $N$ まで見ると大変なことになる。
ルートに対するオーダーの感覚¶
- 具体的に大きな数でどう振る舞うか見てみよう
python import math lst = [1, 10**3, 10**8, 10**15, 10**30, 10**50] for n in lst: print(f"n = {n}") print(f"sqrt n = {math.ceil(math.sqrt(n))}") print("==============")
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
問題の解法¶
```python import math
def is_prime(n): if n == 1: return False for k in range(2, int(math.sqrt(n)) + 1): if n % k == 0: return False return True
def solve(n): return "YES" if is_prime(n) else "NO"
print(solve(17)) # YES print(solve(18)) # NO print(solve(999983)) # YES print(solve(672263)) # NO, 547, 1229 ```
1 2 3 4 | |
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- 次回対応予定:7.4 ネットワーク層のプロトコルと技術
今日の気分¶
- 次のネタを理解する:ツイートへのリンク
- What is your address?
- 173.168.16.11
- No, you local address
- 127.0.0.1
- I mean you physical address
- 28:05:FF:58:31:05
復習:OSI基本参照モデル¶
- 会社の部署と同じ気分
- 特定層は自分のところにしか責任を持たない
- 「他の層は他の層で専門的に管轄してね」
- お互い全くの無関係ではないが、基本的には自分のことだけ考えていればいい。
ある端末が持つ・割り当てられる IP¶
- 大前提:同じマシンでも状況に応じて IP はいろいろ変わる
- 例:スマホ
- 家の中のネット環境
- 外で単独で使うとき
- 適当な Wi-Fi につなぐとき
- 気分:どのルーターの配下にいるか?
- ルーターはあとで触れる
- 例:スマホ
外向き IP(グローバルアドレス)と内向き IP(ローカルアドレス)¶
- あなたが現在インターネットに接続しているグローバルIPアドレス確認
- (iPhone での)今の IP 確認
- iPhoneの設定アプリを開く。
- 「Wi-Fi」をタップする。
- 接続中の電波の名前欄をタップする。
- 「IPV4アドレス」の項目内の「IPアドレス」を確認する。
- cf. MACアドレス
- OSI での対応
- OSI参照モデルでいえば、第2層(データリンク層)Media Access Controlのアドレスにあたる。
- IPv4では、MACアドレスとIPアドレスの相互変換には、ARPやRARPというプロトコルを用いる。
- IPv6では、MACアドレスとIPアドレスの相互変換には、ICMPv6で規定されている近隣探索プロトコル(Neighbor discovery, NDP)を用いる。
- IP は第3層のネットワーク層
- OSI での対応
MACアドレスは、LANカード、ルータ、ハブなどのネットワーク機器に割り当てられます。実際にデータ通信を行う際、最終的にはパソコンなどのコンピュータ同士、つまりIPアドレス間のやり取りになりますが、行き来するデータは途中でルータやハブなどの機器を経由しています。機器から機器へのデータ移動の際に、MACアドレスによって、次のデータの引き渡し先を判別するという仕組みです。
IP 割り当て問題¶
- いろいろな切り口がある
- 1 つの方向性:IP 枯渇問題
- なぜ IPv4 と IPv6 の 2 つがあるのか?
- IPv4 では足りなくなったから
- IPv6 で方式ごと変えて増やした
- IoT 端末にも IP を振りたい:冷蔵庫を外から操作
- 内向き・外向きのアドレスが出てくる理由も同じ
- 外向きのアドレスが「真のアドレス」:会社の代表番号
- 内向きのアドレスは内線番号
- 内線番号にまでいちいち正規の電話番号を割り当てない
- そもそも公開したいとさえ思わない
- 「公開したいとさえ思わない」というのがまさに別の切り口の 1 つ
本の記述を追いかける¶
P.386 コネクションレス型通信である¶
通信中のパケット紛失や重複、改竄の検出やそのための対応が必要な場合はアプリケーションで行う。それによってトランスポート層でのそのような処理のオーバーヘッドを削減している。リアルタイム・システムでは遅れているパケットを待つよりもそういうパケットはないものとして処理する方が好ましいため、適時性を重視するアプリケーションでよく使われている[1]。トランスポート層での誤り検出機能が必須なら、その用途に設計された Transmission Control Protocol (TCP) または Stream Control Transmission Protocol (SCTP) を使えばよい。
- オーバーヘッドの問題はいろいろなところで出てくる
- 参考:「ITの分野では、コンピュータで何らかの処理を行う際に、その処理を行うために必要となる付加的、間接的な処理や手続きのことや、そのために機器やシステムへかかる負荷、余分に費やされる処理時間などのことをオーバーヘッドということが多い。」
P.386 ルーターとは¶
- 異なるネットワークを相互に接続するネットワーク機器
- Wikipedia
通常はOSI基本参照モデルでの第1層(物理層)から第3層(ネットワーク層)までの接続を担う。一般的に用いられるルーターは、基本機能として各ネットワーク間でのIPパケット(第3層)をやり取りできるようにする装置であるが、実際は基本に加えてさまざまな付加機能を実現している。
ハードウェアとしてのルーターは、おおまかに通信事業者 (ISP) 向けのコアルーターと企業向けのエッジルーター、コンシューマー向けのブロードバンドルーターに分けられる。
ルーターというのは「会社の電話の内線と外線の交換機」にそっくりです。最初からそう説明すればよかったですね。
あなたが iPad のサファリを開き、キーワード「NETAGE のWiFi レンタルは国内最安?」を Google で検索すると、iPad は WiFi 経由で WiFi ルーターに接続されます。そして WiFi ルーターは LTE(3G や 4G でもいいですけど)で近くの基地局と接続し、その先のインターネットに接続します。 LAN につながった iPad から WiFi 経由でWiFi ルーターにリクエストが送信されたのです。その後、WiFi ルーターから近所のアンテナ基地局へ、そこから更にインターネットを経由して Google サーバにリクエストが届きます。
このようなネットワーク接続状態のとき、WiFi ルーターのこっち側を LAN(ローカルエリアネットワーク)、向こう側を WAN(ワイドエリアネットワーク)と呼びます。(必ずしも正確ではないですが、シンプルに考え、)WAN はインターネット、LAN は WiFi、とすれば分かりやすいと思います。
P.386 (IP)ヘッダ¶
P.389 特殊なIPアドレス¶
- 8.8.8.8:Google の DNS として有名
- 127.0.0.1:開発時によく使う。Windows だと「c:/Windows/System32/drivers/etc/hosts」ファイルでドメイン名「localhost」を指定して使うこともある。
- グローバル IP とローカル IP
- 最初に触れた問題
- 外向きにグローバル IP アドレス、内向きにプライベート IP アドレスを使う
- IP の無駄遣いを防ぐためもある
- クラス A-C:会社の規模によって使い分ける
- もちろん A が大企業向け、C が小企業・家庭用という感じ
- 本でいきなり「192.168.」というアドレスが出てくることがあるが、それはまさにこのプライベートアドレスで話をしている。
P.390 サブネットマスク¶
- これは社内セキュリティに使われたりする
- 参考
- 会社の部署間でデータの参照を制限する場合
- パソコンやサーバの台数が多く分割して管理する場合
- 開発環境と本番環境を分けるなど、環境を切り離す場合
- ネットワーク設計の話
- 経営関係の資料を一般社員には見せたくない
- 経営関係者のネットワークとその他社員の領域を切り分け、経営関係者しかその資料があるところにアクセスできないようにする
P.392 IPv6¶
- IP アドレスの枯渇
- IPv4 でも「特殊なIPアドレス」などグローバル・ローカルを分けたりして枯渇対策はしてきた。
- 「端末」が世にあふれてきて、アドレスが足りなくなってきた
- 原理的に「IPアドレスは32けたの2進数」としているので、これ以上増やせない
- IPはよく「インターネット上の住所」に例えられるが、市町村合併で起きる実際の住所変更のように柔軟に変えられるわけではない
- 実際の住所にしても行政関係はもちろん、郵便や運送業などのシステムのレベルでは修正や対応が必要
- IPはよく「インターネット上の住所」に例えられるが、市町村合併で起きる実際の住所変更のように柔軟に変えられるわけではない
- 既存の機器・プログラムはこの前提で動いていて、勝手に変えられないし、仮に変えられるとしても膨大な手間になる
- 新たな仕様を作り、それで世界全体に持っていく
- 少なくとも既存の欠点はつぶしておく必要があるし、しばらく枯渇しないようにしたい
- 原理的に「IPアドレスは32けたの2進数」としているので、これ以上増やせない
P.392 IPv6 の特徴¶
2020-08-16 課題¶
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。例えば次のあたりからアタックします。数学・物理系の話として、まずはマスターオブ整数を眺めてみます。今回は約数列挙のC - Digits in Multiplicationを見ましょう。
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- 次回対応予定:7.4 ネットワーク層のプロトコルと技術
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 勉強会の案内: アインシュタインの特殊相対性理論の原論文を多言語で読む会の話
- 微分積分の話
- 自分用 TODO:Julia 化をがんばる
メモ:先に進む前に録画してあるか確認しよう¶
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- 本当に簡単な図を描く
- $x^2$ のフーリエ級数:参考
\begin{align} f(x) = x^2 = \frac{\pi^2}{3} + \sum_{n=1}^\infty \frac{(-1)^n}{n^2} 4 \cos nx. \end{align}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
TeX の記録¶
- 測地線の方程式
\begin{align} \nabla_{c'} c' &= 0, \ \frac{d^2 c^i}{ds^2} + \Gamma^i_{jk} \frac{dc^j}{ds} \frac{dc^k}{ds} &= 0. \end{align}
競プロ、AtCoder¶
約数列挙のC - Digits in Multiplication¶
整数 $N$ が与えられます。ここで、$2$ つの正の整数 $A,B$ に対して、$F(A,B)$ を「$10$ 進表記における、$A$ の桁数と $B$ の桁数のうち大きい方」と定義します。例えば、$F(3,11)$ の値は、$3$ は $1$ 桁、$11$ は $2$ 桁であるため、$F(3,11)=2$ となります。$2$ つの正の整数の組 $(A,B)$ が $N=A×B$ を満たすように動くとき、$F(A,B)$ の最小値を求めてください。
約数列挙のポイント¶
- 素数判定と同じく $a = 1,2,3,\dots,\sqrt{N}$ で割り続けてためていく。
- $\sqrt{N}$ までしか見ないので、$a$ を約数にしたら $N/a$ も約数リストにためる。
- $N$ が $a^2$ を約数に含むとき、$a = N/a$ になるときがあるので、この重複を除いてリストに入れる。
- Python など集合がある場合は集合にためてもいい。
- 今回の問題は必ずしも全約数列挙ではないので、このリスト自体は作らなくてもいい。
- 参考解答
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
1 2 3 | |
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- 次回対応予定:7.4 ネットワーク層のプロトコルと技術
復習¶
OSI基本参照モデル¶
- 会社の部署と同じ気分
- 特定層は自分のところにしか責任を持たない
- 「他の層は他の層で専門的に管轄してね」
- お互い全くの無関係ではないが、基本的には自分のことだけ考えていればいい。
ある端末が持つ・割り当てられる IP¶
- 大前提:同じマシンでも状況に応じて IP はいろいろ変わる
- 例:スマホ
- 家の中のネット環境
- 外で単独で使うとき
- 適当な Wi-Fi につなぐとき
- 気分:どのルーターの配下にいるか?
- ルーターはあとで触れる
- 例:スマホ
- 参考:WAN
- 参考:インターネットの仕組みとISPの構造
本の記述を追いかける¶
P.386 コネクションレス型通信である¶
通信中のパケット紛失や重複、改竄の検出やそのための対応が必要な場合はアプリケーションで行う。それによってトランスポート層でのそのような処理のオーバーヘッドを削減している。リアルタイム・システムでは遅れているパケットを待つよりもそういうパケットはないものとして処理する方が好ましいため、適時性を重視するアプリケーションでよく使われている[1]。トランスポート層での誤り検出機能が必須なら、その用途に設計された Transmission Control Protocol (TCP) または Stream Control Transmission Protocol (SCTP) を使えばよい。
- オーバーヘッドの問題はいろいろなところで出てくる
- 参考:「ITの分野では、コンピュータで何らかの処理を行う際に、その処理を行うために必要となる付加的、間接的な処理や手続きのことや、そのために機器やシステムへかかる負荷、余分に費やされる処理時間などのことをオーバーヘッドということが多い。」
P.386 ルーターとは¶
- 異なるネットワークを相互に接続するネットワーク機器
- Wikipedia
通常はOSI基本参照モデルでの第1層(物理層)から第3層(ネットワーク層)までの接続を担う。一般的に用いられるルーターは、基本機能として各ネットワーク間でのIPパケット(第3層)をやり取りできるようにする装置であるが、実際は基本に加えてさまざまな付加機能を実現している。
ハードウェアとしてのルーターは、おおまかに通信事業者 (ISP) 向けのコアルーターと企業向けのエッジルーター、コンシューマー向けのブロードバンドルーターに分けられる。
ルーターというのは「会社の電話の内線と外線の交換機」にそっくりです。最初からそう説明すればよかったですね。
あなたが iPad のサファリを開き、キーワード「NETAGE のWiFi レンタルは国内最安?」を Google で検索すると、iPad は WiFi 経由で WiFi ルーターに接続されます。そして WiFi ルーターは LTE(3G や 4G でもいいですけど)で近くの基地局と接続し、その先のインターネットに接続します。 LAN につながった iPad から WiFi 経由でWiFi ルーターにリクエストが送信されたのです。その後、WiFi ルーターから近所のアンテナ基地局へ、そこから更にインターネットを経由して Google サーバにリクエストが届きます。
このようなネットワーク接続状態のとき、WiFi ルーターのこっち側を LAN(ローカルエリアネットワーク)、向こう側を WAN(ワイドエリアネットワーク)と呼びます。(必ずしも正確ではないですが、シンプルに考え、)WAN はインターネット、LAN は WiFi、とすれば分かりやすいと思います。
P.386 (IP)ヘッダ¶
P.389 特殊なIPアドレス¶
- 8.8.8.8:Google の DNS として有名
- 127.0.0.1:開発時によく使う。Windows だと「c:/Windows/System32/drivers/etc/hosts」ファイルでドメイン名「localhost」を指定して使うこともある。
- グローバル IP とローカル IP
- 最初に触れた問題
- 外向きにグローバル IP アドレス、内向きにプライベート IP アドレスを使う
- IP の無駄遣いを防ぐためもある
- クラス A-C:会社の規模によって使い分ける
- もちろん A が大企業向け、C が小企業・家庭用という感じ
- 本でいきなり「192.168.」というアドレスが出てくることがあるが、それはまさにこのプライベートアドレスで話をしている。
P.390 サブネットマスク¶
- これは社内セキュリティに使われたりする
- 参考
- 会社の部署間でデータの参照を制限する場合
- パソコンやサーバの台数が多く分割して管理する場合
- 開発環境と本番環境を分けるなど、環境を切り離す場合
- ネットワーク設計の話
- 経営関係の資料を一般社員には見せたくない
- 経営関係者のネットワークとその他社員の領域を切り分け、経営関係者しかその資料があるところにアクセスできないようにする
P.392 IPv6¶
- IP アドレスの枯渇
- IPv4 でも「特殊なIPアドレス」などグローバル・ローカルを分けたりして枯渇対策はしてきた。
- 「端末」が世にあふれてきて、アドレスが足りなくなってきた
- 原理的に「IPアドレスは32けたの2進数」としているので、これ以上増やせない
- IPはよく「インターネット上の住所」に例えられるが、市町村合併で起きる実際の住所変更のように柔軟に変えられるわけではない
- 実際の住所にしても行政関係はもちろん、郵便や運送業などのシステムのレベルでは修正や対応が必要
- IPはよく「インターネット上の住所」に例えられるが、市町村合併で起きる実際の住所変更のように柔軟に変えられるわけではない
- 既存の機器・プログラムはこの前提で動いていて、勝手に変えられないし、仮に変えられるとしても膨大な手間になる
- 新たな仕様を作り、それで世界全体に持っていく
- 少なくとも既存の欠点はつぶしておく必要があるし、しばらく枯渇しないようにしたい
- 原理的に「IPアドレスは32けたの2進数」としているので、これ以上増やせない
P.392 IPv6 の特徴¶
- 勉強会の案内: アインシュタインの特殊相対性理論の原論文を多言語で読む会の話¶
- bewegter の話をしよう
微分積分¶
- 理解という言葉で何を求めているのか?
- 短期目標と長期目標は何か?
- 質はともかく量をこなしているか?
- 量に関する参考:微分幾何計算ノート
- 基礎をどこまで頑張るか?
- 高校の数学はだいたいいい加減
- day3.pdf, P.15 「微分可能性を保証していない」
- 直近で何を諦めるか?
2020-08-23 課題¶
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。例えば次のあたりからアタックします。数学・物理系の話として、まずはマスターオブ整数を眺めてみます。今回は素因数分解のAOJ Course NTL_1_A Prime Factorizeを見ましょう。
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- 次回対応予定:7.4 ネットワーク層のプロトコルと技術
- TODO scipy 使ったお絵かきが楽しそう
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
TODO¶
- Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
メモ:先に進む前に録画してあるか確認しよう¶
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
- 他の $m, l$ でもやってみる
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
TeX の記録¶
- 測度の完全加法性
\begin{align} \mu \left( \bigcup_{n \in \mathbb{N}} A_n \right) = \sum_{n=0}^\infty \mu \left( A_n \right) \end{align}
競プロ、AtCoder¶
- Project Euler 解答録
- F# と Julia でコードを書いている
- 今後はこれにするか?
素因数分解のAOJ Course NTL_1_A Prime Factorize¶
整数 $n$ を素因数分解してください。
素因数分解のポイント¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
1 2 | |
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- 次回対応予定:7.4 ネットワーク層のプロトコルと技術
復習¶
OSI基本参照モデル¶
- 会社の部署と同じ気分
- 特定層は自分のところにしか責任を持たない
- 「他の層は他の層で専門的に管轄してね」
- お互い全くの無関係ではないが、基本的には自分のことだけ考えていればいい。
いろいろなプロトコル¶
- IP, HTTP, SMTP, POP, ARP...
- 通信の規格
- 状況に応じて適切なプロトコルを選ぶ
- ヘッダ・ボディーの概念
本の記述を追いかける¶
P.386 (IP)ヘッダ¶
参考¶
- HTML のヘッダとボディ
- 実例を見せる:とりあえず自分のサイト
P.389 特殊なIPアドレス¶
- 8.8.8.8:Google の DNS として有名
- 127.0.0.1:開発時によく使う。Windows だと「c:/Windows/System32/drivers/etc/hosts」ファイルでドメイン名「localhost」を指定して使うこともある。
- グローバル IP とローカル IP
- 最初に触れた問題
- 外向きにグローバル IP アドレス、内向きにプライベート IP アドレスを使う
- IP の無駄遣いを防ぐためもある
- クラス A-C:会社の規模によって使い分ける
- もちろん A が大企業向け、C が小企業・家庭用という感じ
- 本でいきなり「192.168.」というアドレスが出てくることがあるが、それはまさにこのプライベートアドレスで話をしている。
P.390 サブネットマスク¶
- これは社内セキュリティに使われたりする
- 参考
- 会社の部署間でデータの参照を制限する場合
- パソコンやサーバの台数が多く分割して管理する場合
- 開発環境と本番環境を分けるなど、環境を切り離す場合
- ネットワーク設計の話
- 経営関係の資料を一般社員には見せたくない
- 経営関係者のネットワークとその他社員の領域を切り分け、経営関係者しかその資料があるところにアクセスできないようにする
P.392 IPv6¶
- IP アドレスの枯渇
- IPv4 でも「特殊なIPアドレス」などグローバル・ローカルを分けたりして枯渇対策はしてきた。
- 「端末」が世にあふれてきて、アドレスが足りなくなってきた
- 原理的に「IPアドレスは32けたの2進数」としているので、これ以上増やせない
- IPはよく「インターネット上の住所」に例えられるが、市町村合併で起きる実際の住所変更のように柔軟に変えられるわけではない
- 実際の住所にしても行政関係はもちろん、郵便や運送業などのシステムのレベルでは修正や対応が必要
- IPはよく「インターネット上の住所」に例えられるが、市町村合併で起きる実際の住所変更のように柔軟に変えられるわけではない
- 既存の機器・プログラムはこの前提で動いていて、勝手に変えられないし、仮に変えられるとしても膨大な手間になる
- 新たな仕様を作り、それで世界全体に持っていく
- 少なくとも既存の欠点はつぶしておく必要があるし、しばらく枯渇しないようにしたい
- 原理的に「IPアドレスは32けたの2進数」としているので、これ以上増やせない
P.392 IPv6 の特徴¶
2020-09-06 課題¶
- 今回から日付設定を次回の勉強会開催日に変更。
- 先に進む前に録画してあるか確認しよう
コンテンツ修正メモ¶
- 平面内で回転している様子を表すコードを書く: $R(\theta)$ を定義して関数化する.
- 矢印を書くときに何を描いているか, 式もきちんと書く.
- 遊ぶ例についてコメントを残す.
途中で見せたページ・動画¶
競プロ、AtCoder¶
- Python でのパイプライン演算子
IT 基礎知識編¶
数学・プログラミング¶
quiver について
- [Pythonによる科学・技術計算] ベクトル場の可視化例,静電磁場, matplotlib
- Rust van der Pol 方程式 2次元非線型力学系 matplotlib・ffmpeg ベクトル場の表示を修正
- フィッツフュー-南雲モデル
- YouTube リスト:数学・物理・プログラミング
- ode_fitzhugh_nagumo.rs
- ode_fitzhugh_nagumo_03_both.py
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- scipy 使ったお絵かきが楽しそう
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。例えば次のあたりからアタックします。数学・物理系の話として、まずはマスターオブ整数を眺めてみます。今回は素因数分解の利用の約数の個数を見ましょう。
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- 次回対応予定:7.4 ネットワーク層のプロトコルと技術
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
TODO¶
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
```python import numpy as np import matplotlib.pyplot as plt from scipy.special import sph_harm
m,l = 0,1 phi = np.linspace(0, np.pi, 31) theta = np.linspace(0, 2 * np.pi, 46) phi, theta = np.meshgrid(phi, theta)
r = sph_harm(m, l, theta, phi).real x = np.abs(r) * np.sin(phi) * np.cos(theta) y = np.abs(r) * np.sin(phi) * np.sin(theta) z = np.abs(r) * np.cos(phi)
fig = plt.figure(figsize=(8, 8)) ax = fig.gca(projection="3d") ax.plot_surface(x, y, z, color="aqua", edgecolor="k") plt.axis("off") plt.show() ```
TeX の記録¶
- 球面調和関数
- 上でお絵描きした関数。
\begin{align} Y^m_k(\theta, \phi) &= (-1)^{(m+ |m|)/2} \sqrt{\frac{2k+1}{4 \pi} \frac{(k-|m|)!}{((k+|m|)!}} P^{|n|}k (\cos \theta) e^{im\phi}, \ P^{m}_k (t) &= \frac{1}{2^k} (1-t^2)^{m/2} \sum. \end{align}}^{\lfloor (k-m)/2 \rfloor} \frac{(-1)^j (2k-2j)!}{j!(k-j)!(k-2j-m)!} t^{k-2j-m
競プロ、AtCoder¶
- Project Euler 解答録
- F# と Julia でコードを書いている
- 今後はこれにするか?
素因数分解の利用の約数の個数¶
整数 $N$ が与えられます。 $N!$ の正の約数の個数を $10^9+7$ で割った余りを求めてください。
約数の個数のポイント¶
- $N= \prod_{k=1}^K p^{e_k}$ と素因数分解できるとき、約数の個数は $(e_1+1)(e_2+1)…(e_K+1)$ 個
- 具体例で計算すればわかる
- 約数の個数を求めるだけなら素因数分解はオーバーキル:約数列挙で十分
- 素因数分解で考えるメリット:約数に関する考察がしやすい
コードの参考¶
```python #N=int(input()) from collections import defaultdict from functools import reduce
#前回の素因数分解とだいたい同じ def solve(n): p = defaultdict(int)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
solve(3) # 4: 3! = 6 で 6 の約数は 1, 2, 3, 6 の 4 つ solve(6) # 30: 6! = 720, 約数は 1, 2, 3, 4, 5, 6, 8, 9, 10, 12, 15, 16, 18, 20, 24, 30, 36, 40, 45, 48, 60, 72, 80, 90, 120, 144, 180, 240, 360, 720 solve(1000) # 972926972 ```
1 2 3 | |
Project Euler も見てみよう¶
- GitHub の回答ページ
- 中高生の数学・プログラミング学習用によかろうと思い、ちょこちょこやっている $a$
- F#, Julia の
|>を説明する- Twitter (私の TL)でも話題になった $f(x)$ か $xf$, $x^f$ か
- F# や Julia の標準も $f(x)$ 型だが、$xf$ と書くための機構がある
- Unix のパイプラインと同じ:データがあって、それをコマンドで順に整形していくワンライナーのイメージ
- この感覚が育っていると実に自然な記法
- 書いていて楽しい
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- 次回対応予定:7.4 ネットワーク層のプロトコルと技術
復習¶
OSI基本参照モデル¶
- 会社の部署と同じ気分
- 特定層は自分のところにしか責任を持たない
- 「他の層は他の層で専門的に管轄してね」
- お互い全くの無関係ではないが、基本的には自分のことだけ考えていればいい。
いろいろなプロトコル¶
- IP, HTTP, SMTP, POP, ARP...
- 通信の規格
- 状況に応じて適切なプロトコルを選ぶ
- ヘッダ・ボディーの概念
本の記述を追いかける¶
P.392 IPv6¶
- IP アドレスの枯渇
- IPv4 でも「特殊なIPアドレス」などグローバル・ローカルを分けたりして枯渇対策はしてきた。
- 「端末」が世にあふれてきて、アドレスが足りなくなってきた
- 原理的に「IPアドレスは32けたの2進数」としているので、これ以上増やせない
- IPはよく「インターネット上の住所」に例えられるが、市町村合併で起きる実際の住所変更のように柔軟に変えられるわけではない
- 実際の住所にしても行政関係はもちろん、郵便や運送業などのシステムのレベルでは修正や対応が必要
- IPはよく「インターネット上の住所」に例えられるが、市町村合併で起きる実際の住所変更のように柔軟に変えられるわけではない
- 既存の機器・プログラムはこの前提で動いていて、勝手に変えられないし、仮に変えられるとしても膨大な手間になる
- 新たな仕様を作り、それで世界全体に持っていく
- 少なくとも既存の欠点はつぶしておく必要があるし、しばらく枯渇しないようにしたい
- 原理的に「IPアドレスは32けたの2進数」としているので、これ以上増やせない
P.392 IPv6 の特徴¶
- 家電などへもIP アドレスを採番できるようになった。
- アドレス空間が32ビットから128ビットに拡張
- ルーティングに不要なフィールドを拡張ヘッダに分離
- 基本ヘッダを簡素かつ固定長:固定長のご利益はあとで
- ルータなどの負荷を軽減
- IPレベルのセキュリティ機能IPsecに標準対応
- IPSec
- 暗号技術で IP パケット単位で改竄検知や秘匿機能を提供するプロトコル
- 暗号化をサポートしていないトランスポート層やアプリケーションでも通信路の途中での盗聴や改ざんを防止できる。
- IPアドレスの自動設定機能の組み込み
- DHCP を使わなくてもよくなる
- 特定グループのうち経路上最も近いノード,あるいは最適なノードにデータを送信するエニーキャストの追加
- エニーキャスト
- ルーティングトポロジーから見てデータを「最も近い」または「最もよい」あて先に送信するネットワークのアドレッシング/ルーティング手法である(anycast―どこかに送信)。
- エニーキャスト
固定長レコードのメリット・デメリット¶
- 対義語は可変長レコード
- 固定長レコード
- 全てが桁数で決まる
- メリットであり、デメリットでもある
- 参考
- すべてのデータの長さが同じ
- わざわざ「何文字で終わりか」と考える必要がなくなる
- データベースにもプログラム(変数の型)にもある:「何文字までを許すデータ型」
- 全てが桁数で決まる
- デメリット
- データ項目を増やしたりデータ項目の桁数を増やすためにシステムの大規模修正が出る可能性がある
- 2000 年問題の原因の 1 つ
- 年号を 2 桁で持っていたため
- 4 桁で持っていれば問題なかった
- これが起きた原因
- 昔は HDD 容量なども限られていた上、恐ろしく高価だったので削れる分は削っていた
- そんなに長期間にわたって使われると思っていなかった
- 個別のシステムはともかく、2桁表記というルール自体が一般化してしまった
- いまの類似の問題:Unix 時間と 2038 年問題
ホップ・リミット¶
- パケットの生存時間(通過可能なルータの最大数)
- なぜこれが必要か?
- プログラム(アルゴリズム)によってネットワークをたどって目的地に行くために起こる問題
- 何か・どこかがおかしくて、ネットワークのある一部をループしてしまうかもしれない
- ループを抜け出すような処理を書くよりはそのパケットを捨てて再送させた方が楽
- いつ捨てるか:パケットの寿命・生存時間
- 辿ろうと思っていたネットワークが急な瞬断・故障などで辿れなくなった
- 適切なところまで戻ってから新たなルートを探す必要がある
- 計算時間・ネットワーク上での情報の移動時間がかかり、その分帯域も占有し圧迫する
- そのパケットは捨てた方が早いかもしれない
P.394 アドレス変換技術¶
インターネットに接続するノードには,IPアドレスが割り当てられている必要があります。しかし,各組織に1つのIPアドレスがあれば,IPアドレスを割り当てられていないノードからもインターネットに接続できるといった技術があります。
- ルーターやグローバル IP・ローカル IP の発想でもある
P.395 ICMP を利用した ping¶
- ネットワークの疎通確認でよく使う
- 「ネットがつながらない」
- 「どこまでつながるか、ping 打って試してみて」
- 疎通
- 意思疎通の疎通だが、ここではネットワーク用語
- 参考:疎通確認でよくやること
- ルーターにつながるか、ルーターの IP を打ってみて確認
- つながらなければマシンの設定がおかしい可能性がある
- マシンの無線 Wi-Fi 送受信のハードウェアが壊れている
- ルーターが死んでいる(壊れた・停電後に電源が落ちたまま)など
- 適当な DNS につながるか、DNS の IP を打ってみて確認
- 何らかの理由でルーターから出られていない?
- DNS が死んでいる?
- ルーターにつながるか、ルーターの IP を打ってみて確認
- こういう感じの状況切り分けでよく使う
- 状況切り分けという手法自体、アルゴリズムの二分探索にも近い発想で、プログラミングそれ自体にも非常に重要。
- 他にもいろいろな応用がある
- パソコンサポートでの一幕
- 「パソコンがつかない」
- 「コンセントは繋いでいますか?」
- 直接聞くと怒るタイプの社会性が高い人もいる
- 「まずは電源を差し込んでみてください」
P.395 COLUMN¶
- これらのコマンドはたまに使う:ifconfig, netstat, nslookup
- 覚えなくてもいい:そういうコマンドがあることを知っているだけでも全然違う
P.396 7.5 トランスポート層のプロトコル¶
P.396 7.5.1 TCP と UDP¶
- トランスポート層は IP を補完し、データ送信の品質・信頼性を上げる
- プロトコルは TCP・UDP
P.396 TCP¶
- IP はデータ通信の安全性を保障しないコネクションレス型通信
- IP の補完のために送達管理・伝送管理の機能を持つコネクション型プロトコル
- 特に HTTP や FTP のような全て確実に伝わってほしいリクエスト・レスポンスに使われる
- 参考:一部が落ちてもいいリクエスト・レスポンス
- 動画:一部が抜け落ちてもそれほど問題なく、かつ大容量で帯域を圧迫するので再送も控えたい
P.397 TCP でのコネクションの確立¶
- 3 ウェイハンドシェイク
- クライアント→サーバー:コネクションの確立要求、SYN(synchronize packet)
- サーバー→クライアント:上記への ACK(acknowledgement packet)・SYN
- クライアント→サーバー:上記への ACK
- TCP コネクションは, あて先 IP アドレス, あて先 TCP ポート番号, 送信元 IP アドレス, 送信元 TCP ポート番号の 4 つによって識別される.
ポート・ポート番号¶
ポートとは、ネットワークでデータを通信するための扉のようなものだと思うとわかりやすいだろう。ポート番号はその扉の番号だ。
それぞれプログラムの種類によって、使うポート(扉)が違う。例えば、メールを送るにはこの扉、メールを受け取るにはこの扉、Webページを見てもらうのはこの扉、などと決まっているわけだ。
実際TCPやUDPで通信を行うときは、コンピュータ一台という単位ではなく「プログラム単位」つまり「プロセスやスレッド単位」で通信が行われる。そのためプロセス同士、正しく受け渡しをする必要がある。
- プロセス・スレッドなどいきなりかなり低レイヤーの話がでてくることに注意。
このとき通信しているプロセスには「ポート番号」というものが割り振られる。プロセスやスレッドはこのポート番号を目印にして、どのアプリケーションとどのアプリケーションが通信をとっているのかを判別することになる。
IPアドレスを建物の住所に例えるなら、ポート番号は「部屋の番号は何号室か?」という例えになる。コンピュータネットワークにおいて、プロトコル、IPアドレスとポート番号はまとめると、「どのような方法」で「どこ」の「何号室」に通信をとるのか?という形にいいかえることが出来る。
通信において重要なポート番号だがポートを開くということは、特定の部屋の扉をあけはなっている状態に等しいので、サービスを提供するサーバでもないかぎり、基本的に不必要なポートは開かないように設定しておかなければならない。
- サーバーのセキュリティなども絡むが分かる。
代表的なポート番号とプロトコル それぞれ「どの様なプロトコルがどの様なポート番号で運用されるのか?」代表的な例をあげると以下のようになる。
- TCP 20 : FTP (データ)
- TCP 21 : FTP (制御)
- TCP 22 : SSH
- TCP 23 : Telnet
- TCP 25 : SMTP
- UDP 53 : DNS
- UDP 67 : DHCP(サーバ)
- UDP 68 : DHCP(クライアント)
- TCP 80 : HTTP
- TCP 110 : POP3
- UDP 123 : NTP
- TCP 443 : HTTPS
- WELL KNOWN PORT NUMBERS 0~1023
- MySQL: 3306
P.397 アプリケーション間の通信¶
- トランスポート層にはアプリケーション間の通信の実現という役割がある
- 各アプリケーションはトランスポート層のヘッダにあるポート番号をみて自分宛のデータか判断する。
P.398 7.6 アプリケーション層のプロトコル¶
P.398 7.6.1 メール関連¶
P.398 メールプロトコル¶
- 送信転送する SMTP (Simple Mail Transfer Protocol)
- メールを受け取る POP3 (Post Office Protocol 3)
- IMAP (Internet Message Access Protocol)
補足:POP と IMAP¶
- (気分的には)管理する主体が違う
- POP は単純にサーバーからメールデータを取ってくる
- 取ってきたらサーバーからデータが消える
- そのあとは自分で管理する
- IMAP の説明の参考
- 郵便にたとえると、(実際にはできませんが)郵便局から手紙は受け取らずコピーをもらってくるような形になり、手紙は郵便局が保管することになります。
- メールはサーバに保管されますので、既読・未読・削除、フォルダの分類といった管理は、すべてサーバ上で行われます。
- いろいろな端末でメールが見られる
- POP と IMAP のメリット・デメリット
- POP
- メリット
- PC などの端末にメールが保存される
- 端末が許す限りメールを保存できる
- 端末に保存されたメールはネット接続なしで見られる
- デメリット
- 落としてきた端末でしたメールが見られない
- サーバーに一定期間メールを残す設定で複数端末でメールを見ることもできるが、未読・既読・削除などの状態が反映されない
- メリット
- IMAP:サーバー上でメール管理
- メリット
- 未読・既読などの状態が共有できる
- サーバー上で一元管理できる。
- デメリット
- メールの閲覧・状態修正のためにサーバーと通信する必要がある
- サーバーの容量の上限に達するとメールからサーバーを削除する必要がある
- メリット
- POP
Gmail と IMAP¶
- (何となくの理解しかないので間違っているかもしれない)
- Web インターフェースからの Gmail 利用と Thunderbird などのアプリからの利用で事情が違う
- POP や IMAP が関係してくるのはアプリからの利用
- アプリを使う場合はふつう IMAP を使う
- 参考:公式での説明
- IMAP にしないと他の端末、もっといえば Web インターフェースからも見られなくなる(はず)
- 会社で特定端末からしかメールを見ないなら POP でもいいかもしれない。
- マシンが変わるとき、メールデータも引越ししないと昔のメールが掘れない
- 会社のメールサーバー管理問題・容量問題などはかなり大変
- 一頃「Gmail でサーバー管理問題を解決して、IT 部門が攻めの IT を提案できるようになった」みたいな記事も出ていた
- メールが止まると直接的にビジネスに被害が出る
- 何にせよサーバー管理は大変なので
P.398 メール受信プロトコル、メール関連のプロトコル・規格¶
- 昔のプロトコルはセキュリティ関連の仕様がなかった
- SMTP-AUTH, SMTP over TLS/SSL など
P.399 Web 関連¶
- HTTP: HTTP(Hyper Text Transfer Protocol)は WebサーバとWebクライアント(ブラウザ)間でHTMLなどのWeb情報の配信 に使うプロトコル
- セキュリティ:HTTP に SSL/TLS の認証機能や通信の暗号化を実装した HTTPS が登場
- SOAP: XML を使ってデータ構造を記述
- 最近あまり見かけない印象
- XML 自体もうあまり使わない
- 最近は JSON や GQL をよく見かける
P.401 DNS(Domain Name System)¶
- TCP/IPでは,各ノードに対して一意なIPアドレスが割り当てられている
- IPアドレスは覚えにくい
- IP アドレスと対応する別名であるドメイン名がつけた
- ドメインと IP を対応させるサービスが DNS
- 原理的には世界中のすべてのノードのドメイン名とIPアドレスの対応関係を知ってい なければならない
- 事実上不可能
- DNSの規約では変換表作成の負担を細分化して,DNSを分散データベースとすることで対応しています。
- DNS ルートサーバー
- DNS ポイズニングのような攻撃手法もある
2020-09-13 課題¶
- 先に進む前に録画してあるか確認しよう
進捗メモ¶
プログラミング勉強会¶
- 2020-09-06:線型代数、02_03 の固有ベクトルの計算その 1 まで
- 2020-09-13:02_03 固有値・固有ベクトルの計算その 2 から 03_02 の「具体例:関数 $f(x)=3x^2+4x-5$ の $x=1$ での接線」、「sympy による接線の描画」まで
統計学・機械学習勉強会¶
- 2020-09-09:Twitter sentiment Extaction-Analysis,EDA and Model
- 2020-09-16:M5 Forecasting - Accuracy の予定
- その他参考:MS のベストプラクティス
理系のための語学・リベラルアーツ¶
- 記事へのリンク、2020-08-22:勉強会の案内: アインシュタインの特殊相対性理論の原論文を多言語で読む会
- 2020-09-11:2020-09-11 第 002 回 分詞の解説, 第 1 文の訳と文法事項 アインシュタインの特殊相対性理論の原論文を多言語で読む会
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。例えば次のあたりからアタックします。数学・物理系の話として、まずはマスターオブ整数を眺めてみます。今回は素因数分解の利用の約数の総和を見ましょう。
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- 次回対応予定:7.4 ネットワーク層のプロトコルと技術
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
TODO¶
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
TODO TeX の記録¶
競プロ、AtCoder¶
- Project Euler 解答録
- F# と Julia でコードを書いている
- 今後はこれにするか?
素因数分解の利用の約数の総和¶
- 問題はB - 完全数。
問題文 高橋君は完全なものが大好きです。 自然数には、完全数というものがあります。 完全数というのは、自分以外の約数の総和が自分と等しくなる自然数のことです。 例えば $6$ の場合 $1+2+3=6$ となるので完全数です。 それに対して、自分以外の約数の総和が自分より小さくなる場合は不足数と言い、大きくなる場合は過剰数と言います。 高橋君には今気になっている自然数があります。高橋君のために、それが完全数なのか不足数なのか過剰数なのか判定してください。
約数の総和のポイント¶
- 約数を列挙して足せばいい
- 「約数の個数」を求めたときの考え方を少し改変するだけで求められる
- $N= \prod_{k=1}^K p^{e_k}$ と素因数分解できるとき、約数の総和は次のように書ける。
\begin{align} \left( \sum_{k=0}^{e_1} p_1^{k} \right) \cdot \left( \sum_{k=0}^{e_2} p_2^{k} \right) \cdots \left( \sum_{k=0}^{e_K} p_K^{k} \right) = \prod_{l=1}^K \left( \sum_{k=0}^{e_K} p_l^{k} \right). \end{align}
- 単に約数の総和を求めるだけなら普通に約数列挙した方が楽
コードの参考¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
1 2 3 4 | |
Project Euler も見てみよう¶
- Problem2
- GitHub の回答ページ
- F# での試行錯誤の記録
- 中高生の数学・プログラミング学習用によかろうと思い、ちょこちょこやっている
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
復習¶
OSI基本参照モデル¶
- 会社の部署と同じ気分
- 特定層は自分のところにしか責任を持たない
- 「他の層は他の層で専門的に管轄してね」
- お互い全くの無関係ではないが、基本的には自分のことだけ考えていればいい。
いろいろなプロトコル¶
- IP, HTTP, SMTP, POP, ARP...
- 通信の規格
- 状況に応じて適切なプロトコルを選ぶ
- ヘッダ・ボディーの概念
本の記述を追いかける¶
P.393 ホップ・リミット¶
- パケットの生存時間(通過可能なルータの最大数)
- なぜこれが必要か?
- プログラム(アルゴリズム)によってネットワークをたどって目的地に行くために起こる問題
- 何か・どこかがおかしくて、ネットワークのある一部をループしてしまうかもしれない
- ループを抜け出すような処理を書くよりはそのパケットを捨てて再送させた方が楽
- いつ捨てるか:パケットの寿命・生存時間
- 辿ろうと思っていたネットワークが急な瞬断・故障などで辿れなくなった
- 適切なところまで戻ってから新たなルートを探す必要がある
- 計算時間・ネットワーク上での情報の移動時間がかかり、その分帯域も占有し圧迫する
- そのパケットは捨てた方が早いかもしれない
P.394 アドレス変換技術¶
インターネットに接続するノードには,IPアドレスが割り当てられている必要があります。しかし,各組織に1つのIPアドレスがあれば,IPアドレスを割り当てられていないノードからもインターネットに接続できるといった技術があります。
- ルーターやグローバル IP・ローカル IP の発想でもある
P.395 ICMP を利用した ping¶
- ネットワークの疎通確認でよく使う
- 「ネットがつながらない」
- 「どこまでつながるか、ping 打って試してみて」
- 監視でも使われる:参考ページ、「PING 監視」とあるところ
- せっかくなのでいくつかキーワードなどを盛り込む
- PING 監視、TRAP 監視、RSH、SNMP、SOCKET 通信、POP・SMTP認証、PHN/PNSコマンド、2バイトのコマンド
- インターフェースコンバータ
- 「インタフェースコンバータ」は異なるインタフェースを相互に変換して接続する装置です。異なる規格の通信インタフェースを相互接続して、多種多様なシステムを構築することができます。
疎通とは¶
- 意思疎通の疎通だが、ここではネットワーク用語
- 参考:疎通確認でよくやること
- ルーターにつながるか、ルーターの IP を打ってみて確認
- つながらなければマシンの設定がおかしい可能性がある
- マシンの無線 Wi-Fi 送受信のハードウェアが壊れている
- ルーターが死んでいる(壊れた・停電後に電源が落ちたまま)など
- 適当な DNS につながるか、DNS の IP を打ってみて確認
- 何らかの理由でルーターから出られていない?
- DNS が死んでいる?
- ルーターにつながるか、ルーターの IP を打ってみて確認
- こういう感じの状況切り分けでよく使う
- 状況切り分けという手法自体、アルゴリズムの二分探索にも近い発想で、プログラミングそれ自体にも非常に重要。
- 他にもいろいろな応用がある
- パソコンサポートでの一幕
- 「パソコンがつかない」
- 「コンセントは繋いでいますか?」
- 直接聞くと怒るタイプの社会性が高い人もいる
- 「まずは電源を差し込んでみてください」
P.395 COLUMN¶
- これらのコマンドはたまに使う:ifconfig, netstat, nslookup
- 覚えなくてもいい:そういうコマンドがあることを知っているだけでも全然違う
P.396 7.5 トランスポート層のプロトコル¶
P.396 7.5.1 TCP と UDP¶
- トランスポート層は IP を補完し、データ送信の品質・信頼性を上げる
- プロトコルは TCP・UDP
P.396 TCP¶
- IP はデータ通信の安全性を保障しないコネクションレス型通信
- IP の補完のために送達管理・伝送管理の機能を持つコネクション型プロトコル
- 特に HTTP や FTP のような全て確実に伝わってほしいリクエスト・レスポンスに使われる
- 参考:一部が落ちてもいいリクエスト・レスポンス
- 動画:一部が抜け落ちてもそれほど問題なく、かつ大容量で帯域を圧迫するので再送も控えたい
P.397 TCP でのコネクションの確立¶
- 3 ウェイハンドシェイク
- クライアント→サーバー:コネクションの確立要求、SYN(synchronize packet)
- サーバー→クライアント:上記への ACK(acknowledgement packet)・SYN
- クライアント→サーバー:上記への ACK
- TCP コネクションは, あて先 IP アドレス, あて先 TCP ポート番号, 送信元 IP アドレス, 送信元 TCP ポート番号の 4 つによって識別される.
ポート・ポート番号¶
ポートとは、ネットワークでデータを通信するための扉のようなものだと思うとわかりやすいだろう。ポート番号はその扉の番号だ。
それぞれプログラムの種類によって、使うポート(扉)が違う。例えば、メールを送るにはこの扉、メールを受け取るにはこの扉、Webページを見てもらうのはこの扉、などと決まっているわけだ。
実際TCPやUDPで通信を行うときは、コンピュータ一台という単位ではなく「プログラム単位」つまり「プロセスやスレッド単位」で通信が行われる。そのためプロセス同士、正しく受け渡しをする必要がある。
- プロセス・スレッドなどいきなりかなり低レイヤーの話がでてくることに注意。
このとき通信しているプロセスには「ポート番号」というものが割り振られる。プロセスやスレッドはこのポート番号を目印にして、どのアプリケーションとどのアプリケーションが通信をとっているのかを判別することになる。
IPアドレスを建物の住所に例えるなら、ポート番号は「部屋の番号は何号室か?」という例えになる。コンピュータネットワークにおいて、プロトコル、IPアドレスとポート番号はまとめると、「どのような方法」で「どこ」の「何号室」に通信をとるのか?という形にいいかえることが出来る。
通信において重要なポート番号だがポートを開くということは、特定の部屋の扉をあけはなっている状態に等しいので、サービスを提供するサーバでもないかぎり、基本的に不必要なポートは開かないように設定しておかなければならない。
- サーバーのセキュリティなども絡むが分かる。
代表的なポート番号とプロトコル それぞれ「どの様なプロトコルがどの様なポート番号で運用されるのか?」代表的な例をあげると以下のようになる。
- TCP 20 : FTP (データ)
- TCP 21 : FTP (制御)
- TCP 22 : SSH
- TCP 23 : Telnet
- TCP 25 : SMTP
- UDP 53 : DNS
- UDP 67 : DHCP(サーバ)
- UDP 68 : DHCP(クライアント)
- TCP 80 : HTTP
- TCP 110 : POP3
- UDP 123 : NTP
- TCP 443 : HTTPS
- WELL KNOWN PORT NUMBERS 0~1023
- MySQL: 3306
P.397 アプリケーション間の通信¶
- トランスポート層にはアプリケーション間の通信の実現という役割がある
- 各アプリケーションはトランスポート層のヘッダにあるポート番号をみて自分宛のデータか判断する。
P.398 7.6 アプリケーション層のプロトコル¶
P.398 7.6.1 メール関連¶
P.398 メールプロトコル¶
- 送信転送する SMTP (Simple Mail Transfer Protocol)
- メールを受け取る POP3 (Post Office Protocol 3)
- IMAP (Internet Message Access Protocol)
補足:POP と IMAP¶
- (気分的には)管理する主体が違う
- POP は単純にサーバーからメールデータを取ってくる
- 取ってきたらサーバーからデータが消える
- そのあとは自分で管理する
- IMAP の説明の参考
- 郵便にたとえると、(実際にはできませんが)郵便局から手紙は受け取らずコピーをもらってくるような形になり、手紙は郵便局が保管することになります。
- メールはサーバに保管されますので、既読・未読・削除、フォルダの分類といった管理は、すべてサーバ上で行われます。
- いろいろな端末でメールが見られる
- POP と IMAP のメリット・デメリット
- POP
- メリット
- PC などの端末にメールが保存される
- 端末が許す限りメールを保存できる
- 端末に保存されたメールはネット接続なしで見られる
- デメリット
- 落としてきた端末でしたメールが見られない
- サーバーに一定期間メールを残す設定で複数端末でメールを見ることもできるが、未読・既読・削除などの状態が反映されない
- メリット
- IMAP:サーバー上でメール管理
- メリット
- 未読・既読などの状態が共有できる
- サーバー上で一元管理できる。
- デメリット
- メールの閲覧・状態修正のためにサーバーと通信する必要がある
- サーバーの容量の上限に達するとメールからサーバーを削除する必要がある
- メリット
- POP
Gmail と IMAP¶
- (何となくの理解しかないので間違っているかもしれない)
- Web インターフェースからの Gmail 利用と Thunderbird などのアプリからの利用で事情が違う
- POP や IMAP が関係してくるのはアプリからの利用
- アプリを使う場合はふつう IMAP を使う
- 参考:公式での説明
- IMAP にしないと他の端末、もっといえば Web インターフェースからも見られなくなる(はず)
- 会社で特定端末からしかメールを見ないなら POP でもいいかもしれない。
- マシンが変わるとき、メールデータも引越ししないと昔のメールが掘れない
- 会社のメールサーバー管理問題・容量問題などはかなり大変
- 一頃「Gmail でサーバー管理問題を解決して、IT 部門が攻めの IT を提案できるようになった」みたいな記事も出ていた
- メールが止まると直接的にビジネスに被害が出る
- 何にせよサーバー管理は大変なので
P.398 メール受信プロトコル、メール関連のプロトコル・規格¶
- 昔のプロトコルはセキュリティ関連の仕様がなかった
- SMTP-AUTH, SMTP over TLS/SSL など
P.399 Web 関連¶
- HTTP: HTTP(Hyper Text Transfer Protocol)は WebサーバとWebクライアント(ブラウザ)間でHTMLなどのWeb情報の配信 に使うプロトコル
- セキュリティ:HTTP に SSL/TLS の認証機能や通信の暗号化を実装した HTTPS が登場
- SOAP: XML を使ってデータ構造を記述
- 最近あまり見かけない印象
- XML 自体もうあまり使わない
- 最近は JSON や GQL をよく見かける
P.401 DNS(Domain Name System)¶
- TCP/IPでは,各ノードに対して一意なIPアドレスが割り当てられている
- IPアドレスは覚えにくい
- IP アドレスと対応する別名であるドメイン名がつけた
- ドメインと IP を対応させるサービスが DNS
- 原理的には世界中のすべてのノードのドメイン名とIPアドレスの対応関係を知ってい なければならない
- 事実上不可能
- DNSの規約では変換表作成の負担を細分化して,DNSを分散データベースとすることで対応しています。
- DNS ルートサーバー
- DNS ポイズニングのような攻撃手法もある
P.402 DNS クライアント(リゾルバ)の名前解決要求¶
コンテンツサーバへの問い合わせを繰り返すのは非効率なので,通常,自組織内にキャッシュサーバを置きます。この場合,リゾルバはキャッシュサーバに問い合わせを行い,キャッシュサーバ内に該当情報がキャッシュされていれば直接回答を得ることができます。ない場合は,キャッシュサーバが組織外のコンテンツサーバに問い合わせを行い,その結果をリゾルバに回答します。また,キャッシュサーバは,同様の問い合わせの際に再利用できるよう,問い合わせで得た結果を一定期間キャッシュします。
リゾルバからキャッシュサーバに送られる問い合わせを再帰的な問合せという。"再 帰 的"とは,「再び帰ってくる」という意味で,再帰的な問合せに対しては,最終的な結果を回答する必要がある。
- 例えばディレクトリツリーを掘るタイプのプログラムではよくやる処理
- (F# で)競プロをやっていると意外と再帰を使う(使える)ことに気づいた
- いわゆる関数型言語は(命令型で)ループを使うところは高階関数か再帰で処理する
- たいてい高階関数で足りる
- 再帰は末尾再帰など面倒ポイントがある
P.402 インターネット上の電話サービスで用いるプロトコル¶
- VoIP(Voice over Internet Protocol)
- IPネットワークで音声をやり取りするための技術
- データの伝送にはリアルタイム性に優れたUDPをベースとしたプロトコルが使われる
- 届かなかったらもう一度しゃべらせればいい
P.403 その他のアプリケーション層プロトコル¶
- FTP:ファイルを送る。ポートは 20、21
- セキュリティが甘いので FTP、FTPS、SFTP、SCP などがある
- Telnet:(あまり使ったことない)
- SSH(Secure SHell):サーバーにログインするときに使う。とにかくよく使う。
- テキストベースの通信であるTelnetに対し,暗号化や認証技術を利用して安全に遠隔操作するためのプロトコル
- NTP・SNTP(Network Time Protocol):時刻合わせ
- LDAP(Lightweight Directory Access Protocol):ディレクトリサービスにアクセスするためのプロトコル
- Windows の ActiveDirectory も LDAP を使っている
- 社員情報をやり取りするシステム間連携で出てくる
P.404 7.7 伝送技術¶
P.404 誤り制御¶
- 誤り検出により再送を行う方法 ⇒ パリティチェック,CRC
- 誤り訂正により自己修復を行う方法 ⇒ ハミング符号
P.404 パリティチェック¶
- 最もシンプルな検査方法
- 7 ビットのデータを送信する場合,8 ビット目に誤り検出用のパリティビットを入れてデータの整合性を検査
- 偶数パリティ:8ビットの各ビットについて"1"の数が偶数になるようにパリティビットを挿入する
- 奇数パリティ:上で奇数にする
- 有限体(ガロア体)$\mathbb{F}_2$ (ビット)で考えるといってもいい。
- 微分形式で偶数次と偶数次・偶数次と奇数の積が偶数次になり、奇数次と奇数次の積がと奇数次になるのも一種のパリティチェック。
- cf. P.405 水平垂直パリティチェック
P.404 CRC¶
- CRC:巡回冗長検査(Cyclic Redundancy Check)
- 送信するデータに生成多項式を適用して誤り検出用の冗長データを作成し,それを付けて送信
- 受信側は送信側と同じ生成多項式で受信データを割り,同じ結果であればデータ誤りが ないと判断
- CRCでは複雑な演算を使ってバースト誤り も検出できる
- バースト誤り:データ転送回線上で連続して発生するビットの誤りのこと。ノイズの混入で生じることが多い。
- HDLC 手順が採用
P.404 ハミング符号¶
- 上で紹介した動画で簡単に数学的な原理を紹介している
- 情報ビットに対して検査ビットをつけて 2 ビットまでの誤り検出と,1 ビットの誤り自動訂正機能をもつ誤り制御方式
- 原理的には何ビットの誤り検出・自動訂正でもできる
- 代数幾何符号もある
- 数学的にはもちろん難しい
- 有限体上の(非特異な射影)代数曲線を使う
P.406 同期制御¶
- 通信時に送信側と受信側でタイミングを合わせる必要がある。
- 本の話題とは別に同期・非同期にはいろいろな話があって難しい。
- プログラミング、特に JavaScript フロントエンド周り。
- 通信待ちしていると UX を阻害するのでうまいこと非同期処理を使う
- もちろんバックエンドでもいろいろやらないといけない
- 参考:マイクロサービスにおける 非同期アーキテクチャ
- データベースの同期・非同期
- 大規模サービスでの問題、READ-WRITE、マスター・スレーブ
- ふつう読み込みに比べて書き込みは少ない
- 場合によっては読み込みは完全に最新の情報でなくてもいい
- 書き込みメインのデータベースと、その内容を適当なタイミングでもらってくる読み込み専用のデータベースがある:これがマスターとスレーブ
- 参考:前にやった Twitter のシステム構成など
- 適当な意味で完全同期していないとまずいシステムもある:銀行・金融系
- cf. トランザクション
- トランザクションはふつう銀行が例になるくらい、そちらの話が有名でしかもイメージしやすい
2020-09-20 課題¶
- 先に進む前に録画してあるか確認しよう
進捗メモ¶
- 今回は 03-02 からはじめ、03-03 の「sympy による偏導関数の実装」まで
- 次回は「高階の偏導関数」から
プログラミング勉強会¶
- 2020-09-06:線型代数、02_03 の固有ベクトルの計算その 1 まで
- 2020-09-13:02_03 固有値・固有ベクトルの計算その 2 から 03_02 の「具体例:関数 $f(x)=3x^2+4x-5$ の $x=1$ での接線」、「sympy による接線の描画」まで
統計学・機械学習勉強会¶
- 2020-09-09:Twitter sentiment Extaction-Analysis,EDA and Model
- 2020-09-16:M5 Forecasting - Accuracy の予定
- その他参考:MS のベストプラクティス
理系のための語学・リベラルアーツ¶
- 記事へのリンク、2020-08-22:勉強会の案内: アインシュタインの特殊相対性理論の原論文を多言語で読む会
- 2020-09-11:2020-09-11 第 002 回 分詞の解説, 第 1 文の訳と文法事項 アインシュタインの特殊相対性理論の原論文を多言語で読む会
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。例えば次のあたりからアタックします。数学・物理系の話として、まずはマスターオブ整数を眺めてみます。今回は素因数分解の利用のオイラー関数を見ましょう。
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
TODO¶
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
TeX の記録¶
- シュレディンガー方程式
\begin{align} i \hbar \frac{\partial}{\partial t} \left| \psi \right\rangle = \hat{H} \left| \psi \right\rangle \end{align}
競プロ、AtCoder¶
- Project Euler 解答録
- F# と Julia でコードを書いている
- 今後はこれにするか?
素因数分解の利用のオイラー関数¶
正の整数 $N$ が与えられたとき $1,2,\dots,N$ のうち $N$ と互いに素であるものの個数を $\phi(N)$ と表します。これをオイラー関数とよびます。
問題¶
正の整数 $N$ が与えられる。$1,2,\dots,N$ のうち、$N$ と互いに素であるものの個数を求めよ。
(数値例)
・$N=12$
答え: 4
$1,2,3,4,5,6,7,8,9,10,11,12$ のうち、$12$ と互いに素であるものは、$1,5,7,11$ の $4$ 個です。
オイラー関数のポイント¶
- 素因数分解 $N = p_1^{e_1}p_2^{e_2} \cdots p_K^{e_K}$ に対してオイラー関数は次のように書ける。
\begin{align} \phi(N) = N (1 − 1/p_1)(1 − 1 / p_2) \cdots (1 − 1 / p_K) = N \prod_{i=1}^K \left(1 - \frac{1}{p_i} \right). \end{align}
コードメモ¶
1 2 3 4 5 6 7 | |
1 2 3 4 5 | |
コードの参考¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
1 2 3 4 5 6 7 8 | |
Project Euler も見てみよう¶
- Problem3
- GitHub の回答集
- 中高生の数学・プログラミング学習用によかろうと思い、ちょこちょこやっている
https://projecteuler.net/problem=9
A Pythagorean triplet is a set of three natural numbers, a < b < c, for which,
a2 + b2 = c2 For example, 32 + 42 = 9 + 16 = 25 = 52.
There exists exactly one Pythagorean triplet for which a + b + c = 1000. Find the product abc.
1 2 3 4 5 6 7 8 | |
1 2 3 4 5 6 7 | |
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
復習¶
OSI基本参照モデル¶
- 会社の部署と同じ気分
- 特定層は自分のところにしか責任を持たない
- 「他の層は他の層で専門的に管轄してね」
- お互い全くの無関係ではないが、基本的には自分のことだけ考えていればいい。
いろいろなプロトコル¶
- IP, HTTP, SMTP, POP, ARP...
- 通信の規格
- 状況に応じて適切なプロトコルを選ぶ
- ヘッダ・ボディーの概念
本の記述を追いかける¶
P.395 COLUMN¶
- これらのコマンドはたまに使う:ifconfig, netstat, nslookup
- 覚えなくてもいい:そういうコマンドがあることを知っているだけでも全然違う
P.396 7.5 トランスポート層のプロトコル¶
P.396 7.5.1 TCP と UDP¶
- トランスポート層は IP を補完し、データ送信の品質・信頼性を上げる
- プロトコルは TCP・UDP
P.396 TCP¶
- IP はデータ通信の安全性を保障しないコネクションレス型通信
- IP の補完のために送達管理・伝送管理の機能を持つコネクション型プロトコル
- 特に HTTP や FTP のような全て確実に伝わってほしいリクエスト・レスポンスに使われる
- 参考:一部が落ちてもいいリクエスト・レスポンス
- 動画:一部が抜け落ちてもそれほど問題なく、かつ大容量で帯域を圧迫するので再送も控えたい
P.397 TCP でのコネクションの確立¶
- 3 ウェイハンドシェイク
- クライアント→サーバー:コネクションの確立要求、SYN(synchronize packet)
- サーバー→クライアント:上記への ACK(acknowledgement packet)・SYN
- クライアント→サーバー:上記への ACK
- TCP コネクションは, あて先 IP アドレス, あて先 TCP ポート番号, 送信元 IP アドレス, 送信元 TCP ポート番号の 4 つによって識別される.
ポート・ポート番号¶
ポートとは、ネットワークでデータを通信するための扉のようなものだと思うとわかりやすいだろう。ポート番号はその扉の番号だ。
それぞれプログラムの種類によって、使うポート(扉)が違う。例えば、メールを送るにはこの扉、メールを受け取るにはこの扉、Webページを見てもらうのはこの扉、などと決まっているわけだ。
実際TCPやUDPで通信を行うときは、コンピュータ一台という単位ではなく「プログラム単位」つまり「プロセスやスレッド単位」で通信が行われる。そのためプロセス同士、正しく受け渡しをする必要がある。
- プロセス・スレッドなどいきなりかなり低レイヤーの話がでてくることに注意。
このとき通信しているプロセスには「ポート番号」というものが割り振られる。プロセスやスレッドはこのポート番号を目印にして、どのアプリケーションとどのアプリケーションが通信をとっているのかを判別することになる。
IPアドレスを建物の住所に例えるなら、ポート番号は「部屋の番号は何号室か?」という例えになる。コンピュータネットワークにおいて、プロトコル、IPアドレスとポート番号はまとめると、「どのような方法」で「どこ」の「何号室」に通信をとるのか?という形にいいかえることが出来る。
通信において重要なポート番号だがポートを開くということは、特定の部屋の扉をあけはなっている状態に等しいので、サービスを提供するサーバでもないかぎり、基本的に不必要なポートは開かないように設定しておかなければならない。
- サーバーのセキュリティなども絡むが分かる。
代表的なポート番号とプロトコル それぞれ「どの様なプロトコルがどの様なポート番号で運用されるのか?」代表的な例をあげると以下のようになる。
- TCP 20 : FTP (データ)
- TCP 21 : FTP (制御)
- TCP 22 : SSH
- TCP 23 : Telnet
- TCP 25 : SMTP
- UDP 53 : DNS
- UDP 67 : DHCP(サーバ)
- UDP 68 : DHCP(クライアント)
- TCP 80 : HTTP
- TCP 110 : POP3
- UDP 123 : NTP
- TCP 443 : HTTPS
- WELL KNOWN PORT NUMBERS 0~1023
- MySQL: 3306
P.397 アプリケーション間の通信¶
- トランスポート層にはアプリケーション間の通信の実現という役割がある
- 各アプリケーションはトランスポート層のヘッダにあるポート番号をみて自分宛のデータか判断する。
P.398 7.6 アプリケーション層のプロトコル¶
P.398 7.6.1 メール関連¶
P.398 メールプロトコル¶
- 送信転送する SMTP (Simple Mail Transfer Protocol)
- メールを受け取る POP3 (Post Office Protocol 3)
- IMAP (Internet Message Access Protocol)
補足:POP と IMAP¶
- (気分的には)管理する主体が違う
- POP は単純にサーバーからメールデータを取ってくる
- 取ってきたらサーバーからデータが消える
- そのあとは自分で管理する
- IMAP の説明の参考
- 郵便にたとえると、(実際にはできませんが)郵便局から手紙は受け取らずコピーをもらってくるような形になり、手紙は郵便局が保管することになります。
- メールはサーバに保管されますので、既読・未読・削除、フォルダの分類といった管理は、すべてサーバ上で行われます。
- いろいろな端末でメールが見られる
- POP と IMAP のメリット・デメリット
- POP
- メリット
- PC などの端末にメールが保存される
- 端末が許す限りメールを保存できる
- 端末に保存されたメールはネット接続なしで見られる
- デメリット
- 落としてきた端末でしたメールが見られない
- サーバーに一定期間メールを残す設定で複数端末でメールを見ることもできるが、未読・既読・削除などの状態が反映されない
- メリット
- IMAP:サーバー上でメール管理
- メリット
- 未読・既読などの状態が共有できる
- サーバー上で一元管理できる。
- デメリット
- メールの閲覧・状態修正のためにサーバーと通信する必要がある
- サーバーの容量の上限に達するとメールからサーバーを削除する必要がある
- メリット
- POP
Gmail と IMAP¶
- (何となくの理解しかないので間違っているかもしれない)
- Web インターフェースからの Gmail 利用と Thunderbird などのアプリからの利用で事情が違う
- POP や IMAP が関係してくるのはアプリからの利用
- アプリを使う場合はふつう IMAP を使う
- 参考:公式での説明
- IMAP にしないと他の端末、もっといえば Web インターフェースからも見られなくなる(はず)
- 会社で特定端末からしかメールを見ないなら POP でもいいかもしれない。
- マシンが変わるとき、メールデータも引越ししないと昔のメールが掘れない
- 会社のメールサーバー管理問題・容量問題などはかなり大変
- 一頃「Gmail でサーバー管理問題を解決して、IT 部門が攻めの IT を提案できるようになった」みたいな記事も出ていた
- メールが止まると直接的にビジネスに被害が出る
- 何にせよサーバー管理は大変なので
P.398 メール受信プロトコル、メール関連のプロトコル・規格¶
- 昔のプロトコルはセキュリティ関連の仕様がなかった
- SMTP-AUTH, SMTP over TLS/SSL など
P.399 Web 関連¶
- HTTP: HTTP(Hyper Text Transfer Protocol)は WebサーバとWebクライアント(ブラウザ)間でHTMLなどのWeb情報の配信 に使うプロトコル
- セキュリティ:HTTP に SSL/TLS の認証機能や通信の暗号化を実装した HTTPS が登場
- SOAP: XML を使ってデータ構造を記述
- 最近あまり見かけない印象
- XML 自体もうあまり使わない
- 最近は JSON や GQL をよく見かける
P.401 DNS(Domain Name System)¶
- TCP/IPでは,各ノードに対して一意なIPアドレスが割り当てられている
- IPアドレスは覚えにくい
- IP アドレスと対応する別名であるドメイン名がつけた
- ドメインと IP を対応させるサービスが DNS
- 原理的には世界中のすべてのノードのドメイン名とIPアドレスの対応関係を知ってい なければならない
- 事実上不可能
- DNSの規約では変換表作成の負担を細分化して,DNSを分散データベースとすることで対応しています。
- DNS ルートサーバー
- DNS ポイズニングのような攻撃手法もある
P.402 DNS クライアント(リゾルバ)の名前解決要求¶
コンテンツサーバへの問い合わせを繰り返すのは非効率なので,通常,自組織内にキャッシュサーバを置きます。この場合,リゾルバはキャッシュサーバに問い合わせを行い,キャッシュサーバ内に該当情報がキャッシュされていれば直接回答を得ることができます。ない場合は,キャッシュサーバが組織外のコンテンツサーバに問い合わせを行い,その結果をリゾルバに回答します。また,キャッシュサーバは,同様の問い合わせの際に再利用できるよう,問い合わせで得た結果を一定期間キャッシュします。
リゾルバからキャッシュサーバに送られる問い合わせを再帰的な問合せという。"再 帰 的"とは,「再び帰ってくる」という意味で,再帰的な問合せに対しては,最終的な結果を回答する必要がある。
- 例えばディレクトリツリーを掘るタイプのプログラムではよくやる処理
- (F# で)競プロをやっていると意外と再帰を使う(使える)ことに気づいた
- いわゆる関数型言語は(命令型で)ループを使うところは高階関数か再帰で処理する
- たいてい高階関数で足りる
- 再帰は末尾再帰など面倒ポイントがある
P.402 インターネット上の電話サービスで用いるプロトコル¶
- VoIP(Voice over Internet Protocol)
- IPネットワークで音声をやり取りするための技術
- データの伝送にはリアルタイム性に優れたUDPをベースとしたプロトコルが使われる
- 届かなかったらもう一度しゃべらせればいい
P.403 その他のアプリケーション層プロトコル¶
- FTP:ファイルを送る。ポートは 20、21
- セキュリティが甘いので FTP、FTPS、SFTP、SCP などがある
- Telnet:(あまり使ったことない)
- SSH(Secure SHell):サーバーにログインするときに使う。とにかくよく使う。
- テキストベースの通信であるTelnetに対し,暗号化や認証技術を利用して安全に遠隔操作するためのプロトコル
- NTP・SNTP(Network Time Protocol):時刻合わせ
- LDAP(Lightweight Directory Access Protocol):ディレクトリサービスにアクセスするためのプロトコル
- Windows の ActiveDirectory も LDAP を使っている
- 社員情報をやり取りするシステム間連携で出てくる
P.404 7.7 伝送技術¶
P.404 誤り制御¶
- 誤り検出により再送を行う方法 ⇒ パリティチェック,CRC
- 誤り訂正により自己修復を行う方法 ⇒ ハミング符号
P.404 パリティチェック¶
- 最もシンプルな検査方法
- 7 ビットのデータを送信する場合,8 ビット目に誤り検出用のパリティビットを入れてデータの整合性を検査
- 偶数パリティ:8ビットの各ビットについて"1"の数が偶数になるようにパリティビットを挿入する
- 奇数パリティ:上で奇数にする
- 有限体(ガロア体)$\mathbb{F}_2$ (ビット)で考えるといってもいい。
- 微分形式で偶数次と偶数次・偶数次と奇数の積が偶数次になり、奇数次と奇数次の積がと奇数次になるのも一種のパリティチェック。
- cf. P.405 水平垂直パリティチェック
P.404 CRC¶
- CRC:巡回冗長検査(Cyclic Redundancy Check)
- 送信するデータに生成多項式を適用して誤り検出用の冗長データを作成し,それを付けて送信
- 受信側は送信側と同じ生成多項式で受信データを割り,同じ結果であればデータ誤りが ないと判断
- CRCでは複雑な演算を使ってバースト誤り も検出できる
- バースト誤り:データ転送回線上で連続して発生するビットの誤りのこと。ノイズの混入で生じることが多い。
- HDLC 手順が採用
P.404 ハミング符号¶
- 上で紹介した動画で簡単に数学的な原理を紹介している
- 情報ビットに対して検査ビットをつけて 2 ビットまでの誤り検出と,1 ビットの誤り自動訂正機能をもつ誤り制御方式
- 原理的には何ビットの誤り検出・自動訂正でもできる
- 代数幾何符号もある
- 数学的にはもちろん難しい
- 有限体上の(非特異な射影)代数曲線を使う
P.406 同期制御¶
- 通信時に送信側と受信側でタイミングを合わせる必要がある。
- 本の話題とは別に同期・非同期にはいろいろな話があって難しい。
- プログラミング、特に JavaScript フロントエンド周り。
- 通信待ちしていると UX を阻害するのでうまいこと非同期処理を使う
- もちろんバックエンドでもいろいろやらないといけない
- 参考:マイクロサービスにおける 非同期アーキテクチャ
- データベースの同期・非同期
- 大規模サービスでの問題、READ-WRITE、マスター・スレーブ
- ふつう読み込みに比べて書き込みは少ない
- 場合によっては読み込みは完全に最新の情報でなくてもいい
- 書き込みメインのデータベースと、その内容を適当なタイミングでもらってくる読み込み専用のデータベースがある:これがマスターとスレーブ
- 参考:前にやった Twitter のシステム構成など
- 適当な意味で完全同期していないとまずいシステムもある:銀行・金融系
- cf. トランザクション
- トランザクションはふつう銀行が例になるくらい、そちらの話が有名でしかもイメージしやすい
P.408 7.8 交換方式¶
P.408 パケット交換方式¶
- 回線交換方式と対になる概念
- 回線交換方式:通信を行うノード間で物理的な通信路を確保してから通信する
- 例:電話
- パケット交換方式について
- データ送信するノードはデータをパケットに区切る。
- ひとつひとつのパケットにヘッダを付けて送信。
- ネットワーク内ではパケット交換機にパケットがたまる
- ネットワークの状況に応じて順次送られる
パケット通信のメリット・デメリット¶
メリット¶
- 耐障害性
- 通信路を固定しないため,迂回経路が取れる。
- パケット交換機にデータが蓄積されているため,復旧まで待てる。
- パケット多重
- 1 対 1 の通信で回線を占有する必要がないため,1つの回線を多くのノードで共有でき,回線を効率的につかえる
- 異機種間接続性
- パケット交換機で中継するときにプロトコル変換・速度変換でエンドノードどうしが同じプロトコルをサポートしていなくても通信できる
デメリット¶
- ネットワーク内の蓄積交換処理による遅延
- 蓄積交換処理による遅延解消のために主に回線の帯域を広げることで対応してきた
- 構造上,完全には遅延をなくせない
- パケット到着順序の不整合
P.408 ATM 交換方式¶
- ATM(Asynchronous Transfer Mode:非同期転送モード)
- 遅延のない回線交換方式とパケット交換方式の利点を得たい
- パケット交換方式の発展
- 遅延の原因をつぶす:特にパケットの多様性
- 多種多様なパケットに対応するために,パケット交換機はソフトウェア処理が必要
- ATM での工夫の一例:最も特徴的なのは,パケット(ATMではセルという)の長さをヘッダ部 5 バイト,ペイロード 48 バイトの53バイトに統一
- パケット解析がハードウェアだけでできる。
- ソフトウェアは不要になった。
- Wikipedia から
- 当初の意図に反して非常に複雑な技術になってしまった
- ATM は次世代の主流にならず限定的な使用にとどまった
- ATM の設計思想は MPLS へと引き継がれた
- 汎用のレイヤ 2 のパケットスイッチングのプロトコルとして、ルーターを介したIPの通信網で利用されている。
P.408 ペイロード(payload)¶
- データ通信で本来転送したいデータ本体の部分、ボディを指す。
- ATM ではペイロードのサイズを固定して処理を簡素化
- 難点:パケット全体に占めるペイロードのサイズが相対的に小さくオーバヘッドが大きい
2020-09-27 課題¶
- FTP: file transfer protocol
- 先に進む前に録画してあるか確認しよう
進捗¶
- 今日の進捗
- 基礎知識編:P.370 プロトコルとサービス、ポート・ポート番号、P.397 アプリケーション間の通信、P.398 7.6 アプリケーション層のプロトコル、P.398 7.6.1 メール関連、P.398 メールプロトコル、補足:POP と IMAP、Gmail と IMAP
- 本編:03_03 終了
- 次回
- 本編:03_04 はじめから
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。例えば次のあたりからアタックします。数学・物理系の話として、まずはマスターオブ整数を眺めてみます。今回は6. 素因数分解を活用した考察の6-2. ひねった状況でも「約数の個数」がわかるを見ましょう。
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
TODO¶
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
TeX の記録¶
- 3 次元極座標
\begin{align} x &= r \sin \theta \cos \phi, \ y &= r \sin \theta \sin \phi, \ z &= r \cos \phi. \end{align}
競プロ、AtCoder¶
6. 素因数分解を活用した考察の6-2. ひねった状況でも「約数の個数」がわかる¶
問題¶
$N!$ の正の約数の個数を $1000000007$ で割ったあまりを求めよ。
$1 \le N \le 1000$
(数値例)
・$N = 3$
答え: 4
$3! = 6$ の約数は、$1, 2, 3, 6$ の $4$ 個です。
ポイント¶
- $N!$ は巨大なので約数列挙では途方もない時間がかかる。
- $N!$ を求めてからの約数列挙は非現実的。
-
素因数分解で約数の個数を求める
- 正の整数 $M$ が $M = p_{1}^{e_{1}} p_{2}^{e_{2}} \dots p_{K}^{e_{K}}$ と素因数分解できるとき、$M$ の約数の個数は $(e_{1} + 1)(e_{2} + 1) \dots (e_{K} + 1)$ 個
- $N!$ を計算しなくても $N!$ の素因数分解が分かれば十分
-
n_1 = p_1^{e_1} ...
- n_2 = p_1^{e_1} ...
- N! = p_1^{e_1} ...
コードの参考¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
1 2 3 | |
Project Euler も見てみよう¶
- Problem5
- GitHub の回答集
- 中高生の数学・プログラミング学習用によかろうと思い、ちょこちょこやっている
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
復習¶
OSI基本参照モデル¶
- 会社の部署と同じ気分
- 特定層は自分のところにしか責任を持たない
- 「他の層は他の層で専門的に管轄してね」
- お互い全くの無関係ではないが、基本的には自分のことだけ考えていればいい。
いろいろなプロトコル¶
- IP, HTTP, SMTP, POP, ARP...
- 通信の規格
- 状況に応じて適切なプロトコルを選ぶ
- ヘッダ・ボディーの概念
本の記述を追いかける¶
ポート・ポート番号¶
ポートとは、ネットワークでデータを通信するための扉のようなものだと思うとわかりやすいだろう。ポート番号はその扉の番号だ。
それぞれプログラムの種類によって、使うポート(扉)が違う。例えば、メールを送るにはこの扉、メールを受け取るにはこの扉、Webページを見てもらうのはこの扉、などと決まっているわけだ。
実際TCPやUDPで通信を行うときは、コンピュータ一台という単位ではなく「プログラム単位」つまり「プロセスやスレッド単位」で通信が行われる。そのためプロセス同士、正しく受け渡しをする必要がある。
- プロセス・スレッドなどいきなりかなり低レイヤーの話がでてくることに注意。
このとき通信しているプロセスには「ポート番号」というものが割り振られる。プロセスやスレッドはこのポート番号を目印にして、どのアプリケーションとどのアプリケーションが通信をとっているのかを判別することになる。
IPアドレスを建物の住所に例えるなら、ポート番号は「部屋の番号は何号室か?」という例えになる。コンピュータネットワークにおいて、プロトコル、IPアドレスとポート番号はまとめると、「どのような方法」で「どこ」の「何号室」に通信をとるのか?という形にいいかえることが出来る。
通信において重要なポート番号だがポートを開くということは、特定の部屋の扉をあけはなっている状態に等しいので、サービスを提供するサーバでもないかぎり、基本的に不必要なポートは開かないように設定しておかなければならない。
- サーバーのセキュリティなども絡むが分かる。
代表的なポート番号とプロトコル それぞれ「どの様なプロトコルがどの様なポート番号で運用されるのか?」代表的な例をあげると以下のようになる。
- TCP 20 : FTP (データ)
- TCP 21 : FTP (制御)
- TCP 22 : SSH
- TCP 23 : Telnet
- TCP 25 : SMTP
- UDP 53 : DNS
- UDP 67 : DHCP(サーバ)
- UDP 68 : DHCP(クライアント)
- TCP 80 : HTTP
- TCP 110 : POP3
- UDP 123 : NTP
- TCP 443 : HTTPS
- WELL KNOWN PORT NUMBERS 0~1023
- MySQL: 3306
P.397 アプリケーション間の通信¶
- トランスポート層にはアプリケーション間の通信の実現という役割がある
- 各アプリケーションはトランスポート層のヘッダにあるポート番号をみて自分宛のデータか判断する。
P.398 7.6 アプリケーション層のプロトコル¶
P.398 7.6.1 メール関連¶
P.398 メールプロトコル¶
- 送信転送する SMTP (Simple Mail Transfer Protocol)
- メールを受け取る POP3 (Post Office Protocol 3)
- IMAP (Internet Message Access Protocol)
補足:POP と IMAP¶
- (気分的には)管理する主体が違う
- POP は単純にサーバーからメールデータを取ってくる
- 取ってきたらサーバーからデータが消える
- そのあとは自分で管理する
- IMAP の説明の参考
- 郵便にたとえると、(実際にはできませんが)郵便局から手紙は受け取らずコピーをもらってくるような形になり、手紙は郵便局が保管することになります。
- メールはサーバに保管されますので、既読・未読・削除、フォルダの分類といった管理は、すべてサーバ上で行われます。
- いろいろな端末でメールが見られる
- POP と IMAP のメリット・デメリット
- POP
- メリット
- PC などの端末にメールが保存される
- 端末が許す限りメールを保存できる
- 端末に保存されたメールはネット接続なしで見られる
- デメリット
- 落としてきた端末でしたメールが見られない
- サーバーに一定期間メールを残す設定で複数端末でメールを見ることもできるが、未読・既読・削除などの状態が反映されない
- メリット
- IMAP:サーバー上でメール管理
- メリット
- 未読・既読などの状態が共有できる
- サーバー上で一元管理できる。
- デメリット
- メールの閲覧・状態修正のためにサーバーと通信する必要がある
- サーバーの容量の上限に達するとメールからサーバーを削除する必要がある
- メリット
- POP
Gmail と IMAP¶
- (何となくの理解しかないので間違っているかもしれない)
- Web インターフェースからの Gmail 利用と Thunderbird などのアプリからの利用で事情が違う
- POP や IMAP が関係してくるのはアプリからの利用
- アプリを使う場合はふつう IMAP を使う
- 参考:公式での説明
- IMAP にしないと他の端末、もっといえば Web インターフェースからも見られなくなる(はず)
- 会社で特定端末からしかメールを見ないなら POP でもいいかもしれない。
- マシンが変わるとき、メールデータも引越ししないと昔のメールが掘れない
- 会社のメールサーバー管理問題・容量問題などはかなり大変
- 一頃「Gmail でサーバー管理問題を解決して、IT 部門が攻めの IT を提案できるようになった」みたいな記事も出ていた
- メールが止まると直接的にビジネスに被害が出る
- 何にせよサーバー管理は大変なので
P.398 メール受信プロトコル、メール関連のプロトコル・規格¶
- 昔のプロトコルはセキュリティ関連の仕様がなかった
- SMTP-AUTH, SMTP over TLS/SSL など
P.399 Web 関連¶
- HTTP: HTTP(Hyper Text Transfer Protocol)は WebサーバとWebクライアント(ブラウザ)間でHTMLなどのWeb情報の配信 に使うプロトコル
- セキュリティ:HTTP に SSL/TLS の認証機能や通信の暗号化を実装した HTTPS が登場
- SOAP: XML を使ってデータ構造を記述
- 最近あまり見かけない印象
- XML 自体もうあまり使わない
- 最近は JSON や GQL をよく見かける
P.401 DNS(Domain Name System)¶
- TCP/IPでは,各ノードに対して一意なIPアドレスが割り当てられている
- IPアドレスは覚えにくい
- IP アドレスと対応する別名であるドメイン名がつけた
- ドメインと IP を対応させるサービスが DNS
- 原理的には世界中のすべてのノードのドメイン名とIPアドレスの対応関係を知ってい なければならない
- 事実上不可能
- DNSの規約では変換表作成の負担を細分化して,DNSを分散データベースとすることで対応しています。
- DNS ルートサーバー
- DNS ポイズニングのような攻撃手法もある
P.402 DNS クライアント(リゾルバ)の名前解決要求¶
コンテンツサーバへの問い合わせを繰り返すのは非効率なので,通常,自組織内にキャッシュサーバを置きます。この場合,リゾルバはキャッシュサーバに問い合わせを行い,キャッシュサーバ内に該当情報がキャッシュされていれば直接回答を得ることができます。ない場合は,キャッシュサーバが組織外のコンテンツサーバに問い合わせを行い,その結果をリゾルバに回答します。また,キャッシュサーバは,同様の問い合わせの際に再利用できるよう,問い合わせで得た結果を一定期間キャッシュします。
リゾルバからキャッシュサーバに送られる問い合わせを再帰的な問合せという。"再 帰 的"とは,「再び帰ってくる」という意味で,再帰的な問合せに対しては,最終的な結果を回答する必要がある。
- 例えばディレクトリツリーを掘るタイプのプログラムではよくやる処理
- (F* で)競プロをやっていると意外と再帰を使う(使える)ことに気づいた
- いわゆる関数型言語は(命令型で)ループを使うところは高階関数か再帰で処理する
- たいてい高階関数で足りる
- 再帰は末尾再帰など面倒ポイントがある
P.402 インターネット上の電話サービスで用いるプロトコル¶
- VoIP(Voice over Internet Protocol)
- IPネットワークで音声をやり取りするための技術
- データの伝送にはリアルタイム性に優れたUDPをベースとしたプロトコルが使われる
- 届かなかったらもう一度しゃべらせればいい
P.403 その他のアプリケーション層プロトコル¶
- FTP:ファイルを送る。ポートは 20、21
- セキュリティが甘いので FTP、FTPS、SFTP、SCP などがある
- Telnet:(あまり使ったことない)
- SSH(Secure SHell):サーバーにログインするときに使う。とにかくよく使う。
- テキストベースの通信であるTelnetに対し,暗号化や認証技術を利用して安全に遠隔操作するためのプロトコル
- NTP・SNTP(Network Time Protocol):時刻合わせ
- LDAP(Lightweight Directory Access Protocol):ディレクトリサービスにアクセスするためのプロトコル
- Windows の ActiveDirectory も LDAP を使っている
- 社員情報をやり取りするシステム間連携で出てくる
P.404 7.7 伝送技術¶
P.404 誤り制御¶
- 誤り検出により再送を行う方法 ⇒ パリティチェック,CRC
- 誤り訂正により自己修復を行う方法 ⇒ ハミング符号
P.404 パリティチェック¶
- 最もシンプルな検査方法
- 7 ビットのデータを送信する場合,8 ビット目に誤り検出用のパリティビットを入れてデータの整合性を検査
- 偶数パリティ:8ビットの各ビットについて"1"の数が偶数になるようにパリティビットを挿入する
- 奇数パリティ:上で奇数にする
- 有限体(ガロア体)$\mathbb{F}_2$ (ビット)で考えるといってもいい。
- 微分形式で偶数次と偶数次・偶数次と奇数の積が偶数次になり、奇数次と奇数次の積がと奇数次になるのも一種のパリティチェック。
- cf. P.405 水平垂直パリティチェック
P.404 CRC¶
- CRC:巡回冗長検査(Cyclic Redundancy Check)
- 送信するデータに生成多項式を適用して誤り検出用の冗長データを作成し,それを付けて送信
- 受信側は送信側と同じ生成多項式で受信データを割り,同じ結果であればデータ誤りが ないと判断
- CRCでは複雑な演算を使ってバースト誤り も検出できる
- バースト誤り:データ転送回線上で連続して発生するビットの誤りのこと。ノイズの混入で生じることが多い。
- HDLC 手順が採用
P.404 ハミング符号¶
- 上で紹介した動画で簡単に数学的な原理を紹介している
- 情報ビットに対して検査ビットをつけて 2 ビットまでの誤り検出と,1 ビットの誤り自動訂正機能をもつ誤り制御方式
- 原理的には何ビットの誤り検出・自動訂正でもできる
- 代数幾何符号もある
- 数学的にはもちろん難しい
- 有限体上の(非特異な射影)代数曲線を使う
P.406 同期制御¶
- 通信時に送信側と受信側でタイミングを合わせる必要がある。
- 本の話題とは別に同期・非同期にはいろいろな話があって難しい。
- プログラミング、特に JavaScript フロントエンド周り。
- 通信待ちしていると UX を阻害するのでうまいこと非同期処理を使う
- もちろんバックエンドでもいろいろやらないといけない
- 参考:マイクロサービスにおける 非同期アーキテクチャ
- データベースの同期・非同期
- 大規模サービスでの問題、READ-WRITE、マスター・スレーブ
- ふつう読み込みに比べて書き込みは少ない
- 場合によっては読み込みは完全に最新の情報でなくてもいい
- 書き込みメインのデータベースと、その内容を適当なタイミングでもらってくる読み込み専用のデータベースがある:これがマスターとスレーブ
- 参考:前にやった Twitter のシステム構成など
- 適当な意味で完全同期していないとまずいシステムもある:銀行・金融系
- cf. トランザクション
- トランザクションはふつう銀行が例になるくらい、そちらの話が有名でしかもイメージしやすい
P.408 7.8 交換方式¶
P.408 パケット交換方式¶
- 回線交換方式と対になる概念
- 回線交換方式:通信を行うノード間で物理的な通信路を確保してから通信する
- 例:電話
- パケット交換方式について
- データ送信するノードはデータをパケットに区切る。
- ひとつひとつのパケットにヘッダを付けて送信。
- ネットワーク内ではパケット交換機にパケットがたまる
- ネットワークの状況に応じて順次送られる
パケット通信のメリット・デメリット¶
メリット¶
耐障害性 - 通信路を固定しないため,迂回経路が取れる。 - パケット交換機にデータが蓄積されているため,復旧まで待てる。 - パケット多重 - 1 対 1 の通信で回線を占有する必要がないため,1つの回線を多くのノードで共有でき,回線を効率的につかえる - 異機種間接続性 - パケット交換機で中継するときにプロトコル変換・速度変換でエンドノードどうしが同じプロトコルをサポートしていなくても通信できる
デメリット¶
- ネットワーク内の蓄積交換処理による遅延
- 蓄積交換処理による遅延解消のために主に回線の帯域を広げることで対応してきた
- 構造上,完全には遅延をなくせない
- パケット到着順序の不整合
P.408 ATM 交換方式¶
- ATM(Asynchronous Transfer Mode:非同期転送モード)
- 遅延のない回線交換方式とパケット交換方式の利点を得たい
- パケット交換方式の発展
- 遅延の原因をつぶす:特にパケットの多様性
- 多種多様なパケットに対応するために,パケット交換機はソフトウェア処理が必要 ^ ATM での工夫の一例:最も特徴的なのは,パケット(ATMではセルという)の長さをヘッダ部 5 バイト,ペイロード 48 バイトの53バイトに統一
- パケット解析がハードウェアだけでできる。
- ソフトウェアは不要になった。
- Wikipedia から
- 当初の意図に反して非常に複雑な技術になってしまった
- ATM は次世代の主流にならず限定的な使用にとどまった
- ATM の設計思想は MPLS へと引き継がれた
- 汎用のレイヤ 2 のパケットスイッチングのプロトコルとして、ルーターを介したIPの通信網で利用されている。
P.408 ペイロード(payload)¶
- データ通信で本来転送したいデータ本体の部分、ボディを指す。
- ATM ではペイロードのサイズを固定して処理を簡素化
- 難点:パケット全体に占めるペイロードのサイズが相対的に小さくオーバヘッドが大きい
P.410 輻輳¶
- フレームリレー:パケット交換方式の一種
- 1 つの回線を多数のユーザで共有。
- 回線がもつ潜在的な伝送能力(ワイヤスピード)を十分に引き出すうえで効果がある
- 輻輳:ユーザの利用が一時期に集中すると,ワイヤスピードを超えるパケットがネットワーク上に流れる
- ネットワークが輻輳状態になるとスループットが落ちる
- フレームリレーサービスを提供する事業者は,ネットワークが輻輳状態に陥ってスループットが低下しても最低限保証する通信速度を決めている
- CIR(Committed Information Rate:認定情 報速度)
P.370 7 ネットワーク¶
- 確か 7.4 から始めた気がするので 7 章はじめから
P.370 7.1.1 OSI基本参照モデル¶
- 改めて復習
- OSI(Open System Interconnection)基本参照モデル- 異なる設計思想・世代のシステムと円滑に通信するのが目的に標準化
- プロトコルの単機能化,交換の容易さが目的
- 階層化のおかげで一部の階層の技術体系が変わっても、その階層だけ取り替えればいい
- コスト・リスクを小さくする
P.370 プロトコルとサービス¶
- N 層:それぞれの階層のこと
- エンティティ:N 層に存在する通信機器などの実体
- この言葉はいろいろなところで出てきていろいろな意味で使われる
- もちろん気分的には適当な実体を指すことが多い
- プロトコル:N 層に属するエンティティが通信するための取り決め
- 上位の層が下位の層を利用しながら通信する
- 別の階層間のエンティティどうしが通信する窓口が必要
- これを提供するのが下位層:この機能をサービスと呼ぶ
- プロトコルに沿った仕様で製品を開発すれば別のベンダの機器でも通信できる
- 参考:ベンダーロックイン
特定ベンダー(メーカー)の独自技術に大きく依存した製品、サービス、システム等を採用した際に、他ベンダーの提供する同種の製品、サービス、システム等への乗り換えが困難になる現象のこと。
出来上がった情報システムの正確な仕様が、システムを開発・構築したベンダーにしか解らなくなる場合がある。結果、システムの保守・拡張・改修等の際、現存システムを開発・構築したベンダーに引き続き発注せざるを得なくなる。
- 「Excel で行政に提出する書類を作れ」事案もそれ。
- Apple 製品で身の回りを固めるのも同じ。
- 「多様性が大事」事案でもある。
7.1.2 TCP/IPプロトコルスイート¶
- プロトコル同士には相性がある
- 「ネットワーク層がこのプロトコルならトランスポート層はこのプロトコルにしておくとトラブルが少ない」
- 一般に同じ団体が作ったプロトコルはセットで使われることが多い
- このセットがプロトコルスイート ^ 最も代表的なのは IP を中心に組まれた TCP/IP プロトコルスイート
- 独自の階層モデルをもつ
P.372 TCP/IPの通信¶
- データをパケットに区切る
- 各パケットにヘッダを付けて送信
- ヘッダは各階層ごとに付加されて次の階層へと渡される
- 各ヘッダにはその階層で必要となる送信元や送信先,大きさ,順番などパケット自体に関する情報を含む
- TCPヘッダを付加したパケット:TCP セグメント
- IP ヘッダを付加したパケット:IP パケット
- MACヘッダを付加したパケット:MAC フレームあるいはイーサネットフレーム
P.372 MAC(Media Access Control)アドレス¶
- イーサネットや FDDI で使用される物理アドレス
- イーサネット (Ethernet):コンピューターネットワークの規格の1つ。オフィスや家庭で一般的に使用されている有線LAN (Local Area Network) の技術規格
- FDDI:LAN でデータ転送を行うための標準の一つ
- Fiber distributed data interface
- データリンク層
- 同じネットワークに接続された隣接ノード間の通信で相手を識別するために使う
- MACアドレスの長さ:6バイト
- 先頭24ビットの OUI(ベンダID)
- 後続24ビットの固有製造番号(製品に割り当てた番号)
- MAC アドレスは機器が固有にもつ番号
- 必ず一意に定まるように IEEE が管理
P372 ポート番号¶
- トランスポート層にでノード内のアプリケーションの識別に使う識別子番号
- 0-65535の範囲
- TCP/IPではパケット交換方式でデータをやり取りする
- よく使われるアプリケーションについてのポート番号は Well-Known ポートとして標準化
- TCP・UDPそれぞれで 0-1023 番までの番号を割り当てている
- SSH:TCP22番
- Telnet:TCP23番
- SMTP:TCP25番
- HTTP:TCP80番
- POP3:TCP110番
- IMAP4:TCP143番
- HTTPS :TCP443番
- NTP:UDP123番
- SNMP:UDP161番
- SNMP Trap :UDP162番
- セキュリティ対策のために標準とはポート番号を変えることもある
- Web 開発の本を読んでいると、いろいろな都合から http のポートを 80 以外にしていることもよくある。
- 80 の場合はポートを指定しなくてもいい
- 例:http://localhost/hoge/fuga
- 例:http://localhost:5000/hoge/fuga
- 80 の場合はポートを指定しなくてもいい
P.373 ネットワーク間の通信¶
- 同じネットワークに接続されたノード間はデータリンク層(第 2 層)の通信
- ネットワークを超えたノード間はネットワーク層(第 3 層)の通信 -実際に図 7.1.4 を見よう
- どこが IP アドレスでのやりとりか?
- どこが MAC アドレスでのやり取りか?
P.374 7.2 ネットワーク接続装置と関連技術¶
P.374 7.2.1 物理層の接続¶
P.374 リピータ¶
- ネットワーク上を流れる電流の増幅装置・整流装置
- 物理層:第 1 層
- データ通信はネットワーク上を流れる電流
- ケーブルが長いと電流が減衰・波形が乱れが起きる
- データが読み取れなくなる
- これを増幅するのがリピータ
- 大昔の電話は距離が遠いと音が小さく聞こえにくかった
- まさにこの減衰が問題
- リピータは 1:1 で繋ぐ
- 現在では複数のノードを接続できるマルチポートリピータ(ハブ)が使われるのが一般的
P.374 7.2.2 データリンク層の接続¶
- 第2層
P374 ブリッジ¶
- データリンク層に位置
- ネットワーク上を流れているフレーム(情報の単位)の MAC アドレスを認識して通信を中継する
- 接続されているノードをコリジョンドメイン(セグメント)という単位に分割
- MAC アドレスで判定したフレームのあて先のあるセグメントだけにフレームを送信
- 無駄なトラフィックの回避
2020-10-04 進捗¶
- 今日の進捗
- 基礎知識編:P.406 の同期制御まで
- 本編:03_04 はじめから、03-05 最急降下法の簡単な説明まで
- 次回
- 基礎知識編:P.408 7.8 交換方式から
- 本編:03-05 最急降下法の復習
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。例えば次のあたりからアタックします。数学・物理系の話として、まずはマスターオブ整数を眺めてみます。今回は6. 素因数分解を活用した考察の6-3. 素数を分け合う)を見ましょう。
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
TODO¶
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler \@mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
TeX の記録¶
- 拡散方程式
\begin{align} u_t = \triangle u. \end{align}
競プロ、AtCoder¶
6. 素因数分解を活用した考察の6-3. 素数を分け合う¶
問題¶
$N$ 個の $1$ 以上の整数 $a_1,a_2,\dots,a_N$ があります. $a_1,a_2,\dots,a_N$ の値はわかりませんが, $a_1 \times a_2 \times \cdots \times a_N = P$ がわかっています. $a_1,a_2,\dots,a_N$ の最大公約数として考えられるもののうち, 最も大きいものを求めてください.
ポイント¶
- 「(整数の積) = (整数)」という形の式を見たら素因数分解を考えてみる
- $P$ を素因数分解する
- $a_1 a_2 \cdots a_N= p_1^{e_1} p_2^{e_2} \cdots p_K^{e_K}$
- $e_1$ 個の $p_1$
- $e_2$ 個の $p_2$
- ...
- $e_K$ 個の $p_K$
- $a_1,a_2,\cdots,a_N$ の $N$ 人で分け合う
- $a_1,a_2,\cdots,a_N$ の最大公約数をなるべく大きくするには素数をなるべく均等に分配する
- 注意:「各素因数ごとに独立に考えて良い」
- まとめ
- $P=p_1^{e_1} e_2^{p_2} \cdots p_K^{e_K}$ と素因数分解する
- 各素因数 $p_i$ について、$e_i/N$ を計算し、あまりは切り捨てる
- その個数だけ $p_i$ をかける
コードの参考¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | |
1 2 3 4 | |
1 2 3 4 | |
1 | |
Project Euler も見てみよう¶
- Problem5
- GitHub の回答集
- 中高生の数学・プログラミング学習用によかろうと思い、ちょこちょこやっている
基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
復習¶
OSI基本参照モデル¶
- 会社の部署と同じ気分
- 特定層は自分のところにしか責任を持たない
- 「他の層は他の層で専門的に管轄してね」
- お互い全くの無関係ではないが、基本的には自分のことだけ考えていればいい。
いろいろなプロトコル¶
- IP, HTTP, SMTP, POP, ARP...
- 通信の規格
- 状況に応じて適切なプロトコルを選ぶ
- ヘッダ・ボディーの概念
本の記述を追いかける¶
[P.398 メール受信プロトコル、メール関連のプロトコル・規格]{#P398}¶
- 昔のプロトコルはセキュリティ関連の仕様がなかった
- SMTP-AUTH, SMTP over TLS/SSL など
P.399 Web 関連¶
- HTTP: HTTP(Hyper Text Transfer Protocol)は WebサーバとWebクライアント(ブラウザ)間でHTMLなどのWeb情報の配信 に使うプロトコル
- セキュリティ:HTTP に SSL/TLS の認証機能や通信の暗号化を実装した HTTPS が登場
- SOAP: XML を使ってデータ構造を記述
- 最近あまり見かけない印象
- XML 自体もうあまり使わない
- 最近は JSON や GQL をよく見かける
[P.401 DNS(Domain Name System)]{#P401_DNSDomain_Name_System}¶
- TCP/IPでは,各ノードに対して一意なIPアドレスが割り当てられている
- IPアドレスは覚えにくい
- IP アドレスと対応する別名であるドメイン名がつけた
- ドメインと IP を対応させるサービスが DNS
- 原理的には世界中のすべてのノードのドメイン名とIPアドレスの対応関係を知ってい なければならない
- 事実上不可能
- DNSの規約では変換表作成の負担を細分化して,DNSを分散データベースとすることで対応しています。
- DNS ルートサーバー
- DNS ポイズニングのような攻撃手法もある
[P.402 DNS クライアント(リゾルバ)の名前解決要求]{#P402_DNS}¶
コンテンツサーバへの問い合わせを繰り返すのは非効率なので,通常,自組織内にキャッシュサーバを置きます。この場合,リゾルバはキャッシュサーバに問い合わせを行い,キャッシュサーバ内に該当情報がキャッシュされていれば直接回答を得ることができます。ない場合は,キャッシュサーバが組織外のコンテンツサーバに問い合わせを行い,その結果をリゾルバに回答します。また,キャッシュサーバは,同様の問い合わせの際に再利用できるよう,問い合わせで得た結果を一定期間キャッシュします。
リゾルバからキャッシュサーバに送られる問い合わせを再帰的な問合せという。"再 帰 的"とは,「再び帰ってくる」という意味で,再帰的な問合せに対しては,最終的な結果を回答する必要がある。
- 例えばディレクトリツリーを掘るタイプのプログラムではよくやる処理
- (F# で)競プロをやっていると意外と再帰を使う(使える)ことに気づいた
- いわゆる関数型言語は(命令型で)ループを使うところは高階関数か再帰で処理する
- たいてい高階関数で足りる
- 再帰は末尾再帰など面倒ポイントがある
[P.402 インターネット上の電話サービスで用いるプロトコル]{#P402}¶
- VoIP(Voice over Internet Protocol)
- IPネットワークで音声をやり取りするための技術
- データの伝送にはリアルタイム性に優れたUDPをベースとしたプロトコルが使われる
- 届かなかったらもう一度しゃべらせればいい
[P.403 その他のアプリケーション層プロトコル]{#P403}¶
- FTP:ファイルを送る。ポートは 20、21
- セキュリティが甘いので FTPS、SFTP、SCP などがある
- Telnet:(あまり使ったことない)
- SSH(Secure SHell):サーバーにログインするときに使う。とにかくよく使う。
- テキストベースの通信であるTelnetに対し,暗号化や認証技術を利用して安全に遠隔操作するためのプロトコル
- NTP・SNTP(Network Time Protocol):時刻合わせ
- LDAP(Lightweight Directory Access Protocol):ディレクトリサービスにアクセスするためのプロトコル
- Windows の ActiveDirectory も LDAP を使っている
- 社員情報をやり取りするシステム間連携で出てくる
[P.404 7.7 伝送技術]{#P404_77}¶
[P.404 誤り制御]{#P404}¶
- 誤り検出により再送を行う方法 ⇒ パリティチェック,CRC
- 誤り訂正により自己修復を行う方法 ⇒ ハミング符号
[P.404 パリティチェック]{#P404-2}¶
- 最もシンプルな検査方法
- 7 ビットのデータを送信する場合,8 ビット目に誤り検出用のパリティビットを入れてデータの整合性を検査
- 偶数パリティ:8ビットの各ビットについて"1"の数が偶数になるようにパリティビットを挿入する
- 奇数パリティ:上で奇数にする
- 有限体(ガロア体)$\mathbb{F}_2$ (ビット)で考えるといってもいい。
- 微分形式で偶数次と偶数次・偶数次と奇数の積が偶数次になり、奇数次と奇数次の積がと奇数次になるのも一種のパリティチェック。
- cf. P.405 水平垂直パリティチェック
[P.404 CRC]{#P404_CRC}¶
- CRC:巡回冗長検査(Cyclic Redundancy Check)
- 送信するデータに生成多項式を適用して誤り検出用の冗長データを作成し,それを付けて送信
- 受信側は送信側と同じ生成多項式で受信データを割り,同じ結果であればデータ誤りが\ ないと判断
- CRCでは複雑な演算を使ってバースト誤り も検出できる
- バースト誤り:データ転送回線上で連続して発生するビットの誤りのこと。ノイズの混入で生じることが多い。
- HDLC 手順が採用
[P.404 ハミング符号]{#P404-3}¶
- 上で紹介した動画で簡単に数学的な原理を紹介している
- 情報ビットに対して検査ビットをつけて 2 ビットまでの誤り検出と,1 ビットの誤り自動訂正機能をもつ誤り制御方式
- 原理的には何ビットの誤り検出・自動訂正でもできる
- 代数幾何符号もある
- 数学的にはもちろん難しい
- 有限体上の(非特異な射影)代数曲線を使う
[P.406 同期制御]{#P406}¶
- 通信時に送信側と受信側でタイミングを合わせる必要がある。
- 本の話題とは別に同期・非同期にはいろいろな話があって難しい。
- プログラミング、特に JavaScript フロントエンド周り。
- 通信待ちしていると UX を阻害するのでうまいこと非同期処理を使う
- もちろんバックエンドでもいろいろやらないといけない
- 参考:マイクロサービスにおける 非同期アーキテクチャ
- データベースの同期・非同期
- 大規模サービスでの問題、READ-WRITE、マスター・スレーブ
- ふつう読み込みに比べて書き込みは少ない
- 場合によっては読み込みは完全に最新の情報でなくてもいい
- 書き込みメインのデータベースと、その内容を適当なタイミングでもらってくる読み込み専用のデータベースがある:これがマスターとスレーブ
- 参考:前にやった Twitter のシステム構成など
- 適当な意味で完全同期していないとまずいシステムもある:銀行・金融系
- cf. トランザクション
- トランザクションはふつう銀行が例になるくらい、そちらの話が有名でしかもイメージしやすい
[P.408 7.8 交換方式]{#P408_78}¶
[P.408 パケット交換方式]{#P408}¶
- 回線交換方式と対になる概念
- 回線交換方式:通信を行うノード間で物理的な通信路を確保してから通信する
- 例:電話
- パケット交換方式について
- データ送信するノードはデータをパケットに区切る。
- ひとつひとつのパケットにヘッダを付けて送信。
- ネットワーク内ではパケット交換機にパケットがたまる
- ネットワークの状況に応じて順次送られる
[パケット通信のメリット・デメリット]{#i-10}¶
[メリット]{#i-11}¶
耐障害性\ -- 通信路を固定しないため,迂回経路が取れる。\ -- パケット交換機にデータが蓄積されているため,復旧まで待てる。
- パケット多重
- 1 対 1 の通信で回線を占有する必要がないため,1つの回線を多くのノードで共有でき,回線を効率的につかえる
- 異機種間接続性
- パケット交換機で中継するときにプロトコル変換・速度変換でエンドノードどうしが同じプロトコルをサポートしていなくても通信できる
[デメリット]{#i-12}¶
- ネットワーク内の蓄積交換処理による遅延
- 蓄積交換処理による遅延解消のために主に回線の帯域を広げることで対応してきた
- 構造上,完全には遅延をなくせない
- パケット到着順序の不整合
[P.408 ATM 交換方式]{#P408_ATM}¶
- ATM(Asynchronous Transfer Mode:非同期転送モード)
- 遅延のない回線交換方式とパケット交換方式の利点を得たい
- パケット交換方式の発展
- 遅延の原因をつぶす:特にパケットの多様性
- 多種多様なパケットに対応するために,パケット交換機はソフトウェア処理が必要\ \^ ATM での工夫の一例:最も特徴的なのは,パケット(ATMではセルという)の長さをヘッダ部 5 バイト,ペイロード 48 バイトの53バイトに統一
- パケット解析がハードウェアだけでできる。
- ソフトウェアは不要になった。
- Wikipedia から
- 当初の意図に反して非常に複雑な技術になってしまった
- ATM は次世代の主流にならず限定的な使用にとどまった
- ATM の設計思想は MPLS へと引き継がれた
- 汎用のレイヤ 2 のパケットスイッチングのプロトコルとして、ルーターを介したIPの通信網で利用されている。
[P.408 ペイロード(payload)]{#P408_payload}¶
- データ通信で本来転送したいデータ本体の部分、ボディを指す。
- ATM ではペイロードのサイズを固定して処理を簡素化
- 難点:パケット全体に占めるペイロードのサイズが相対的に小さくオーバヘッドが大きい
[P.410 輻輳]{#P410}¶
- フレームリレー:パケット交換方式の一種
- 1 つの回線を多数のユーザで共有。
- 回線がもつ潜在的な伝送能力(ワイヤスピード)を十分に引き出すうえで効果がある
- 輻輳:ユーザの利用が一時期に集中すると,ワイヤスピードを超えるパケットがネットワーク上に流れる
- ネットワークが輻輳状態になるとスループットが落ちる
- フレームリレーサービスを提供する事業者は,ネットワークが輻輳状態に陥ってスループットが低下しても最低限保証する通信速度を決めている
- CIR(Committed Information Rate:認定情\ 報速度)
P.370 7 ネットワーク]{#P370_7}¶
- 確か 7.4 から始めた気がするので 7 章はじめから
[P.370 7.1.1 OSI基本参照モデル]{#P370_711_OSI}¶
- 改めて復習
- OSI(Open System Interconnection)基本参照モデル- 異なる設計思想・世代のシステムと円滑に通信するのが目的に標準化
- プロトコルの単機能化,交換の容易さが目的
- 階層化のおかげで一部の階層の技術体系が変わっても、その階層だけ取り替えればいい
- コスト・リスクを小さくする
[P.370 プロトコルとサービス]{#P370}¶
- N 層:それぞれの階層のこと
- エンティティ:N 層に存在する通信機器などの実体
- この言葉はいろいろなところで出てきていろいろな意味で使われる
- もちろん気分的には適当な実体を指すことが多い
- プロトコル:N 層に属するエンティティが通信するための取り決め
- 上位の層が下位の層を利用しながら通信する
- 別の階層間のエンティティどうしが通信する窓口が必要
- これを提供するのが下位層:この機能をサービスと呼ぶ
- プロトコルに沿った仕様で製品を開発すれば別のベンダの機器でも通信できる
- 参考:ベンダーロックイン
特定ベンダー(メーカー)の独自技術に大きく依存した製品、サービス、システム等を採用した際に、他ベンダーの提供する同種の製品、サービス、システム等への乗り換えが困難になる現象のこと。
出来上がった情報システムの正確な仕様が、システムを開発・構築したベンダーにしか解らなくなる場合がある。結果、システムの保守・拡張・改修等の際、現存システムを開発・構築したベンダーに引き続き発注せざるを得なくなる。
- 「Excel で行政に提出する書類を作れ」事案もそれ。
- Apple 製品で身の回りを固めるのも同じ。
- 「多様性が大事」事案でもある。
[7.1.2 TCP/IPプロトコルスイート]{#712_TCPIP}¶
- プロトコル同士には相性がある
- 「ネットワーク層がこのプロトコルならトランスポート層はこのプロトコルにしておくとトラブルが少ない」
- 一般に同じ団体が作ったプロトコルはセットで使われることが多い
- このセットがプロトコルスイート\ \^ 最も代表的なのは IP を中心に組まれた TCP/IP プロトコルスイート
- 独自の階層モデルをもつ
[P.372 TCP/IPの通信]{#P372_TCPIP}¶
- データをパケットに区切る
- 各パケットにヘッダを付けて送信
- ヘッダは各階層ごとに付加されて次の階層へと渡される
- 各ヘッダにはその階層で必要となる送信元や送信先,大きさ,順番などパケット自体に関する情報を含む
- TCPヘッダを付加したパケット:TCP セグメント
- IP ヘッダを付加したパケット:IP パケット
- MACヘッダを付加したパケット:MAC フレームあるいはイーサネットフレーム
[P.372 MAC(Media Access Control)アドレス]{#P372_MACMedia_Access_Control}¶
- イーサネットや FDDI で使用される物理アドレス
- イーサネット (Ethernet):コンピューターネットワークの規格の1つ。オフィスや家庭で一般的に使用されている有線LAN (Local Area Network) の技術規格
- FDDI:LAN でデータ転送を行うための標準の一つ
- Fiber distributed data interface
- データリンク層
- 同じネットワークに接続された隣接ノード間の通信で相手を識別するために使う
- MACアドレスの長さ:6バイト
- 先頭24ビットの OUI(ベンダID)
- 後続24ビットの固有製造番号(製品に割り当てた番号)
- MAC アドレスは機器が固有にもつ番号
- 必ず一意に定まるように IEEE が管理
[P372 ポート番号]{#P372}¶
- トランスポート層にでノード内のアプリケーションの識別に使う識別子番号
- 0-65535の範囲
- TCP/IPではパケット交換方式でデータをやり取りする
- よく使われるアプリケーションについてのポート番号は Well-Known ポートとして標準化
- TCP・UDPそれぞれで 0-1023 番までの番号を割り当てている
- SSH:TCP22番
- Telnet:TCP23番
- SMTP:TCP25番
- HTTP:TCP80番
- POP3:TCP110番
- IMAP4:TCP143番
- HTTPS :TCP443番
- NTP:UDP123番
- SNMP:UDP161番
- SNMP Trap :UDP162番
- セキュリティ対策のために標準とはポート番号を変えることもある
- Web 開発の本を読んでいると、いろいろな都合から http のポートを 80 以外にしていることもよくある。
- 80 の場合はポートを指定しなくてもいい
- 例:http://localhost/hoge/fuga
- 例:http://localhost:5000/hoge/fuga
- 80 の場合はポートを指定しなくてもいい
[P.373 ネットワーク間の通信]{#P373}¶
- 同じネットワークに接続されたノード間はデータリンク層(第 2 層)の通信
- ネットワークを超えたノード間はネットワーク層(第 3 層)の通信 -実際に図 7.1.4 を見よう
- どこが IP アドレスでのやりとりか?
- どこが MAC アドレスでのやり取りか?
[P.374 7.2 ネットワーク接続装置と関連技術]{#P374_72}¶
[P.374 7.2.1 物理層の接続]{#P374_721}¶
[P.374 リピータ]{#P374}¶
- ネットワーク上を流れる電流の増幅装置・整流装置
- 物理層:第 1 層
- データ通信はネットワーク上を流れる電流
- ケーブルが長いと電流が減衰・波形が乱れが起きる
- データが読み取れなくなる
- これを増幅するのがリピータ
- 大昔の電話は距離が遠いと音が小さく聞こえにくかった
- まさにこの減衰が問題
- リピータは 1:1 で繋ぐ
- 現在では複数のノードを接続できるマルチポートリピータ(ハブ)が使われるのが一般的
[P.374 7.2.2 データリンク層の接続]{#P374_722}¶
- 第2層
[P374 ブリッジ]{#P374-2}¶
- データリンク層に位置
- ネットワーク上を流れているフレーム(情報の単位)の MAC アドレスを認識して通信を中継する
- 接続されているノードをコリジョンドメイン(セグメント)という単位に分割
- MAC アドレスで判定したフレームのあて先のあるセグメントだけにフレームを送信
- 無駄なトラフィックの回避
- ポートの記憶
- 通信のたびにある MAC アドレスをもつノードがどのポート\ に接続されているか学習
- 次回の通信時には余分なポートには通信を中継しない。
- ブリッジの動作
- あて先MACアドレスをもとにMACアドレステーブルを参照する
- あて先MACアドレスの接続ポートがフレームを受信したポー トと別ポートであれば,そのポートにフレームを送信し
- 同一ポートであればフレームを破棄する
- あて先MACアドレスが記憶されていない場合やブロードキャス\ トアドレス(FF-FF-FF-FF-FF-FF)の場合は,受信ポート以外のすべてのポートにフレームを送信する
[P.375 スイッチングハブ]{#P375}¶
- レイヤ2スイッチ(L2スイッチ)とも呼ばれる
- データリンク層に位置
- ブリッジと同じ働きをする
- MAC アドレスを認識してフレームのあて先を決めて通信を行います。
- 試験での問われ方
- スイッチングハブはフレームの蓄積機能、速度変換機能や交換機\ 能をもっている。
- このようなスイッチングハブと同等の機能をもち,同じプロトコル階層で動作する装置はどれか
- 答えは「ブリッジ」
[P.375 ブロードキャストストリーム]{#P375-2}¶
- データリンク層で動作するブリッジやスイッチングハブなどの\ LANスイッチはブロードキャストフレームを受信ポート以外\ のすべてのポートに転送
- これらの機器をループ状に接続し冗長化させると信頼性はあがる
- ブロードキャストフレームは永遠に回り続けながら増える
- 最終的にはネットワークダウンを招く
- この現象をブロードキャストストームという
- ブロードキャストストームを防ぐプロトコル:スパニングツリープロトコル(Spanning Tree Protocol:STP)
- ループを構成している一部のポートを通常運用時にはブロック(論理的に切断)する
- ネットワーク全体をループをもたない論理的なツリー構造にする
[P.376 ネットワーク層の接続]{#P376}¶
- 第 3 層(レイヤ 3)
[P.376 ルータ]{#P376-2}¶
- ルータはネットワーク層(第 3 層)に位置する
- あて先IPアドレスを見てパケットの送り先を決め通信を制御する
- IP のローカルネットワークの境界線に設置して利用され,ネットワークの基本単位として機能
- 世界中に散在しているローカルネットワークどうしをルータが結ぶ
- 全体としてインターネットというインフラが機能
- ルータで分けられたネットワークの単位をブロードキャストドメインという
- ルータがパケットを受け取ったあと
- あて先IPアドレスを見る
- 自分のネットワークあてであれば,破棄
- 他のネットワークあてであれば転送
- どのルータへ送ればあて先のネットワークへの通信が速く行えるかを判断することを経路制御(ルーティング)
- ルータはそのための経路表(ルーティングテーブル)を備えている
[P.376 デフォルトゲートウェイ]{#P376-3}¶
- 会社Aのネットワークに属するPCは会社BのPCと直接通信できない
- 会社AのPCは他ネットワークへの接点であるルータAに転送を依頼
- デフォルトゲートウェイ:会社AのPCから見て直近のルータA
- 自分と直接接続していない相手と通信するときはすべてデフォルト\ ゲートウェイを中継する
[P.376 ルーティング]{#P376-4}¶
- 経路表(ルーティングテーブル)の作成方法
- 手作業で作る:スタティックルーティング
- ルーティングプロトコル利用:ルータ同士が経路情報を交換し、自立的に経路表を作るダイナミックルーティング
- ダイナミックルーティングのための代表的なルーティングプロトコル:RIP、OSPF
- RIP:ディスタンスベクタ型(距離ベクトル型)
- ルーティングテーブルの情報(経路情報)を一定時間間隔で交換しあう
- あて先ネットワークにいたるまでに経由するルータの数(ホップ数)最小経路を選ぶ
- あて先に到達可能な最大ホップ数は 15
- これを超えた経路は採用されない
- OSPF:リンクステート型
- コストを経路選択の要素に取り入れ、コスト最小経路を選ぶ
- コスト値は,回線速度を基に自動的に算出されるが手動設定もできる
- コスト算出式「コスト=100Mbps/経路の通信帯域(bps)」
- コスト計算例は P.377 の図を見ること
[P.377 ルータの冗長構成]{#P377}¶
- ルータを冗長構成のために使うプロトコル:VRRP(Virtual Router Redundancy Protocol )
- 同じ LAN に接続された複数のルータを仮想的に 1 台のルータ\ として見えるようにして冗長構成を実現する
- 複数のルータでグループ(VRRP グループ)を作る
- VRRP グループごとに仮想 IP アドレスと仮想 MAC アドレスを割り当て
- PC などのノードは仮想ルータの IP アドレスに対して通信
- 通常時はグループのマスタルータが仮想ルータの IP アドレス(仮想 IP アドレス)を保持
- マスタルータに障害が発生すると他のバックアップルータがこれを継承
[P.377 レイヤ3スイッチ(L3スイッチ)]{#P377_3L3}¶
- ルータと同じネットワーク層(第 3 層)の通信機器
- 特徴
- ルータ:ソフトウェアで転送処理
- レイヤ 3 スイッチ:専用ハードウェアで転送処理
- 高速処理できる:大容量のファイルを扱うファイルサーバへのアクセスなど
[P.378 トランスポート層以上の層の接続]{#P378}¶
[P.378 ゲートウェイ]{#P378-2}¶
- トランスポート層(第 4 層)-アプリケーション層(第7層)でネットワーク接続するための装置
- 第 3 層のネットワーク層まででエンドツーエンド(E2E)の通信は完成する
- E2E = 通信を行う二者、あるいは、二者間を結ぶ経路全体
- エンドツーエンド原理:高度な通信制御や複雑な機能は末端のシステムが担い、経路上のシステムは単純に信号やデータの中継・転送だけすべし
- TCP/IP ネットワークの原理
- 誤り訂正・フロー制御・再送:TCP 層(第4層、トランスポート層)など上位側の機器やソフトウェア・プロトコル
- 単純な送受信・転送処理:IP 層(第3層、ネットワーク層)
- ゲートウェイ:第 4 層のトランスポート層以上が違う LAN システム相互間のプロトコル・データ形式の変換を担う
- ゲートウェイはアプリケーションプロトコルの内容を 解釈できる
- アプリケーションヘッダの不正な情報混入を検出可能
- ファイアウォール・プロキシサーバもゲートウェイの一種
[P.378 L4スイッチ・L7スイッチ]{#P378_L4L7}¶
- L4スイッチ(レイヤ4スイッチ)はトランスポート層(第4層)の装置
- 定義としてはゲートウェイ
- 機能的にはレイヤ2スイッチ・レイヤ3スイッチの延長上
- ルータやレイヤ3スイッチはIPアドレスを参照して経路制御する
- L4スイッチではTCPポート番号やUDPポート番号も経路制御判断に使える:第4層の機器だから
- L7スイッチ:アプリケーション層(第7層)までの情報を使って通信制御する
[P.379 7.2.5 VLAN]{#P379_725_VLAN}¶
- VLAN(Virtual LAN:仮想LAN)
- スイッチ(レイヤ2スイッチ,レイヤ3スイッチ)で物理的な接続形態とは独立に仮想的なLANグループを構成する仕組み,あるいはそう構成されたLAN
- 複雑な形態のネットワークを楽に構築できる
- サブネット構成も柔軟に変えられる
[P.380 データ林宗の制御とプロトコル]{#P380}¶
- データリンク層:第2層
2020-10-24 課題¶
- 先に進む前に録画してあるか確認しよう
進捗¶
- 前回の進捗
- 基礎知識編:P.408 7.8 交換方式から
- ネットワークの話に飽きてきたのでデータベースの話をする
- 本編:03-05 最急降下法の復習
- メモ:あとで 2 次元の場合のグラフなどを追加する
- 等高線が密なところは勾配が急:ここを通って最小化していく
- 基礎知識編:P.408 7.8 交換方式から
- 今回の進捗
- 基礎知識編:(ネットワークを飛ばして)「P.290 物理設計」まで
- 本編:03-05 「グラフの解説」まで
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 実際に競プロの問題をいくつか解いてみましょう。例えば次のあたりからアタックします。数学・物理系の話として、まずはマスターオブ整数を眺めてみます。今回は6. 素因数分解を活用した考察の6-4. 約数の構造を知る)を見ましょう。
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
TODO¶
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
TeX の記録¶
- 波動方程式
\begin{align} u_{tt} = \triangle u. \end{align}
競プロ、AtCoder¶
6. 素因数分解を活用した考察の6-4. 約数の構造を知る)¶
問題¶
正整数 A,B が与えられます。 A と B の正の公約数の中からいくつかを選びます。 ただし、選んだ整数の中のどの異なる 2 つの整数についても互いに素でなければなりません。 最大でいくつ選べるでしょうか。
(数値例)
・A=60
・B=72
答え:3
60 と 72 の公約数は 1, 2, 3, 4, 6, 12 の 6 個ですが、このうち 1, 3, 4 を選ぶと「どの二つも互いに素」となっています。
ポイント¶
- 2 つの整数に関する問題から 1 つの整数に関する次の問題のように書き換える
正の整数 $G$ が与えられる。$G$ の約数の中から、「どの二つも互いに素となるように」いくつか選びたい。選べる個数の最大値を求めよ。
- $G$ を素因数分解する
- $a_1 a_2 \cdots a_N= p_1^{e_1} p_2^{e_2} \cdots p_K^{e_K}$
- どの 2 つも互いに素になるように約数を取る = 各素因数だけ取ってくる
- 最大公約数が 1 の数のペアが互いに素な数のペアなので、1 をいれてもいい
- 「素因数の個数+1」が求める最大数
- 1 を含めないといけないのが割とはまりポイントになりそう。
コードの参考¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
1 2 3 | |
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- ネットワークの話もいい加減飽きたので、DB の話を先行してやるか?
復習¶
OSI基本参照モデル¶
- 会社の部署と同じ気分
- 特定層は自分のところにしか責任を持たない
- 「他の層は他の層で専門的に管轄してね」
- お互い全くの無関係ではないが、基本的には自分のことだけ考えていればいい。
いろいろなプロトコル¶
- IP, HTTP, SMTP, POP, ARP...
- 通信の規格
- 状況に応じて適切なプロトコルを選ぶ
- ヘッダ・ボディーの概念
本の記述を追いかける¶
P.408 7.8 交換方式¶
P.408 パケット交換方式¶
- 回線交換方式と対になる概念
- 回線交換方式:通信を行うノード間で物理的な通信路を確保してから通信する
- 例:電話
- パケット交換方式について
- データ送信するノードはデータをパケットに区切る。
- ひとつひとつのパケットにヘッダを付けて送信。
- ネットワーク内ではパケット交換機にパケットがたまる
- ネットワークの状況に応じて順次送られる
パケット通信のメリット・デメリット¶
メリット¶
耐障害性 - 通信路を固定しないため,迂回経路が取れる。 - パケット交換機にデータが蓄積されているため,復旧まで待てる。 - パケット多重 - 1 対 1 の通信で回線を占有する必要がないため,1つの回線を多くのノードで共有でき,回線を効率的につかえる - 異機種間接続性 - パケット交換機で中継するときにプロトコル変換・速度変換でエンドノードどうしが同じプロトコルをサポートしていなくても通信できる
デメリット¶
- ネットワーク内の蓄積交換処理による遅延
- 蓄積交換処理による遅延解消のために主に回線の帯域を広げることで対応してきた
- 構造上,完全には遅延をなくせない
- パケット到着順序の不整合
P.408 ATM 交換方式¶
- ATM(Asynchronous Transfer Mode:非同期転送モード)
- 遅延のない回線交換方式とパケット交換方式の利点を得たい
- パケット交換方式の発展
- 遅延の原因をつぶす:特にパケットの多様性
- 多種多様なパケットに対応するために,パケット交換機はソフトウェア処理が必要 ^ ATM での工夫の一例:最も特徴的なのは,パケット(ATMではセルという)の長さをヘッダ部 5 バイト,ペイロード 48 バイトの53バイトに統一
- パケット解析がハードウェアだけでできる。
- ソフトウェアは不要になった。
- Wikipedia から
- 当初の意図に反して非常に複雑な技術になってしまった
- ATM は次世代の主流にならず限定的な使用にとどまった
- ATM の設計思想は MPLS へと引き継がれた
- 汎用のレイヤ 2 のパケットスイッチングのプロトコルとして、ルーターを介したIPの通信網で利用されている。
P.408 ペイロード(payload)¶
- データ通信で本来転送したいデータ本体の部分、ボディを指す。
- ATM ではペイロードのサイズを固定して処理を簡素化
- 難点:パケット全体に占めるペイロードのサイズが相対的に小さくオーバヘッドが大きい
P.410 輻輳¶
- フレームリレー:パケット交換方式の一種
- 1 つの回線を多数のユーザで共有。
- 回線がもつ潜在的な伝送能力(ワイヤスピード)を十分に引き出すうえで効果がある
- 輻輳:ユーザの利用が一時期に集中すると,ワイヤスピードを超えるパケットがネットワーク上に流れる
- ネットワークが輻輳状態になるとスループットが落ちる
- フレームリレーサービスを提供する事業者は,ネットワークが輻輳状態に陥ってスループットが低下しても最低限保証する通信速度を決めている
- CIR(Committed Information Rate:認定情 報速度)
P.370 7 ネットワーク¶
- 確か 7.4 から始めた気がするので 7 章はじめから
P.370 7.1.1 OSI基本参照モデル¶
- 改めて復習
- OSI(Open System Interconnection)基本参照モデル- 異なる設計思想・世代のシステムと円滑に通信するのが目的に標準化
- プロトコルの単機能化,交換の容易さが目的
- 階層化のおかげで一部の階層の技術体系が変わっても、その階層だけ取り替えればいい
- コスト・リスクを小さくする
P.370 プロトコルとサービス¶
- N 層:それぞれの階層のこと
- エンティティ:N 層に存在する通信機器などの実体
- この言葉はいろいろなところで出てきていろいろな意味で使われる
- もちろん気分的には適当な実体を指すことが多い
- プロトコル:N 層に属するエンティティが通信するための取り決め
- 上位の層が下位の層を利用しながら通信する
- 別の階層間のエンティティどうしが通信する窓口が必要
- これを提供するのが下位層:この機能をサービスと呼ぶ
- プロトコルに沿った仕様で製品を開発すれば別のベンダの機器でも通信できる
- 参考:ベンダーロックイン
特定ベンダー(メーカー)の独自技術に大きく依存した製品、サービス、システム等を採用した際に、他ベンダーの提供する同種の製品、サービス、システム等への乗り換えが困難になる現象のこと。
出来上がった情報システムの正確な仕様が、システムを開発・構築したベンダーにしか解らなくなる場合がある。結果、システムの保守・拡張・改修等の際、現存システムを開発・構築したベンダーに引き続き発注せざるを得なくなる。
- 「Excel で行政に提出する書類を作れ」事案もそれ。
- Apple 製品で身の回りを固めるのも同じ。
- 「多様性が大事」事案でもある。
7.1.2 TCP/IPプロトコルスイート¶
- プロトコル同士には相性がある
- 「ネットワーク層がこのプロトコルならトランスポート層はこのプロトコルにしておくとトラブルが少ない」
- 一般に同じ団体が作ったプロトコルはセットで使われることが多い
- このセットがプロトコルスイート ^ 最も代表的なのは IP を中心に組まれた TCP/IP プロトコルスイート
- 独自の階層モデルをもつ
P.372 TCP/IPの通信¶
- データをパケットに区切る
- 各パケットにヘッダを付けて送信
- ヘッダは各階層ごとに付加されて次の階層へと渡される
- 各ヘッダにはその階層で必要となる送信元や送信先,大きさ,順番などパケット自体に関する情報を含む
- TCPヘッダを付加したパケット:TCP セグメント
- IP ヘッダを付加したパケット:IP パケット
- MACヘッダを付加したパケット:MAC フレームあるいはイーサネットフレーム
P.372 MAC(Media Access Control)アドレス¶
- イーサネットや FDDI で使用される物理アドレス
- イーサネット (Ethernet):コンピューターネットワークの規格の1つ。オフィスや家庭で一般的に使用されている有線LAN (Local Area Network) の技術規格
- FDDI:LAN でデータ転送を行うための標準の一つ
- Fiber distributed data interface
- データリンク層
- 同じネットワークに接続された隣接ノード間の通信で相手を識別するために使う
- MACアドレスの長さ:6バイト
- 先頭24ビットの OUI(ベンダID)
- 後続24ビットの固有製造番号(製品に割り当てた番号)
- MAC アドレスは機器が固有にもつ番号
- 必ず一意に定まるように IEEE が管理
P372 ポート番号¶
- トランスポート層にでノード内のアプリケーションの識別に使う識別子番号
- 0-65535の範囲
- TCP/IPではパケット交換方式でデータをやり取りする
- よく使われるアプリケーションについてのポート番号は Well-Known ポートとして標準化
- TCP・UDPそれぞれで 0-1023 番までの番号を割り当てている
- SSH:TCP22番
- Telnet:TCP23番
- SMTP:TCP25番
- HTTP:TCP80番
- POP3:TCP110番
- IMAP4:TCP143番
- HTTPS :TCP443番
- NTP:UDP123番
- SNMP:UDP161番
- SNMP Trap :UDP162番
- セキュリティ対策のために標準とはポート番号を変えることもある
- Web 開発の本を読んでいると、いろいろな都合から http のポートを 80 以外にしていることもよくある。
- 80 の場合はポートを指定しなくてもいい
- 例:http://localhost/hoge/fuga
- 例:http://localhost:5000/hoge/fuga
- 80 の場合はポートを指定しなくてもいい
P.373 ネットワーク間の通信¶
- 同じネットワークに接続されたノード間はデータリンク層(第 2 層)の通信
- ネットワークを超えたノード間はネットワーク層(第 3 層)の通信 -実際に図 7.1.4 を見よう
- どこが IP アドレスでのやりとりか?
- どこが MAC アドレスでのやり取りか?
P.374 7.2 ネットワーク接続装置と関連技術¶
P.374 7.2.1 物理層の接続¶
P.374 リピータ¶
- ネットワーク上を流れる電流の増幅装置・整流装置
- 物理層:第 1 層
- データ通信はネットワーク上を流れる電流
- ケーブルが長いと電流が減衰・波形が乱れが起きる
- データが読み取れなくなる
- これを増幅するのがリピータ
- 大昔の電話は距離が遠いと音が小さく聞こえにくかった
- まさにこの減衰が問題
- リピータは 1:1 で繋ぐ
- 現在では複数のノードを接続できるマルチポートリピータ(ハブ)が使われるのが一般的
P.374 7.2.2 データリンク層の接続¶
- 第2層
P374 ブリッジ¶
- データリンク層に位置
- ネットワーク上を流れているフレーム(情報の単位)の MAC アドレスを認識して通信を中継する
- 接続されているノードをコリジョンドメイン(セグメント)という単位に分割
- MAC アドレスで判定したフレームのあて先のあるセグメントだけにフレームを送信
- 無駄なトラフィックの回避
- ポートの記憶
- 通信のたびにある MAC アドレスをもつノードがどのポート に接続されているか学習
- 次回の通信時には余分なポートには通信を中継しない。
- ブリッジの動作
- あて先MACアドレスをもとにMACアドレステーブルを参照する
- あて先MACアドレスの接続ポートがフレームを受信したポー トと別ポートであれば,そのポートにフレームを送信し
- 同一ポートであればフレームを破棄する
- あて先MACアドレスが記憶されていない場合やブロードキャス トアドレス(FF-FF-FF-FF-FF-FF)の場合は,受信ポート以外のすべてのポートにフレームを送信する
P.375 スイッチングハブ¶
- レイヤ2スイッチ(L2スイッチ)とも呼ばれる
- データリンク層に位置
- ブリッジと同じ働きをする
- MAC アドレスを認識してフレームのあて先を決めて通信を行います。
- 試験での問われ方
- スイッチングハブはフレームの蓄積機能、速度変換機能や交換機 能をもっている。
- このようなスイッチングハブと同等の機能をもち,同じプロトコル階層で動作する装置はどれか
- 答えは「ブリッジ」
P.375 ブロードキャストストリーム¶
- データリンク層で動作するブリッジやスイッチングハブなどの LANスイッチはブロードキャストフレームを受信ポート以外 のすべてのポートに転送
- これらの機器をループ状に接続し冗長化させると信頼性はあがる
- ブロードキャストフレームは永遠に回り続けながら増える
- 最終的にはネットワークダウンを招く
- この現象をブロードキャストストームという
- ブロードキャストストームを防ぐプロトコル:スパニングツリープロトコル(Spanning Tree Protocol:STP)
- ループを構成している一部のポートを通常運用時にはブロック(論理的に切断)する
- ネットワーク全体をループをもたない論理的なツリー構造にする
P.376 ネットワーク層の接続¶
- 第 3 層(レイヤ 3)
P.376 ルータ¶
- ルータはネットワーク層(第 3 層)に位置する
- あて先IPアドレスを見てパケットの送り先を決め通信を制御する
- IP のローカルネットワークの境界線に設置して利用され,ネットワークの基本単位として機能
- 世界中に散在しているローカルネットワークどうしをルータが結ぶ
- 全体としてインターネットというインフラが機能
- ルータで分けられたネットワークの単位をブロードキャストドメインという
- ルータがパケットを受け取ったあと
- あて先IPアドレスを見る
- 自分のネットワークあてであれば,破棄
- 他のネットワークあてであれば転送
- どのルータへ送ればあて先のネットワークへの通信が速く行えるかを判断することを経路制御(ルーティング)
- ルータはそのための経路表(ルーティングテーブル)を備えている
P.376 デフォルトゲートウェイ¶
- 会社Aのネットワークに属するPCは会社BのPCと直接通信できない
- 会社AのPCは他ネットワークへの接点であるルータAに転送を依頼
- デフォルトゲートウェイ:会社AのPCから見て直近のルータA
- 自分と直接接続していない相手と通信するときはすべてデフォルト ゲートウェイを中継する
P.376 ルーティング¶
- 経路表(ルーティングテーブル)の作成方法
- 手作業で作る:スタティックルーティング
- ルーティングプロトコル利用:ルータ同士が経路情報を交換し、自立的に経路表を作るダイナミックルーティング
- ダイナミックルーティングのための代表的なルーティングプロトコル:RIP、OSPF
- RIP:ディスタンスベクタ型(距離ベクトル型)
- ルーティングテーブルの情報(経路情報)を一定時間間隔で交換しあう
- あて先ネットワークにいたるまでに経由するルータの数(ホップ数)最小経路を選ぶ
- あて先に到達可能な最大ホップ数は 15
- これを超えた経路は採用されない
- OSPF:リンクステート型
- コストを経路選択の要素に取り入れ、コスト最小経路を選ぶ
- コスト値は,回線速度を基に自動的に算出されるが手動設定もできる
- コスト算出式「コスト=100Mbps/経路の通信帯域(bps)」
- コスト計算例は P.377 の図を見ること
P.377 ルータの冗長構成¶
- ルータを冗長構成のために使うプロトコル:VRRP(Virtual Router Redundancy Protocol )
- 同じ LAN に接続された複数のルータを仮想的に 1 台のルータ として見えるようにして冗長構成を実現する
- 複数のルータでグループ(VRRP グループ)を作る
- VRRP グループごとに仮想 IP アドレスと仮想 MAC アドレスを割り当て
- PC などのノードは仮想ルータの IP アドレスに対して通信
- 通常時はグループのマスタルータが仮想ルータの IP アドレス(仮想 IP アドレス)を保持
- マスタルータに障害が発生すると他のバックアップルータがこれを継承
P.377 レイヤ3スイッチ(L3スイッチ)¶
- ルータと同じネットワーク層(第 3 層)の通信機器
- 特徴
- ルータ:ソフトウェアで転送処理
- レイヤ 3 スイッチ:専用ハードウェアで転送処理
- 高速処理できる:大容量のファイルを扱うファイルサーバへのアクセスなど
P.378 トランスポート層以上の層の接続¶
P.378 ゲートウェイ¶
- トランスポート層(第 4 層)-アプリケーション層(第7層)でネットワーク接続するための装置
- 第 3 層のネットワーク層まででエンドツーエンド(E2E)の通信は完成する
- E2E = 通信を行う二者、あるいは、二者間を結ぶ経路全体
- エンドツーエンド原理:高度な通信制御や複雑な機能は末端のシステムが担い、経路上のシステムは単純に信号やデータの中継・転送だけすべし
- TCP/IP ネットワークの原理
- 誤り訂正・フロー制御・再送:TCP 層(第4層、トランスポート層)など上位側の機器やソフトウェア・プロトコル
- 単純な送受信・転送処理:IP 層(第3層、ネットワーク層)
- ゲートウェイ:第 4 層のトランスポート層以上が違う LAN システム相互間のプロトコル・データ形式の変換を担う
- ゲートウェイはアプリケーションプロトコルの内容を 解釈できる
- アプリケーションヘッダの不正な情報混入を検出可能
- ファイアウォール・プロキシサーバもゲートウェイの一種
P.378 L4スイッチ・L7スイッチ¶
- L4スイッチ(レイヤ4スイッチ)はトランスポート層(第4層)の装置
- 定義としてはゲートウェイ
- 機能的にはレイヤ2スイッチ・レイヤ3スイッチの延長上
- ルータやレイヤ3スイッチはIPアドレスを参照して経路制御する
- L4スイッチではTCPポート番号やUDPポート番号も経路制御判断に使える:第4層の機器だから
- L7スイッチ:アプリケーション層(第7層)までの情報を使って通信制御する
P.379 7.2.5 VLAN¶
- VLAN(Virtual LAN:仮想LAN)
- スイッチ(レイヤ2スイッチ,レイヤ3スイッチ)で物理的な接続形態とは独立に仮想的なLANグループを構成する仕組み,あるいはそう構成されたLAN
- 複雑な形態のネットワークを楽に構築できる
- サブネット構成も柔軟に変えられる
P.380 データリンク層の制御とプロトコル¶
- データリンク層:第2層
P.380 7.3.1 メディアアクセス制御¶
- 複数のデータを1つのケーブルを通して送受する場合,データの衝突(コリジョン)を回避するための制御が必要
- これがメディアアクセス制御(Media Access Control:MAC)
コリジョン(衝突)¶
イーサネットや無線LANで複数の端末が送信し、データが衝突する現象を指す。旧式のイーサネット規格では、端末同士を接続するときに1組の通信路で双方向の通信を行う半二重通信のため、送信と受信を同時に行うことができない。送信と受信をその都度切り替えて行うので、端末がお互いデータを送信してしまうと衝突する可能性が高くなる。
P.380 CSMA/CD¶
- CSMA/CD:Carrier Sense Multiple Access with Collision Detection:搬送波感知多重アクセ ス/衝突検出)の略。
- イーサネットで採用されている方式
- 衝突検知方式を採用
- イーサネット:IEEE 802.3として標準化されている LAN規格
- CSMA/CD
- 各ノードは伝送媒体が使用中かどうかを調べて,使用中でなければデータを送りはじめる
- 複数のノードが同時に通信しはじめるとデータの衝突が起こる
- 衝突を検知し,一定時間(ランダム)待った後で,再送
- 一定の距離以上のケーブルでは衝突が検知できない
- CSMA/CD方式の限界
- トラフィックが増加するにつれて衝突が多くなる
- 再送が増え,さらにトラフィックが増加する悪循環に陥る可能性がある
- 特に伝送路の使用率が30%を超えると実用的でなくなる
P.381トークンパッシング方式¶
- トークンによる送信制御を行う方式で
- トークンバス方式
- トークンリング方式
P.381 トークンパッシング方式¶
- ネットワーク上をフリートークンと呼ばれる送信権のためのパケットが巡回する
- フリートークンを獲得したノードだけが送信できるので衝突を避けられる
- ふつうはコンセントレータ(集線器)でネットワ ークとノードを結ぶ
- トークンパッシング方式を採用したLAN規格
- 例:FDDI:Fiber Distributed Data Interface
- FDDIは物理媒体に光ファイバを利用し,最大100Mビ ッ ト/秒の通信
- 特徴
- 伝送媒体上では衝突しない
- トラフィックが増えるにつれてトークンを獲得しにくくなり,少しずつ遅延時間が増える
- 衝突による再送制御の必要がないため伝送路の使用率に対する遅延時間の増加率はCSMA/CD方式より緩やか
P.382 TDMA 方式¶
- TDM(時分割多重)
- ネットワーク上にデータを送信する時間を割 り当てる(タイムスロット)
- タイムスロットごとに別のデータを送って多重化する
- TDM によるアクセス制御が TDMA
- TDMA(Time Division Multiple Access:時分割多重アクセス)
- CSMA/CD・トークンパッシング方式と並ぶ主要なデー タリンク技術
- TDMA ではネットワーク(伝送路)を使える時間を細かく区切る
- 割り当てられた時間は各ノードが独占する方式
- TDMAはコネクション型の通信
P.382 7.3.2 無線LANのアクセス制御方式¶
P.382 CSMA/CA方式¶
- CSMA/CA:Carrier Sense Multiple Access with Collision Avoidance、搬送波感知多重アクセス/衝突回避
- 無線 LAN の制御方式
- CSMA/CD との違い:「衝突検出」が「衝突回避」になった
- 無線 LAN:物理層媒体は電波で衝突の検出は不可能だから回避する
- 特徴
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
- 待ち時間をバックオフ制御時間とよぶ
- 衝突してフレームが壊れても検出できない
- データを受け取ったノードは ACK を返す
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
P.328 RTS/CTS¶
- 無線 LAN の話
- 隠れ端末問題
- 他のノードのデータ送信を感知できないことがある
- 通信ノード間の距離が遠い
- ノード間に障害物がある
- 回避のための RTS/CTS 方式
- 無線 LAN ノード
- データ送信前にRTS(Request ToSend:送信リクエスト)をアクセスポイントに送信
- これを受理したアクセスポイントがCTS(Clear to Send:送信OK)を返信
- 他のノードは CTS を傍受して自分以外の別のノードに送信権があると解釈
- データ送信を延期
- 無線LANノードはアクセスポイントからCTSを受信したらデータ送信開始します
- 衝突抑制:CTSに書かれた他のノードに対する送信抑制時間を使う
- データ送信開始前にデータ送信のネゴシエーシ ョンとして RTS/CTS 方式を使った CSMA/CA を CSMA/CA with RTS/CTS とよぶ
P.383 無線LANの動作モード¶
- 無線 LAN の動作モード:図7.3.4参照
- 2 つのモードがある
- インフラストラクチャモード:無線LANノードがアク セスポイントを通じて相互に通信
- アドホックモード:アクセスポイントなしに無線LANノードどうしが直接通信
P.383 COLUMN FDMA,CDMA¶
- 表7.3.1:多元接続する技術グループ
- TDMA とセット
- FDMA
- ある周波数帯をさらに細かい周波数帯に分割
- 接続できる端末数を増やす技術
- CDMA
- 周波数も時間も分割しない
- 符号で各端末の通信を識別・分離
- 接続できる端末数を増やす
P.383 7.3.3 データリンク層の主なプロトコル¶
- 第 2 層
P.384 ARP¶
- ARP(Address Resolution Protocol):通信相手のIPアドレスからMACアドレスを取るためのプロトコル
- ARPの動作
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- ブロードキャスト:ネットワークに参加するすべての機器に同時に信号やデータを送ること
- 各ノードは自分のIPアドレスと比較
- 一致したノードだけARP応答パケットに自分のMACアドレスを入れて返す(ユニキャスト)
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- 参考:GARP(Gratuitous ARP)
- 主な目的:自身に設定するIPアドレスの重複確認・ARPテ ーブルの更新
- 目的IPアドレスに自身が使うIPアドレスを指定し,MACアドレスを問い合わせる
P.384 RARP¶
- Reverse-ARP:逆アドレス解決プロトコル
- MACアドレスからIPアドレスを取る
- 電源オフ時にIPアドレスを保持できない(IPアドレスを保持するハードディスクをもたない)機器が電源オン時に自分のMACアドレスから自身に割り当てられているIPアドレスを知るために使う
- RARP サーバー
- MACアドレスとIPアドレスの対応表を持ったサーバー(RARPサーバー)が必要
P.384 PPP¶
- PPP:Point to Point Protocol
- 2 点間をポイントツーポイントでつなぐためのデータリンクプロトコル
- WANを介して2つのノードをダイヤルアップ接続するときに使う
- ネットワーク層(第3層)とネゴシエーションする NCP(ネットワーク制御プロトコル)とリンクネゴシエーションするLCP(リンク制御プロトコル)からなる
- NCP:Network Control Protocol
- LCP:Link Control Protocol
- リンク制御やエラー処理機能を持つ
P.384 PPPoE¶
- PPPoE:PPP over Ethernet
- PPPと同等な機能をイーサネット(LAN)上で実現するプロトコル
- PPPフレームをイーサネットフレームでカプセル化して実現
P.384 7.3.4 IEEE 802.3規格¶
- メディアアクセス制御に CSMA/CD 方式を使う LAN についての標準
- OSI基本参照モデルにおけるデータリンク層(第 2 層)と物理層(第 1 層)のプロトコルおよびサービスを規定
- OSI 基本参照モデルでのデータリンク層を LLC 副層と MAC 副層の2つに分割
- 物理層での LAN で使う伝送媒体や MAC 副層でのフレーム構成や衝突検出の仕組みを規定
- ツイストケーブルの企画が表 7.3.2 にまとまっている
P.386 7.4 ネットワーク層のプロトコルと技術¶
- もうやった
P.286 6.1 データベースの基礎¶
P.286 6.1.1 データベースの種類¶
- 代表的なデータベース
- 階層型データベース
- 網型データベース
- 関係データベース
- 関係データベースが一番よく使われている
- MySQL (MariaDB), PostgreSQL, SQL Server, Oracle
- (疑問)いわゆる NoSQL はどれなのだろうか?
- redis, mongoDB, memcache
P.286 階層型データベース¶
- (具体的なデータベース名(製品名)を知らない)
- 階層構造(木構造)でデータの構造を表現
- レコードどうしが親子関係をもつ
- ある親レコードに対する子レコードは 1 つ以上存在
- 子レコードに対する親レコードはただ1つ
- データの操作
- 親レコードと子レコードを結ぶポインタをたどる
P.286 網型データベース¶
- ネットワーク型データベースとも
- 親レコードと子レコードに「多対多」の関係がある
- 親レコードは複数の子レコードをもてる
- 子レコードは複数の親レコードをもてる
- データの操作
- 親レコードと子レコードを親子組(セット)
- 親子間や兄弟間のリンクをたどって 1 つのデータを取り出す
P.287 関係データベース¶
- データの集合を平坦な2次元の表で表現:リレーショナルデータベースとも
- 親レコード・子レコードという概念をもたない
- レコード間を結ぶポインタやリンクがない
- データ操作の結合でレコードを関連づける
- 1 つの表の 1 つの行と別の表との関連づけ
- 数学の集合概念に基礎をおく
- 値の一致(たとえば,外部キーと主キー)による
P.288 6.1.2 データベースの設計¶
- プロの技
P.288 データベースの設計プロセス¶
- 「概念設計→論理設計→物理設計」の順
- ER 図、関係モデル
P.288 概念設計¶
- 所有データを調査・分析して抽象化した概念データモデルを作る
- まずはデータのもつ意味やデータ間の関係を崩さずあるがままに表現する
- 概念データモデルは単純にデータのもつ意味とその関係を表したモデル
- コンピュータへの実装とは独立の、特定の DBMS に依存しないデータモデル
- DBMS:DataBase Management System、データベース管理システム
- E-Rモデル:EntityRelationship Model、エンティティリレーションシップモデル
- cf.P.292, 6.1.4
- UML のクラス図
- cf. P.496, 9.3.4
P.288 データ分析¶
- 概念設計のデータ分析
- 洗い出しが大事
- どのようなデータがあるのか
- 必要なデータはなにか
- 2 つの大きな目的
- 異音同義語(シノニム)や同名異義語(ホモニム)の排除
- 複数箇所に存在する同一内容データ(データ重複)の排除
- 手法
- データ項目を標準化
- 正規化:データ項目間の関連を明確にする
P.289 POINT データ項目洗出しの留意点¶
- 簡単なアプリ作成をしてみると気分がつかめる
- もしくは具体的なアプリのデータベース設計に関する本を読んでみる
- データ項目名の標準化
- データ項目の意味の定義
- "日付"・"年月日" の 2 つの項目をどう扱うか
- 別物ならデータ項目を定義して本当に別の実体にする
- データ項目のけた数や型の統一
- 型:文字列、日付型、数値、TEXT、バイナリなどなど
- 各データ項目の発生源や発生量の明確化
P.289 トップダウンアプローチとボトムアップアプローチ¶
- データの分析手法
- トップダウンアプローチ:最初に理想型の概念データモデルを作ってからデータ分析する
- ボトムアップアプローチ:画面や帳票などから項目を洗い出してデータ分析した結果として現実的な概念データモデルを作る
- 最終的なデータモデルへの要求事項
- 適切な正規化
- 正規化にもいくつかの段階がある
- いろいろな状況に応じて完全な正規化をしないこともある
- 例えばバッチ集計すると時間がかかりすぎる場合、あえて正規化を崩す
- 業務上のデータ項目をすべて持つ
- 適切な正規化
- どちらかだけで済むことはない
- 主に後者で組んだ上で前者の視点で見直すなど
- 業務・状況に応じて適切な方法を使う・組み合わせる
P.289 論理設計¶
- E-R 図などで表現された概念データモデルはそのままではデータベースに実装できない
- 概念データモデルを論理データモデルに変換する
- 階層モデル,ネットワーク(網)モデル,関係モデルの 3 つ
- それぞれのDBMSの制約に合わせて変換
- 関係データベース
- 概念データモデルを基に主キーや外部キーを含めたテーブル構造を作る
- テーブルの各列(データ項目)に設定される制約を検討
- 処理・利用しやすいようなビュー設計も必要
- ビュー(P.325 参照):データベースの実表のうち,利用者が必要とするものだけを利用に適した形で表として定義したもの
- SELECT 文を呼びやすくするために名前をつけただけ
P.290 物理設計¶
- 実際にデータベース内にデータ実装するときの注意
- 論理データモデルに基づいた特定のデータベース管理システム(DBMS)でデータ量・データの利用頻度・パフォーマンス・運用を考えてデータベースの物理的構造を決める
- データ量:初期データ量,増加度合い
- 利用頻度:トランザクション発生頻度,トランザクション種類(検索,更新)など
- 前に Twitter のシステムの話で紹介した事案
- 論理データモデルに基づいた特定のデータベース管理システム(DBMS)でデータ量・データの利用頻度・パフォーマンス・運用を考えてデータベースの物理的構造を決める
- 論理設計:データベースの見かけ上の設計
- 物理設計:実際に磁気ディスク上に記憶される形式などの具体的な設計
P.290 6.1.3 データベースの3層スキーマ¶
P.290 スキーマ¶
- schema
- データの性質・形式・ほかのデータとの関連などデータ定義の集合
P.290 ANSI/SPARC3層スキーマ¶
- データベースの3層スキーマ
- データを扱う立場を3つのグループに分け,それぞれに対応したデータ定義するためのモデル
- 目的:次の2点の確立
- 論理データ独立性:論理的なデータと利用者やアプリケーションプログラムから見たデータとの独立
- 物理データ独立性:記憶装置との独立
- cf. P.291 の図。
- 外部スキーマ
- 利用者やアプリケーションプログラムから見たデータを定義
- 実世界が変化するとそれに合わせて概念スキーマは変わる
- アプリケーションプログラムが影響を受けないようにするためにするためのスキーマ
- 例:関係データベースのビュー
- 概念スキーマ
- 実際のデータの物理的な表現方法とは別
- データベースの論理的構造とその内容を定義
- 例:論理設計段階の論理データモデル
- 内部スキーマ
- データを記憶装置上にどのような形式や編成で記録するか、物理的内容の定義
- 障害回復処理(リカバリ),セキュリティなども考えた実際にコンピュータに実装させる格納表現
P.291 COLUMN インメモリデータベース¶
- データを直接メモリに配置してパフォーマンスを上げる
- キャッシュとして使われることもよくある
- DB の基本はあくまでディスクにデータを記録してメモリに読み込む
- ディスク入出力がボトルネック
- 前に紹介した速度表を参照すること
- インメモリデータベースではディスク入出力がない
- 基本の処理がメモリ上で閉じるので処理が速い
- 最近のインメモリデータベースの傾向
- データをカラム(列)型フォーマットでメモリに配置する列指向(カラム指向)を採用
- 集計や分析処理などのクエリが高速化します
- 欠点
- 揮発性:メモリ上のデータは電源を切ると失われてしまう
- 何かの事故が起きたらデータが(すべて)飛ぶ
- HDD・SDD よりもメモリは高い
- 対策
- データを定期的にディスクに保存する機能
- 別のスタンバイデータベースにデータの複製を取るレプリケーション機能
P.292 6.1.4 E-R図¶
- 実世界にあるデータ構造をなるべくそのまま表現したい
- データベース管理システムに依存しないデータモデルを作りたい
- ER 図:E-Rモデルを図で表現
- Entity-Relationship Diagram
P.292 E-R図の構成要素¶
- エンティティ:データベース化の対象となる実世界を構成する実体
- 大きく分けて 2 種類
- 物理的実体がある:顧客、商品など
- 物理的実体がない:顧客と購入商品の「関係」そのもの:後の例参照
- RDB の例をいろいろ見るとわかる
- アトリビュート:エンティティがもつその性質や特徴を表すいくつかの属性
- 例:顧客エンティティ
- 顧客番号,顧客名
- 識別子:エンティティを一意に識別するための属性
- いわゆる ID:関係データベースの表の主キー
- 例:顧客番号
- 内部 ID と外部(?)ID がある。
- 内部 ID:システム内で固定の ID。よく数値を使う
- 外部(?)ID:ログイン ID などユーザーが決める ID。
- メールアドレスなどある時点では一意。
- ユーザーが変更できるのでシステム内でその値を永続的に使えない
- 関連(リレーションシップ):業務上の規則やルールなどによって発生するエンティティ間の関係
- 顧客はいくつもの商品を注文する
- カーディナリティ:エンティティ間の「1対1」、「1対 多 」、「 多 対 多 」といった対応関係の表現
- 数学で基数・濃度を cardinal number というその cardinal
P.292 「多対多」の関係¶
- 「多対多」の関係は,関係データベースとして実装できない
- 「1対多」と「多対1」の関係に分解する
- リレーションシップそれ自体を1つのエンティティとする
- 図 6.1.8 参照
- 識別子に顧客エンティティの識別子(顧客番号)と商品エンティティの識別子(商品番号)をもたせる
- 顧客と注文の関係は「1対多」、注文と商品の関係は「多対1」の関係
- このときの「注文」を連関エンティティと呼ぶ
- 注意:リレーションシップも属性をもつ
- 例:注文日、注文数量
- 顧客と商品の両方が特定されてはじめて確定する概念
- 例:注文日、注文数量
P.292 独立エンティティと依存エンティティ¶
- エンティティ間に「1対多」の関係があるとき
- 「多」側のエンティティは「1」側のエンティティの識別子を外部キーとしてもつ
- 外部キーがまさに RDB の R
- 外部キーが識別子の一部となる場合、そのエンティティは「1」側のエンティティに依存する
- cf. P.292 図6.1.8 の注文エンティティ
- 注文はある顧客がある商品を注文するという概念
- 顧客番号と商品番号がないと存在できない
- これを依存エンティティ(弱実体)と呼ぶ
- これを独立化したければしてもいい
- 注文番号を導入
- 注文エンティティを図 6.1.9 のように捉える
- 親エンティティに依存しない独立エンティティ (強実体)とみなせる
- 「発注書に ID を振りたい」といった要望も多いはずで、よくある対応
- 独立化させる必要がないケースの例も見てみよう
- e-ラーニングでの受講履歴
- 「誰がどのコースのどの単元を受講したか」
- 特に ID を振って独立に管理したいわけではない
- いつ何を受講してどういう結果だったか(テスト系ならどの問題にどう回答して正否はどうか)といったことは知りたい
P.294 6.2 関係データベース¶
P.294 6.2.1 関係データベースの特徴¶
- 関係データベース:RDB(Relational DataBase)
- 1970年 E.F.コッド博士によって提案された関係モデルをもとにしたデータベース
- 現在,最も多く使われているデータベース
- 一応集合論をもとにしているらしいが、集合論を知らなくても全く問題ない
- 計算機科学の専門家は集合を勉強しないと駄目らしいという事案ではある模様
P.294 関係データベースの構造¶
- 意味的にひとまとまりのデータを 2 次元の平坦な表で表す
- 列が「あるユーザの情報」
- 行が「ある属性の情報」:名前やメールアドレス
- 表に格納されるデータ:単位は次の通り
- 行(組、タプル)
- 列(属性、アトリビュート)
- 2 次元の平坦な表
- 行と列が交差する 1 つのマスには 1 つの値しか入らない
- 「1 つの値」とはいうが、JSON を叩き込むこともある
- 参考
- インデックスが張れず検索のパフォーマンスは厳しいので、検索したいなら JSON を張るのはやめた方がいい
- NoSQL だと列そのものが JSON だったりもする
- 第 1 正規形:cf. P.300 6.3.2
- 行と列が交差する 1 つのマスには 1 つの値しか入らない
次数と基数¶
- (この言葉を使った記憶がない)
- 次数:1 組のデータを表す行を構成する列の数
- 基数:1 つの表を構成する行の数
- テーブルを集合とみなしたときの要素数
- 本曰く「次数は変わることはありません」
- テーブル定義を変えると変わる
- 実際にテーブル定義を変えることはよくある:特に開発中は。
- 機能追加・改修案件で追加されることもよくある
- 1 行は 1 組のデータを表す:表に対するデータの追加・削除で基数はよく変わる
P.295 定義域(ドメイン)¶
- テーブル全体を $\mathcal{T} = A \times B \times \cdots \times Z$ と書いたときの各 $A,B,\dots,Z$ をドメイン(定義域、domain)と呼ぶ
- 数学の集合と違って $\mathcal{T}$ の中に同じ集合を含まない:つまり $\mathcal{T} = \mathbb{R}^n$ といったテーブルは考えない
- ドメインは「属性が取り得る値の集合」
- RDB では適当なデータ型を対応させる:日付,金額,数量,量
- ドメインを新たなデータ型として定義すると違うデー タ項目でも同じ入力チェックや同じ出力編集ができる
P.296 6.2.2 関係データベースのキー¶
- 表中の行を一意に識別するためのキー(スーパキー,候補キー,主キー)
- 別の表を参照し関連づけるための外部キー
P.296 スーパキー¶
- 表中の行を一意に特定できる属性,あるいは属性の組
- 組について:購入履歴を知るためにはユーザーID・商品ID・購入日がわからないといけない、という程度の意味
- かなり広い意味のようなのでたぶんそんなに使わない
- 補足:なぜスーパ「ー」キーではないのか
- 参考
- JIS の規格がある
- その言葉が 3 音以上の場合には,語尾に長音符号を付けない:ブラウザ、プリンタ、スキャナ、ドライバ、フォルダ、モニタなど
- その言葉が 2 音以下の場合には,語尾に長音符号を付ける: キー、バー、エラーなど
- 参考 2:「サーバー」と「サーバ」、どっちが正解? - 【ビジネス用語】
- 参考
P.296 候補キー¶
- 行を一意に決めるための必要最小限の属性で構成されるスーパーキー
- 一意性制約が必要
- 何かの履歴のように複数のIDの組になることもある
- 外部キーが入るテーブルでよくある
P.296 主キー¶
- 複数存在する候補キーの中から任意に選んだ1つの候補キーを主キー(primary key)
- 主キーに選ばれなかった残りの候補キーを代理キー(alternate key)
- 主キー制約
- 一意性制約
- 実体を保証するため空値(NULL)は許さないという NOT NULL制約
P.296 外部キー¶
- 関連する他の表を参照する属性あるいは属性の組
- 2 つの表の間に「1対多」の関係がある場合
- 「多」側の表に「1」側の表の主キーあるいは主キー以外の候補キーを参照する属性をもたせて外部キーにする
- 参照制約:外部キーの値が外部キーで参照される表に存在することを保証
- 参照制約があると「親テーブル」のカラムを勝手に消せなくなる
- 複数の表を参照するなら表内に複数の外部キーを持つ
- 外部キーの値に NOT NULL 制約がなければ NULL が許される
- 一般に外部キーは被参照表の主キーを参照
- UNIQUE 指 定 さ れ た候補キーを参照する場合もある
- cf. 参照制約:P.320
P.297 COLUMN 代用のキー設定¶
- 主キーが複数の属性から構成される複合キー(連結キー)でその構成属性数が多すぎると運用が面倒
- 連番のような必ずしも積極的な意味がない属性を追加してそれを代用のキー(surrogate key)にする
- 複合キーを構成している属性はすべて非キー属性にして代理キーにする
P.298 6.3 正規化¶
P.298 6.3.1 関数従属¶
- 関数従属:ある属性xの値が決まると他の属性yの値が一意的に決まる関係で、$x \mapsto y$ と書く
- 属性 $x$:独立属性(決定項)
- 属性 $y$:従属属性(従属項)
- 正規化:1 つの表の中の属性間にある関数従属性に着目して整理する
- 整合性を維持しやすいデータベースが設計できる
P.298 部分関数従属¶
- 関係 $x \mapsto y$ で $y$ が $x$ の真部分集合に関数従属するとき、$y$ は $x$ に部分関数従属するという
- どこの業界の用語なのかよくわからない。情報系?
- 部分関数従属は独立属性 $x$ が複数の属性からなるときに起こりうる関数従属
- あまりピンとこない:P.299 に商品マスタ的な例が載っていた
- 本の例:独立属性 $x$ が $x_1$ と $x_2$ の 2 つの属性からなるとき
- ${x_1, x_2} \mapsto y$ が成り立ち、かつ $x_1 \mapsto y$ または $x_2 \mapsto y$ のどちらかが成り立つ
- このとき ${x_1, x_2 }$ と $y$ の間に部分関数従属がある
- 例:社員所属部門テーブル
- 社員番号・部門コード・部門名があるテーブル
- 主キー:社員番号と部門コード
- 部門コードに対して部門名は一意に紐づく
- このとき部門名は主キーに部分関数従属する
P.298 完全関数従属¶
- 完全関数従属:関係 $x \mapsto y$ で $y$ が $x$ のどの真部分集合にも関数従属しない
- 独立属性 $x$ が 1 つの属性かなるときは常に完全関数従属
P.299 推移的関数従属¶
- 直接ではなく間接的に関数従属している関係
- 例:社員マスタ
- 社員番号・社員名・住所・郵便番号からなるテーブル
- 社員番号から住所が一意に紐づく
- 住所から郵便番号が一意に紐づく
- 郵便番号は社員番号に推移的関数従属している
- 念のため:住所は住所マスタなどに外出し(正規化)するべきで、こういうテーブルを作ってはいけない
- 詳しくは次の 6.3.2 で議論される
2020-11-01 課題¶
- 先に進む前に録画してあるか確認しよう
進捗¶
- 前回の進捗
- 基礎知識編:(ネットワークを飛ばして)「P.290 物理設計」まで
- 本編:03-05 「グラフの解説」まで
- 今回の進捗
- 基礎知識編
- 何か適当なアプリのスキーマ持ってくる
- 「COLUMN インメモリデータベース」まで
- 本編:03-06「定積分の例 $f(x)=x^2$」まで
- 基礎知識編
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 勉強の日常組み込み系
- Julia:The Little Book of Julia Algorithmsを読んでみることにしました。適当に話します。
- 数学のための英語:数学のための英語教本を適当に追いかけます。
- そのうち取り組む事案:黒木さんの Julia での統計ネタ
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
TODO¶
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- 実際に競プロの問題をいくつか解いてみましょう。
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
TeX の記録¶
- ヘルダーの不等式
\begin{align} \Vert fg \Vert_1 \leq \Vert f \Vert_p \cdot \Vert g \Vert_q, \quad p^{-1} + q^{-1} = 1. \end{align}
日々の勉強¶
Julia¶
- The Little Book of Julia Algorithms
- リポジトリの対象ディレクトリ:ここ
- その他参考
数学英語¶
P.20 注意1¶
C) の場合を日常の文と比べてみよう。例えば犬好きの人が "A dog is a friendly animal" といった場合、現実には例外があって吠えかかる犬もいる。しかし、数学の文の場合は例外なしに成り立つと解釈する。
P.26 存在文の主語¶
- (文章を文法的に解析するうえで主語・述語に注目するのが大事という話がある)
- 文の構造を把握するために、There is 構文では形式的に there を主語として調べる
P.37 種明かしの but¶
実はもうこれで証明は完成している
- 気分はわかるが、どの程度「一般的な言明(?)」なのだろうか?
P.40 2.6 冠詞はこわくない¶
- ざっくりした見分け方
- 原則として単数の可算名詞には冠詞がつく.
- 名前のついている定理・公式は一通りに決まるので the.
- (同じ名前の定理もいろいろあるが、文脈に応じて決まる扱いでいいのだろう.)
- 初出か既出か?
- 既出:the
- 初出:前後の文脈・常識から読者にとって一通りに決まるか?
- Yes:the
- No:単数なら a/an, 複数なら冠詞なし
- 冠詞と同時には名詞につかない語
- every, each, any, some, no, another, either, neither, both, this, that, these, those, our, its, their, Cauchy's など代名詞・名詞の所有格
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- ネットワークの話もいい加減飽きたので、DB の話を先行してやるか?
復習¶
OSI基本参照モデル¶
- 会社の部署と同じ気分
- 特定層は自分のところにしか責任を持たない
- 「他の層は他の層で専門的に管轄してね」
- お互い全くの無関係ではないが、基本的には自分のことだけ考えていればいい。
いろいろなプロトコル¶
- IP, HTTP, SMTP, POP, ARP...
- 通信の規格
- 状況に応じて適切なプロトコルを選ぶ
- ヘッダ・ボディーの概念
本の記述を追いかける¶
P.408 7.8 交換方式¶
P.408 パケット交換方式¶
- 回線交換方式と対になる概念
- 回線交換方式:通信を行うノード間で物理的な通信路を確保してから通信する
- 例:電話
- パケット交換方式について
- データ送信するノードはデータをパケットに区切る。
- ひとつひとつのパケットにヘッダを付けて送信。
- ネットワーク内ではパケット交換機にパケットがたまる
- ネットワークの状況に応じて順次送られる
パケット通信のメリット・デメリット¶
メリット¶
耐障害性 - 通信路を固定しないため,迂回経路が取れる。 - パケット交換機にデータが蓄積されているため,復旧まで待てる。 - パケット多重 - 1 対 1 の通信で回線を占有する必要がないため,1つの回線を多くのノードで共有でき,回線を効率的につかえる - 異機種間接続性 - パケット交換機で中継するときにプロトコル変換・速度変換でエンドノードどうしが同じプロトコルをサポートしていなくても通信できる
デメリット¶
- ネットワーク内の蓄積交換処理による遅延
- 蓄積交換処理による遅延解消のために主に回線の帯域を広げることで対応してきた
- 構造上,完全には遅延をなくせない
- パケット到着順序の不整合
P.408 ATM 交換方式¶
- ATM(Asynchronous Transfer Mode:非同期転送モード)
- 遅延のない回線交換方式とパケット交換方式の利点を得たい
- パケット交換方式の発展
- 遅延の原因をつぶす:特にパケットの多様性
- 多種多様なパケットに対応するために,パケット交換機はソフトウェア処理が必要 ^ ATM での工夫の一例:最も特徴的なのは,パケット(ATMではセルという)の長さをヘッダ部 5 バイト,ペイロード 48 バイトの53バイトに統一
- パケット解析がハードウェアだけでできる。
- ソフトウェアは不要になった。
- Wikipedia から
- 当初の意図に反して非常に複雑な技術になってしまった
- ATM は次世代の主流にならず限定的な使用にとどまった
- ATM の設計思想は MPLS へと引き継がれた
- 汎用のレイヤ 2 のパケットスイッチングのプロトコルとして、ルーターを介したIPの通信網で利用されている。
P.408 ペイロード(payload)¶
- データ通信で本来転送したいデータ本体の部分、ボディを指す。
- ATM ではペイロードのサイズを固定して処理を簡素化
- 難点:パケット全体に占めるペイロードのサイズが相対的に小さくオーバヘッドが大きい
P.410 輻輳¶
- フレームリレー:パケット交換方式の一種
- 1 つの回線を多数のユーザで共有。
- 回線がもつ潜在的な伝送能力(ワイヤスピード)を十分に引き出すうえで効果がある
- 輻輳:ユーザの利用が一時期に集中すると,ワイヤスピードを超えるパケットがネットワーク上に流れる
- ネットワークが輻輳状態になるとスループットが落ちる
- フレームリレーサービスを提供する事業者は,ネットワークが輻輳状態に陥ってスループットが低下しても最低限保証する通信速度を決めている
- CIR(Committed Information Rate:認定情 報速度)
P.370 7 ネットワーク¶
- 確か 7.4 から始めた気がするので 7 章はじめから
P.370 7.1.1 OSI基本参照モデル¶
- 改めて復習
- OSI(Open System Interconnection)基本参照モデル- 異なる設計思想・世代のシステムと円滑に通信するのが目的に標準化
- プロトコルの単機能化,交換の容易さが目的
- 階層化のおかげで一部の階層の技術体系が変わっても、その階層だけ取り替えればいい
- コスト・リスクを小さくする
P.370 プロトコルとサービス¶
- N 層:それぞれの階層のこと
- エンティティ:N 層に存在する通信機器などの実体
- この言葉はいろいろなところで出てきていろいろな意味で使われる
- もちろん気分的には適当な実体を指すことが多い
- プロトコル:N 層に属するエンティティが通信するための取り決め
- 上位の層が下位の層を利用しながら通信する
- 別の階層間のエンティティどうしが通信する窓口が必要
- これを提供するのが下位層:この機能をサービスと呼ぶ
- プロトコルに沿った仕様で製品を開発すれば別のベンダの機器でも通信できる
- 参考:ベンダーロックイン
特定ベンダー(メーカー)の独自技術に大きく依存した製品、サービス、システム等を採用した際に、他ベンダーの提供する同種の製品、サービス、システム等への乗り換えが困難になる現象のこと。
出来上がった情報システムの正確な仕様が、システムを開発・構築したベンダーにしか解らなくなる場合がある。結果、システムの保守・拡張・改修等の際、現存システムを開発・構築したベンダーに引き続き発注せざるを得なくなる。
- 「Excel で行政に提出する書類を作れ」事案もそれ。
- Apple 製品で身の回りを固めるのも同じ。
- 「多様性が大事」事案でもある。
7.1.2 TCP/IPプロトコルスイート¶
- プロトコル同士には相性がある
- 「ネットワーク層がこのプロトコルならトランスポート層はこのプロトコルにしておくとトラブルが少ない」
- 一般に同じ団体が作ったプロトコルはセットで使われることが多い
- このセットがプロトコルスイート ^ 最も代表的なのは IP を中心に組まれた TCP/IP プロトコルスイート
- 独自の階層モデルをもつ
P.372 TCP/IPの通信¶
- データをパケットに区切る
- 各パケットにヘッダを付けて送信
- ヘッダは各階層ごとに付加されて次の階層へと渡される
- 各ヘッダにはその階層で必要となる送信元や送信先,大きさ,順番などパケット自体に関する情報を含む
- TCPヘッダを付加したパケット:TCP セグメント
- IP ヘッダを付加したパケット:IP パケット
- MACヘッダを付加したパケット:MAC フレームあるいはイーサネットフレーム
P.372 MAC(Media Access Control)アドレス¶
- イーサネットや FDDI で使用される物理アドレス
- イーサネット (Ethernet):コンピューターネットワークの規格の1つ。オフィスや家庭で一般的に使用されている有線LAN (Local Area Network) の技術規格
- FDDI:LAN でデータ転送を行うための標準の一つ
- Fiber distributed data interface
- データリンク層
- 同じネットワークに接続された隣接ノード間の通信で相手を識別するために使う
- MACアドレスの長さ:6バイト
- 先頭24ビットの OUI(ベンダID)
- 後続24ビットの固有製造番号(製品に割り当てた番号)
- MAC アドレスは機器が固有にもつ番号
- 必ず一意に定まるように IEEE が管理
P372 ポート番号¶
- トランスポート層にでノード内のアプリケーションの識別に使う識別子番号
- 0-65535の範囲
- TCP/IPではパケット交換方式でデータをやり取りする
- よく使われるアプリケーションについてのポート番号は Well-Known ポートとして標準化
- TCP・UDPそれぞれで 0-1023 番までの番号を割り当てている
- SSH:TCP22番
- Telnet:TCP23番
- SMTP:TCP25番
- HTTP:TCP80番
- POP3:TCP110番
- IMAP4:TCP143番
- HTTPS :TCP443番
- NTP:UDP123番
- SNMP:UDP161番
- SNMP Trap :UDP162番
- セキュリティ対策のために標準とはポート番号を変えることもある
- Web 開発の本を読んでいると、いろいろな都合から http のポートを 80 以外にしていることもよくある。
- 80 の場合はポートを指定しなくてもいい
- 例:http://localhost/hoge/fuga
- 例:http://localhost:5000/hoge/fuga
- 80 の場合はポートを指定しなくてもいい
P.373 ネットワーク間の通信¶
- 同じネットワークに接続されたノード間はデータリンク層(第 2 層)の通信
- ネットワークを超えたノード間はネットワーク層(第 3 層)の通信 -実際に図 7.1.4 を見よう
- どこが IP アドレスでのやりとりか?
- どこが MAC アドレスでのやり取りか?
P.374 7.2 ネットワーク接続装置と関連技術¶
P.374 7.2.1 物理層の接続¶
P.374 リピータ¶
- ネットワーク上を流れる電流の増幅装置・整流装置
- 物理層:第 1 層
- データ通信はネットワーク上を流れる電流
- ケーブルが長いと電流が減衰・波形が乱れが起きる
- データが読み取れなくなる
- これを増幅するのがリピータ
- 大昔の電話は距離が遠いと音が小さく聞こえにくかった
- まさにこの減衰が問題
- リピータは 1:1 で繋ぐ
- 現在では複数のノードを接続できるマルチポートリピータ(ハブ)が使われるのが一般的
P.374 7.2.2 データリンク層の接続¶
- 第2層
P374 ブリッジ¶
- データリンク層に位置
- ネットワーク上を流れているフレーム(情報の単位)の MAC アドレスを認識して通信を中継する
- 接続されているノードをコリジョンドメイン(セグメント)という単位に分割
- MAC アドレスで判定したフレームのあて先のあるセグメントだけにフレームを送信
- 無駄なトラフィックの回避
- ポートの記憶
- 通信のたびにある MAC アドレスをもつノードがどのポート に接続されているか学習
- 次回の通信時には余分なポートには通信を中継しない。
- ブリッジの動作
- あて先MACアドレスをもとにMACアドレステーブルを参照する
- あて先MACアドレスの接続ポートがフレームを受信したポー トと別ポートであれば,そのポートにフレームを送信し
- 同一ポートであればフレームを破棄する
- あて先MACアドレスが記憶されていない場合やブロードキャス トアドレス(FF-FF-FF-FF-FF-FF)の場合は,受信ポート以外のすべてのポートにフレームを送信する
P.375 スイッチングハブ¶
- レイヤ2スイッチ(L2スイッチ)とも呼ばれる
- データリンク層に位置
- ブリッジと同じ働きをする
- MAC アドレスを認識してフレームのあて先を決めて通信を行います。
- 試験での問われ方
- スイッチングハブはフレームの蓄積機能、速度変換機能や交換機 能をもっている。
- このようなスイッチングハブと同等の機能をもち,同じプロトコル階層で動作する装置はどれか
- 答えは「ブリッジ」
P.375 ブロードキャストストリーム¶
- データリンク層で動作するブリッジやスイッチングハブなどの LANスイッチはブロードキャストフレームを受信ポート以外 のすべてのポートに転送
- これらの機器をループ状に接続し冗長化させると信頼性はあがる
- ブロードキャストフレームは永遠に回り続けながら増える
- 最終的にはネットワークダウンを招く
- この現象をブロードキャストストームという
- ブロードキャストストームを防ぐプロトコル:スパニングツリープロトコル(Spanning Tree Protocol:STP)
- ループを構成している一部のポートを通常運用時にはブロック(論理的に切断)する
- ネットワーク全体をループをもたない論理的なツリー構造にする
P.376 ネットワーク層の接続¶
- 第 3 層(レイヤ 3)
P.376 ルータ¶
- ルータはネットワーク層(第 3 層)に位置する
- あて先IPアドレスを見てパケットの送り先を決め通信を制御する
- IP のローカルネットワークの境界線に設置して利用され,ネットワークの基本単位として機能
- 世界中に散在しているローカルネットワークどうしをルータが結ぶ
- 全体としてインターネットというインフラが機能
- ルータで分けられたネットワークの単位をブロードキャストドメインという
- ルータがパケットを受け取ったあと
- あて先IPアドレスを見る
- 自分のネットワークあてであれば,破棄
- 他のネットワークあてであれば転送
- どのルータへ送ればあて先のネットワークへの通信が速く行えるかを判断することを経路制御(ルーティング)
- ルータはそのための経路表(ルーティングテーブル)を備えている
P.376 デフォルトゲートウェイ¶
- 会社Aのネットワークに属するPCは会社BのPCと直接通信できない
- 会社AのPCは他ネットワークへの接点であるルータAに転送を依頼
- デフォルトゲートウェイ:会社AのPCから見て直近のルータA
- 自分と直接接続していない相手と通信するときはすべてデフォルト ゲートウェイを中継する
P.376 ルーティング¶
- 経路表(ルーティングテーブル)の作成方法
- 手作業で作る:スタティックルーティング
- ルーティングプロトコル利用:ルータ同士が経路情報を交換し、自立的に経路表を作るダイナミックルーティング
- ダイナミックルーティングのための代表的なルーティングプロトコル:RIP、OSPF
- RIP:ディスタンスベクタ型(距離ベクトル型)
- ルーティングテーブルの情報(経路情報)を一定時間間隔で交換しあう
- あて先ネットワークにいたるまでに経由するルータの数(ホップ数)最小経路を選ぶ
- あて先に到達可能な最大ホップ数は 15
- これを超えた経路は採用されない
- OSPF:リンクステート型
- コストを経路選択の要素に取り入れ、コスト最小経路を選ぶ
- コスト値は,回線速度を基に自動的に算出されるが手動設定もできる
- コスト算出式「コスト=100Mbps/経路の通信帯域(bps)」
- コスト計算例は P.377 の図を見ること
P.377 ルータの冗長構成¶
- ルータを冗長構成のために使うプロトコル:VRRP(Virtual Router Redundancy Protocol )
- 同じ LAN に接続された複数のルータを仮想的に 1 台のルータ として見えるようにして冗長構成を実現する
- 複数のルータでグループ(VRRP グループ)を作る
- VRRP グループごとに仮想 IP アドレスと仮想 MAC アドレスを割り当て
- PC などのノードは仮想ルータの IP アドレスに対して通信
- 通常時はグループのマスタルータが仮想ルータの IP アドレス(仮想 IP アドレス)を保持
- マスタルータに障害が発生すると他のバックアップルータがこれを継承
P.377 レイヤ3スイッチ(L3スイッチ)¶
- ルータと同じネットワーク層(第 3 層)の通信機器
- 特徴
- ルータ:ソフトウェアで転送処理
- レイヤ 3 スイッチ:専用ハードウェアで転送処理
- 高速処理できる:大容量のファイルを扱うファイルサーバへのアクセスなど
P.378 トランスポート層以上の層の接続¶
P.378 ゲートウェイ¶
- トランスポート層(第 4 層)-アプリケーション層(第7層)でネットワーク接続するための装置
- 第 3 層のネットワーク層まででエンドツーエンド(E2E)の通信は完成する
- E2E = 通信を行う二者、あるいは、二者間を結ぶ経路全体
- エンドツーエンド原理:高度な通信制御や複雑な機能は末端のシステムが担い、経路上のシステムは単純に信号やデータの中継・転送だけすべし
- TCP/IP ネットワークの原理
- 誤り訂正・フロー制御・再送:TCP 層(第4層、トランスポート層)など上位側の機器やソフトウェア・プロトコル
- 単純な送受信・転送処理:IP 層(第3層、ネットワーク層)
- ゲートウェイ:第 4 層のトランスポート層以上が違う LAN システム相互間のプロトコル・データ形式の変換を担う
- ゲートウェイはアプリケーションプロトコルの内容を 解釈できる
- アプリケーションヘッダの不正な情報混入を検出可能
- ファイアウォール・プロキシサーバもゲートウェイの一種
P.378 L4スイッチ・L7スイッチ¶
- L4スイッチ(レイヤ4スイッチ)はトランスポート層(第4層)の装置
- 定義としてはゲートウェイ
- 機能的にはレイヤ2スイッチ・レイヤ3スイッチの延長上
- ルータやレイヤ3スイッチはIPアドレスを参照して経路制御する
- L4スイッチではTCPポート番号やUDPポート番号も経路制御判断に使える:第4層の機器だから
- L7スイッチ:アプリケーション層(第7層)までの情報を使って通信制御する
P.379 7.2.5 VLAN¶
- VLAN(Virtual LAN:仮想LAN)
- スイッチ(レイヤ2スイッチ,レイヤ3スイッチ)で物理的な接続形態とは独立に仮想的なLANグループを構成する仕組み,あるいはそう構成されたLAN
- 複雑な形態のネットワークを楽に構築できる
- サブネット構成も柔軟に変えられる
P.380 データリンク層の制御とプロトコル¶
- データリンク層:第2層
P.380 7.3.1 メディアアクセス制御¶
- 複数のデータを1つのケーブルを通して送受する場合,データの衝突(コリジョン)を回避するための制御が必要
- これがメディアアクセス制御(Media Access Control:MAC)
コリジョン(衝突)¶
イーサネットや無線LANで複数の端末が送信し、データが衝突する現象を指す。旧式のイーサネット規格では、端末同士を接続するときに1組の通信路で双方向の通信を行う半二重通信のため、送信と受信を同時に行うことができない。送信と受信をその都度切り替えて行うので、端末がお互いデータを送信してしまうと衝突する可能性が高くなる。
P.380 CSMA/CD¶
- CSMA/CD:Carrier Sense Multiple Access with Collision Detection:搬送波感知多重アクセ ス/衝突検出)の略。
- イーサネットで採用されている方式
- 衝突検知方式を採用
- イーサネット:IEEE 802.3として標準化されている LAN規格
- CSMA/CD
- 各ノードは伝送媒体が使用中かどうかを調べて,使用中でなければデータを送りはじめる
- 複数のノードが同時に通信しはじめるとデータの衝突が起こる
- 衝突を検知し,一定時間(ランダム)待った後で,再送
- 一定の距離以上のケーブルでは衝突が検知できない
- CSMA/CD方式の限界
- トラフィックが増加するにつれて衝突が多くなる
- 再送が増え,さらにトラフィックが増加する悪循環に陥る可能性がある
- 特に伝送路の使用率が30%を超えると実用的でなくなる
P.381トークンパッシング方式¶
- トークンによる送信制御を行う方式で
- トークンバス方式
- トークンリング方式
P.381 トークンパッシング方式¶
- ネットワーク上をフリートークンと呼ばれる送信権のためのパケットが巡回する
- フリートークンを獲得したノードだけが送信できるので衝突を避けられる
- ふつうはコンセントレータ(集線器)でネットワ ークとノードを結ぶ
- トークンパッシング方式を採用したLAN規格
- 例:FDDI:Fiber Distributed Data Interface
- FDDIは物理媒体に光ファイバを利用し,最大100Mビ ッ ト/秒の通信
- 特徴
- 伝送媒体上では衝突しない
- トラフィックが増えるにつれてトークンを獲得しにくくなり,少しずつ遅延時間が増える
- 衝突による再送制御の必要がないため伝送路の使用率に対する遅延時間の増加率はCSMA/CD方式より緩やか
P.382 TDMA 方式¶
- TDM(時分割多重)
- ネットワーク上にデータを送信する時間を割 り当てる(タイムスロット)
- タイムスロットごとに別のデータを送って多重化する
- TDM によるアクセス制御が TDMA
- TDMA(Time Division Multiple Access:時分割多重アクセス)
- CSMA/CD・トークンパッシング方式と並ぶ主要なデー タリンク技術
- TDMA ではネットワーク(伝送路)を使える時間を細かく区切る
- 割り当てられた時間は各ノードが独占する方式
- TDMAはコネクション型の通信
P.382 7.3.2 無線LANのアクセス制御方式¶
P.382 CSMA/CA方式¶
- CSMA/CA:Carrier Sense Multiple Access with Collision Avoidance、搬送波感知多重アクセス/衝突回避
- 無線 LAN の制御方式
- CSMA/CD との違い:「衝突検出」が「衝突回避」になった
- 無線 LAN:物理層媒体は電波で衝突の検出は不可能だから回避する
- 特徴
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
- 待ち時間をバックオフ制御時間とよぶ
- 衝突してフレームが壊れても検出できない
- データを受け取ったノードは ACK を返す
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
P.328 RTS/CTS¶
- 無線 LAN の話
- 隠れ端末問題
- 他のノードのデータ送信を感知できないことがある
- 通信ノード間の距離が遠い
- ノード間に障害物がある
- 回避のための RTS/CTS 方式
- 無線 LAN ノード
- データ送信前にRTS(Request ToSend:送信リクエスト)をアクセスポイントに送信
- これを受理したアクセスポイントがCTS(Clear to Send:送信OK)を返信
- 他のノードは CTS を傍受して自分以外の別のノードに送信権があると解釈
- データ送信を延期
- 無線LANノードはアクセスポイントからCTSを受信したらデータ送信開始します
- 衝突抑制:CTSに書かれた他のノードに対する送信抑制時間を使う
- データ送信開始前にデータ送信のネゴシエーシ ョンとして RTS/CTS 方式を使った CSMA/CA を CSMA/CA with RTS/CTS とよぶ
P.383 無線LANの動作モード¶
- 無線 LAN の動作モード:図7.3.4参照
- 2 つのモードがある
- インフラストラクチャモード:無線LANノードがアク セスポイントを通じて相互に通信
- アドホックモード:アクセスポイントなしに無線LANノードどうしが直接通信
P.383 COLUMN FDMA,CDMA¶
- 表7.3.1:多元接続する技術グループ
- TDMA とセット
- FDMA
- ある周波数帯をさらに細かい周波数帯に分割
- 接続できる端末数を増やす技術
- CDMA
- 周波数も時間も分割しない
- 符号で各端末の通信を識別・分離
- 接続できる端末数を増やす
P.383 7.3.3 データリンク層の主なプロトコル¶
- 第 2 層
P.384 ARP¶
- ARP(Address Resolution Protocol):通信相手のIPアドレスからMACアドレスを取るためのプロトコル
- ARPの動作
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- ブロードキャスト:ネットワークに参加するすべての機器に同時に信号やデータを送ること
- 各ノードは自分のIPアドレスと比較
- 一致したノードだけARP応答パケットに自分のMACアドレスを入れて返す(ユニキャスト)
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- 参考:GARP(Gratuitous ARP)
- 主な目的:自身に設定するIPアドレスの重複確認・ARPテ ーブルの更新
- 目的IPアドレスに自身が使うIPアドレスを指定し,MACアドレスを問い合わせる
P.384 RARP¶
- Reverse-ARP:逆アドレス解決プロトコル
- MACアドレスからIPアドレスを取る
- 電源オフ時にIPアドレスを保持できない(IPアドレスを保持するハードディスクをもたない)機器が電源オン時に自分のMACアドレスから自身に割り当てられているIPアドレスを知るために使う
- RARP サーバー
- MACアドレスとIPアドレスの対応表を持ったサーバー(RARPサーバー)が必要
P.384 PPP¶
- PPP:Point to Point Protocol
- 2 点間をポイントツーポイントでつなぐためのデータリンクプロトコル
- WANを介して2つのノードをダイヤルアップ接続するときに使う
- ネットワーク層(第3層)とネゴシエーションする NCP(ネットワーク制御プロトコル)とリンクネゴシエーションするLCP(リンク制御プロトコル)からなる
- NCP:Network Control Protocol
- LCP:Link Control Protocol
- リンク制御やエラー処理機能を持つ
P.384 PPPoE¶
- PPPoE:PPP over Ethernet
- PPPと同等な機能をイーサネット(LAN)上で実現するプロトコル
- PPPフレームをイーサネットフレームでカプセル化して実現
P.384 7.3.4 IEEE 802.3規格¶
- メディアアクセス制御に CSMA/CD 方式を使う LAN についての標準
- OSI基本参照モデルにおけるデータリンク層(第 2 層)と物理層(第 1 層)のプロトコルおよびサービスを規定
- OSI 基本参照モデルでのデータリンク層を LLC 副層と MAC 副層の2つに分割
- 物理層での LAN で使う伝送媒体や MAC 副層でのフレーム構成や衝突検出の仕組みを規定
- ツイストケーブルの企画が表 7.3.2 にまとまっている
P.386 7.4 ネットワーク層のプロトコルと技術¶
- もうやった
P.290 6.1.3 データベースの3層スキーマ¶
P.290 スキーマ¶
- schema
- データの性質・形式・ほかのデータとの関連などデータ定義の集合
P.290 ANSI/SPARC3層スキーマ¶
- データベースの3層スキーマ
- データを扱う立場を3つのグループに分け,それぞれに対応したデータ定義するためのモデル
- 目的:次の2点の確立
- 論理データ独立性:論理的なデータと利用者やアプリケーションプログラムから見たデータとの独立
- 物理データ独立性:記憶装置との独立
- cf. P.291 の図。
- 外部スキーマ
- 利用者やアプリケーションプログラムから見たデータを定義
- 実世界が変化するとそれに合わせて概念スキーマは変わる
- アプリケーションプログラムが影響を受けないようにするためにするためのスキーマ
- 例:関係データベースのビュー
- 概念スキーマ
- 実際のデータの物理的な表現方法とは別
- データベースの論理的構造とその内容を定義
- 例:論理設計段階の論理データモデル
- 内部スキーマ
- データを記憶装置上にどのような形式や編成で記録するか、物理的内容の定義
- 障害回復処理(リカバリ),セキュリティなども考えた実際にコンピュータに実装させる格納表現
P.291 COLUMN インメモリデータベース¶
- データを直接メモリに配置してパフォーマンスを上げる
- キャッシュとして使われることもよくある
- DB の基本はあくまでディスクにデータを記録してメモリに読み込む
- ディスク入出力がボトルネック
- 前に紹介した速度表を参照すること
- インメモリデータベースではディスク入出力がない
- 基本の処理がメモリ上で閉じるので処理が速い
- 最近のインメモリデータベースの傾向
- データをカラム(列)型フォーマットでメモリに配置する列指向(カラム指向)を採用
- 集計や分析処理などのクエリが高速化します
- 欠点
- 揮発性:メモリ上のデータは電源を切ると失われてしまう
- 何かの事故が起きたらデータが(すべて)飛ぶ
- HDD・SDD よりもメモリは高い
- 対策
- データを定期的にディスクに保存する機能
- 別のスタンバイデータベースにデータの複製を取るレプリケーション機能
P.292 6.1.4 E-R図¶
- 実世界にあるデータ構造をなるべくそのまま表現したい
- データベース管理システムに依存しないデータモデルを作りたい
- ER 図:E-Rモデルを図で表現
- Entity-Relationship Diagram
P.292 E-R図の構成要素¶
- エンティティ:データベース化の対象となる実世界を構成する実体
- 大きく分けて 2 種類
- 物理的実体がある:顧客、商品など
- 物理的実体がない:顧客と購入商品の「関係」そのもの:後の例参照
- RDB の例をいろいろ見るとわかる
- アトリビュート:エンティティがもつその性質や特徴を表すいくつかの属性
- 例:顧客エンティティ
- 顧客番号,顧客名
- 識別子:エンティティを一意に識別するための属性
- いわゆる ID:関係データベースの表の主キー
- 例:顧客番号
- 内部 ID と外部(?)ID がある。
- 内部 ID:システム内で固定の ID。よく数値を使う
- 外部(?)ID:ログイン ID などユーザーが決める ID。
- メールアドレスなどある時点では一意。
- ユーザーが変更できるのでシステム内でその値を永続的に使えない
- 関連(リレーションシップ):業務上の規則やルールなどによって発生するエンティティ間の関係
- 顧客はいくつもの商品を注文する
- カーディナリティ:エンティティ間の「1対1」、「1対 多 」、「 多 対 多 」といった対応関係の表現
- 数学で基数・濃度を cardinal number というその cardinal
P.292 「多対多」の関係¶
- 「多対多」の関係は,関係データベースとして実装できない
- 「1対多」と「多対1」の関係に分解する
- リレーションシップそれ自体を1つのエンティティとする
- 図 6.1.8 参照
- 識別子に顧客エンティティの識別子(顧客番号)と商品エンティティの識別子(商品番号)をもたせる
- 顧客と注文の関係は「1対多」、注文と商品の関係は「多対1」の関係
- このときの「注文」を連関エンティティと呼ぶ
- 注意:リレーションシップも属性をもつ
- 例:注文日、注文数量
- 顧客と商品の両方が特定されてはじめて確定する概念
- 例:注文日、注文数量
P.292 独立エンティティと依存エンティティ¶
- エンティティ間に「1対多」の関係があるとき
- 「多」側のエンティティは「1」側のエンティティの識別子を外部キーとしてもつ
- 外部キーがまさに RDB の R
- 外部キーが識別子の一部となる場合、そのエンティティは「1」側のエンティティに依存する
- cf. P.292 図6.1.8 の注文エンティティ
- 注文はある顧客がある商品を注文するという概念
- 顧客番号と商品番号がないと存在できない
- これを依存エンティティ(弱実体)と呼ぶ
- これを独立化したければしてもいい
- 注文番号を導入
- 注文エンティティを図 6.1.9 のように捉える
- 親エンティティに依存しない独立エンティティ (強実体)とみなせる
- 「発注書に ID を振りたい」といった要望も多いはずで、よくある対応
- 独立化させる必要がないケースの例も見てみよう
- e-ラーニングでの受講履歴
- 「誰がどのコースのどの単元を受講したか」
- 特に ID を振って独立に管理したいわけではない
- いつ何を受講してどういう結果だったか(テスト系ならどの問題にどう回答して正否はどうか)といったことは知りたい
P.294 6.2 関係データベース¶
P.294 6.2.1 関係データベースの特徴¶
- 関係データベース:RDB(Relational DataBase)
- 1970年 E.F.コッド博士によって提案された関係モデルをもとにしたデータベース
- 現在,最も多く使われているデータベース
- 一応集合論をもとにしているらしいが、集合論を知らなくても全く問題ない
- 計算機科学の専門家は集合を勉強しないと駄目らしいという事案ではある模様
P.294 関係データベースの構造¶
- 意味的にひとまとまりのデータを 2 次元の平坦な表で表す
- 列が「あるユーザの情報」
- 行が「ある属性の情報」:名前やメールアドレス
- 表に格納されるデータ:単位は次の通り
- 行(組、タプル)
- 列(属性、アトリビュート)
- 2 次元の平坦な表
- 行と列が交差する 1 つのマスには 1 つの値しか入らない
- 「1 つの値」とはいうが、JSON を叩き込むこともある
- 参考
- インデックスが張れず検索のパフォーマンスは厳しいので、検索したいなら JSON を張るのはやめた方がいい
- NoSQL だと列そのものが JSON だったりもする
- 第 1 正規形:cf. P.300 6.3.2
- 行と列が交差する 1 つのマスには 1 つの値しか入らない
次数と基数¶
- (この言葉を使った記憶がない)
- 次数:1 組のデータを表す行を構成する列の数
- 基数:1 つの表を構成する行の数
- テーブルを集合とみなしたときの要素数
- 本曰く「次数は変わることはありません」
- テーブル定義を変えると変わる
- 実際にテーブル定義を変えることはよくある:特に開発中は。
- 機能追加・改修案件で追加されることもよくある
- 1 行は 1 組のデータを表す:表に対するデータの追加・削除で基数はよく変わる
P.295 定義域(ドメイン)¶
- テーブル全体を $\mathcal{T} = A \times B \times \cdots \times Z$ と書いたときの各 $A,B,\dots,Z$ をドメイン(定義域、domain)と呼ぶ
- 数学の集合と違って $\mathcal{T}$ の中に同じ集合を含まない:つまり $\mathcal{T} = \mathbb{R}^n$ といったテーブルは考えない
- ドメインは「属性が取り得る値の集合」
- RDB では適当なデータ型を対応させる:日付,金額,数量,量
- ドメインを新たなデータ型として定義すると違うデー タ項目でも同じ入力チェックや同じ出力編集ができる
P.296 6.2.2 関係データベースのキー¶
- 表中の行を一意に識別するためのキー(スーパキー,候補キー,主キー)
- 別の表を参照し関連づけるための外部キー
P.296 スーパキー¶
- 表中の行を一意に特定できる属性,あるいは属性の組
- 組について:購入履歴を知るためにはユーザーID・商品ID・購入日がわからないといけない、という程度の意味
- かなり広い意味のようなのでたぶんそんなに使わない
- 補足:なぜスーパ「ー」キーではないのか
- 参考
- JIS の規格がある
- その言葉が 3 音以上の場合には,語尾に長音符号を付けない:ブラウザ、プリンタ、スキャナ、ドライバ、フォルダ、モニタなど
- その言葉が 2 音以下の場合には,語尾に長音符号を付ける: キー、バー、エラーなど
- 参考 2:「サーバー」と「サーバ」、どっちが正解? - 【ビジネス用語】
- 参考
P.296 候補キー¶
- 行を一意に決めるための必要最小限の属性で構成されるスーパーキー
- 一意性制約が必要
- 何かの履歴のように複数のIDの組になることもある
- 外部キーが入るテーブルでよくある
P.296 主キー¶
- 複数存在する候補キーの中から任意に選んだ1つの候補キーを主キー(primary key)
- 主キーに選ばれなかった残りの候補キーを代理キー(alternate key)
- 主キー制約
- 一意性制約
- 実体を保証するため空値(NULL)は許さないという NOT NULL制約
P.296 外部キー¶
- 関連する他の表を参照する属性あるいは属性の組
- 2 つの表の間に「1対多」の関係がある場合
- 「多」側の表に「1」側の表の主キーあるいは主キー以外の候補キーを参照する属性をもたせて外部キーにする
- 参照制約:外部キーの値が外部キーで参照される表に存在することを保証
- 参照制約があると「親テーブル」のカラムを勝手に消せなくなる
- 複数の表を参照するなら表内に複数の外部キーを持つ
- 外部キーの値に NOT NULL 制約がなければ NULL が許される
- 一般に外部キーは被参照表の主キーを参照
- UNIQUE 指 定 さ れ た候補キーを参照する場合もある
- cf. 参照制約:P.320
P.297 COLUMN 代用のキー設定¶
- 主キーが複数の属性から構成される複合キー(連結キー)でその構成属性数が多すぎると運用が面倒
- 連番のような必ずしも積極的な意味がない属性を追加してそれを代用のキー(surrogate key)にする
- 複合キーを構成している属性はすべて非キー属性にして代理キーにする
P.298 6.3 正規化¶
P.298 6.3.1 関数従属¶
- 関数従属:ある属性xの値が決まると他の属性yの値が一意的に決まる関係で、$x \mapsto y$ と書く
- 属性 $x$:独立属性(決定項)
- 属性 $y$:従属属性(従属項)
- 正規化:1 つの表の中の属性間にある関数従属性に着目して整理する
- 整合性を維持しやすいデータベースが設計できる
P.298 部分関数従属¶
- 関係 $x \mapsto y$ で $y$ が $x$ の真部分集合に関数従属するとき、$y$ は $x$ に部分関数従属するという
- どこの業界の用語なのかよくわからない。情報系?
- 部分関数従属は独立属性 $x$ が複数の属性からなるときに起こりうる関数従属
- あまりピンとこない:P.299 に商品マスタ的な例が載っていた
- 本の例:独立属性 $x$ が $x_1$ と $x_2$ の 2 つの属性からなるとき
- ${x_1, x_2} \mapsto y$ が成り立ち、かつ $x_1 \mapsto y$ または $x_2 \mapsto y$ のどちらかが成り立つ
- このとき ${x_1, x_2 }$ と $y$ の間に部分関数従属がある
- 例:社員所属部門テーブル
- 社員番号・部門コード・部門名があるテーブル
- 主キー:社員番号と部門コード
- 部門コードに対して部門名は一意に紐づく
- このとき部門名は主キーに部分関数従属する
P.298 完全関数従属¶
- 完全関数従属:関係 $x \mapsto y$ で $y$ が $x$ のどの真部分集合にも関数従属しない
- 独立属性 $x$ が 1 つの属性かなるときは常に完全関数従属
P.299 推移的関数従属¶
- 直接ではなく間接的に関数従属している関係
- 例:社員マスタ
- 社員番号・社員名・住所・郵便番号からなるテーブル
- 社員番号から住所が一意に紐づく
- 住所から郵便番号が一意に紐づく
- 郵便番号は社員番号に推移的関数従属している
- 念のため:住所は住所マスタなどに外出し(正規化)するべきで、こういうテーブルを作ってはいけない
- 詳しくは次の 6.3.2 で議論される
P.300 6.3.2 正規化の手順¶
P.300 第 1 正規化¶
- 非正規:くり返し部分をもつテーブルのこと
- まずもってくり返しという言葉の理解自体がたぶん面倒
- いろいろな例に触れてみよう
- RDB は平坦な 2 次元の表(テーブル)
- くり返し部分をもつ表から繰り返しを排除してスリム化したい
- 第 1 正規化:くり返しを排除する操作
- 第 1 正規形:第 1 正規化して得られた表のこと
- cf. P.300 図6.3.4 の売上表
- P.300 図 6.3.5
- 売り上げ明細表:主キーの売上番号とくり返し部分を一意に決める商品番号が複合キー
- 別の表に分解する
- 外部キー:他のテーブルの主キーである売上番号を参照している
- 分解・独立させた表に元の表の主キーをもたせる理由:結合で元の表を再現するため
P.301 第1正規形におけるデータ操作での不具合¶
- 第1正規形になった表は RDB 上で定義できる
- データの冗長性のためにデータ操作時に不整合を起こさないように注意が必要:更新時異常の概念
- 種類は以下の通り
- 例は本 P.300 の売り上げ表・売上明細表から
- 第 1 正規形では以下のような更新時異常が起きる可能性がある
- 防止策が第 2 正規化・第 3 正規化
- どこまでどうやるかは状況次第
P.301 修正時異常¶
- 商品名「オレンジ」を「清見オレンジ」に変更したい
- 該当する行をすべて同時に変更しなければならない
- 1行でも変更し忘れるとデータ不整合が起きる
- 先に対策を書いておく
- 売上明細には商品番号だけ持たせて、商品名を削る
- 削った代わりに商品テーブルを作る
- (ふつう商品テーブルには単価も切り出す)
- (単価に消費税を載せるかどうかといった問題もある)
P.301 挿入時異常¶
- 売上明細表の主キーは売上番号と商品番号の複合キ ー
- 売上のない("売上番号"が空値)商品は登録できない
- どうやらこの本の「売上表」は商品テーブルも兼ねているらしい
- 先に対策
- 商品テーブルを別に作って、そこからの参照という形にする
P.301 削除時異常¶
- (先程と同じくこの本の売り上げ表は商品テーブルも兼ねている模様)
- 売上実績が 1 つしかない商品のの売上データを削除す ると商品データも削除される
- 逆に商品データを残そうとすれば売上データは削除できない
- 先に対策:商品テーブルを切り出す
P.301 第2正規化¶
- 第2正規化:すべての非キー属性が各候補キーに完全関数従属である状態にする操作
- 第1正規形の表に対して行われる操作
- 候補キーの一部に部分関数従属する非キー属性を別の表に分解する
- 第2正規化して得られた表を第2正規形という
- 例:図6.3.7の売上明細表
- 候補キーは主キーの{売上番号,商品番号}の1
- 非キー属性である商品名と単価は主キーの一部である商品番号に部分関数従属している
- 商品表として独立させる
- 分解の仕方
- 商品表の主キーを商品番号
- 図6.3.7の上の表を再現できるようにする
- 売上明細表(図6.3.7の下の表)には商品表の主キーを参照する外部キーとして"商品番号"を残す
P.302 メモ¶
- 第2正規化するのは候補キーが複数の属性で構成されている場合。
- 1つの属性で構成されているのであれば部分関数従属は存在しない
- 既に第2正規形
- 非キー属性:どの候補キーにも属さない属性
- 第2正規形:どの非キー属性も候補キーの真部分集合に対して関数従属しない
- どの非キー属性も候補キーに完全関数従属
P.302 第3正規化¶
- 第3正規化:非キー属性間の関数従属をなくしてどの非キー属性も候補キーに直接に関数従属している状態にする
- 第2正規形の表に対して行われる操作
- 候補キーに推移的関数従属している非キー属性を別の表に分解
- 第3正規化して得られた表を第3正規形
- 例:図6.3.8の売上表
- これは第2正規形
- 顧客番号→顧客名いう非キー属性間の関数従属がある
- 顧客番号を主キーとした顧客表として独立させる
- 売上表には顧客表の主キーを参照する外部キーとして顧客番号を残す
P.303 メモ¶
- 第3正規形:どの非キー属性も候補キーに推移的関数従属しない
- どの非キー属性も候補キーに直接に関数従属している
- ボイス・コッド正規形
- 第3正規形では次の関数従属が存在する可能性がある
- 候補キーの真部分集合から他の候補キーの真部分集合への関数従属
- 候補キー以外の属性から候補キーの真部分集合への関数従属
- この関係を分解したのがボイス・コッド正規形
- 第3正規形では次の関数従属が存在する可能性がある
P.303 正規化と非正規化¶
- 正規形には第1正規形から第5正規形まである
- たいていの用途ではデータベースの場合、第3正規形まで正規化されていれば十分といわれている
- 正規化の目的はデータ操作にともなう更新時異常の発生を防ぐこと
- 属性間の関数従属を少なくする
- データの重複を排除する
- 正規化のデメリット
- 表がいくつにも分割される
- 必要なデータを取り出すために表を結合しないといけない
- 処理時間がかかる
- 処理速度が必要な時や更新時異常の発生が低い場合はあえて正規化しない・正規化を解く
- たとえば更新が少ない表は正規化しない
- ここでの「非正規化」:アクセスパターンを考えたうえでどの表を統合するか、どの属性を表間に重複させるか考える
P.304 6.4 関係データベースの演算¶
P.304 6.4.1 集合演算¶
- 関係データベースでの集合演算
- 同じ型の表間での和、共通部分(積)、差
- 直積:同じ型の表でなくてもいい
P.304 和、共通(積)、差¶
- 図6.4.1の表AとBに対するそれぞれの演算結果を見る
- 本参照
P.305 直積演算(Cartesian Product:×)¶
- 社員表と部門表の直積は社員表の各行に対して部門表の行を1つずつつなぎ合わせた表
- 直積の結果として得られる新しい表を直積表と呼ぶ
- 次数(属性の数)は両方の表の次数を足した数
- 位数(タプルの数)は両方の位数を掛けた数
- 直積が役に立つイメージがない:実際には結合 (JOIN) を本当によく使う
P.305 6.4.2 関係演算¶
- 関係演算:関係データベース特有の演算
- 射影,選択,結合,商
- 関係代数:関係演算と集合演算を合わせた代数
- 導出表:これらの演算によって得られた表
P.306 SQL の例¶
- 先に持ってきてみた
SELECT 社員コード, 社員名, 部門表.部門コード, 部門名
FROM 社員表, 部門表
WHERE 社員表.部門コード = 部門表.部門コード
P.305 選択と射影¶
- 選択演算:表から指定した行を取り出す関係演算
- SQL でいう WHERE
- 射影演算:表から指定した列を取り出す関係演算
- SQL でいう SELECT column_name
P.306 結合¶
- 参考:P.306 の下の表
- 結合演算:2つの表が共通にもつ項目(結合列)で結合して新しい表をつくり出す関係演算
- まさに正規化でわけたテーブルを結合させる演算
- SQL:SELECT文のFROM句で複数の表名をカンマで区切って指定
- WHERE句で結合条件を指定
- 結合条件
- 結合列の値を>,≧,=,≠,≦,<のいずれかの比較演算子で比較して結びつける
- 等結合:比較演算子が「=(等号)」である結合
- 2つの表から作成される直積表から結合列の値が等 しいものだけを取り出す
- 得られた新たな表には結合列が重複して含まれる
- SELECT句でどちらか一方の結合列を指定して見かけ上の重複を除く
- 自然結合(natural join):重複する結合列を取り除く(一方のみ残す)ようにした結合
- 結合列の列名が2つの表で同じ場合に使える
- 参考
- (意識的に使ったことがない)
P.307 内結合と外結合¶
- 参考:P.307 の図 6.4.8
- 内結合(INNER JOIN)
- 結合列の値が等しい行だけを取り出す結合演算
- 片方の表にしか存在しない行は取り出せない
- データベース言語仕様(JIS X 3005)
- 外結合(OUTER JOIN)
- 片方の表にしか存在しない行も取り出せる結合
- 結合相手の表に該当するデータが存在しない場合はNULL(空)値で結合
- 左外結合・右外結合・完全外結合
- 等結合
- 結合する表をFROM句で指定、結合条件はWHERE句 で指定
- 内結合・外結合
- 結合する表をFROM句の中でJOINを使って指定
- 結合条件は JOIN に続くON句で指定する
- 参考:p309のコラム「内結合と外結合のSQL文」
P.307 左外結合(LEFT OUTER JOIN)¶
- 参考:P307 図 6.4.9、P309 の SQL 文
- 結合する左の表(社員表)が基準
- 右の表(部門表)に存在しない行を空値(NULL)として結合
P.308 右外結合(RIGHT OUTER JOIN)¶
- 参考:P.308 図 6.4.10
- 結合する右の表(部門表)が基準
- 左の表(社員表)に存在しない行をNULLとして結合
P.308 完全外結合(FULL OUTER JOIN)¶
- 参考:P.308 図 6.4.11
- 片方だけに存在する場合もう片方をNULLとして結合
P.308 商¶
- (これ何だろうか?where の
in?) - 参考:P.308 図 6.4.12
- 関係R(X,Y1,Y2)とS(Y3,Y4)がある
- S(Y3,Y4)のすべての行がR(Y1,Y2)に含まれる場合に対応するR(X)を求める演算
- 商(R÷S)は関係Rの中から関係Sのすべての行を含む行を取り出し、そこから関係Sの項目を除く
- 重複行も除く
2020-11-15 課題¶
- 先に進む前に録画してあるか確認しよう
進捗¶
- 前回の進捗
- 基礎知識編:「COLUMN インメモリデータベース」まで
- 本編:03-06「定積分の例 $f(x)=x^2$」まで
- 今回の進捗
- 基礎知識編:次数と基数まで
- 本編:04-01 の冒頭
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 勉強の日常組み込み系
- Julia:The Little Book of Julia Algorithmsを読んでみることにしました。適当に話します。
- そのうち取り組む事案:黒木さんの Julia での統計ネタ
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
TODO¶
- AWS のハンズオン
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- 実際に競プロの問題をいくつか解いてみましょう。
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
TeX の記録¶
- ミンコフスキーの不等式
\begin{align} \Vert f+g \Vert_p \leq \Vert f \Vert_p + \Vert g \Vert_p, \quad p \geq 1. \end{align}
日々の勉強¶
Julia¶
- The Little Book of Julia Algorithms
- リポジトリの対象ディレクトリ:ここ
- その他参考
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- ネットワークの話もいい加減飽きたので、DB の話を先行してやるか?
復習¶
- 3 つのスキーマ
- ユーザーが見るレベル
- 正規化などをかけておいたデータベースにもっていけるレベル
- 個々のデータベースに合わせた具体的なレベル
- インメモリの DB:コンピューターの基本的なハードウェア構成と意味を復習しよう
本の記述を追いかける¶
P.408 7.8 交換方式¶
P.408 パケット交換方式¶
- 回線交換方式と対になる概念
- 回線交換方式:通信を行うノード間で物理的な通信路を確保してから通信する
- 例:電話
- パケット交換方式について
- データ送信するノードはデータをパケットに区切る。
- ひとつひとつのパケットにヘッダを付けて送信。
- ネットワーク内ではパケット交換機にパケットがたまる
- ネットワークの状況に応じて順次送られる
パケット通信のメリット・デメリット¶
メリット¶
耐障害性 - 通信路を固定しないため,迂回経路が取れる。 - パケット交換機にデータが蓄積されているため,復旧まで待てる。 - パケット多重 - 1 対 1 の通信で回線を占有する必要がないため,1つの回線を多くのノードで共有でき,回線を効率的につかえる - 異機種間接続性 - パケット交換機で中継するときにプロトコル変換・速度変換でエンドノードどうしが同じプロトコルをサポートしていなくても通信できる
デメリット¶
- ネットワーク内の蓄積交換処理による遅延
- 蓄積交換処理による遅延解消のために主に回線の帯域を広げることで対応してきた
- 構造上,完全には遅延をなくせない
- パケット到着順序の不整合
P.408 ATM 交換方式¶
- ATM(Asynchronous Transfer Mode:非同期転送モード)
- 遅延のない回線交換方式とパケット交換方式の利点を得たい
- パケット交換方式の発展
- 遅延の原因をつぶす:特にパケットの多様性
- 多種多様なパケットに対応するために,パケット交換機はソフトウェア処理が必要 ^ ATM での工夫の一例:最も特徴的なのは,パケット(ATMではセルという)の長さをヘッダ部 5 バイト,ペイロード 48 バイトの53バイトに統一
- パケット解析がハードウェアだけでできる。
- ソフトウェアは不要になった。
- Wikipedia から
- 当初の意図に反して非常に複雑な技術になってしまった
- ATM は次世代の主流にならず限定的な使用にとどまった
- ATM の設計思想は MPLS へと引き継がれた
- 汎用のレイヤ 2 のパケットスイッチングのプロトコルとして、ルーターを介したIPの通信網で利用されている。
P.408 ペイロード(payload)¶
- データ通信で本来転送したいデータ本体の部分、ボディを指す。
- ATM ではペイロードのサイズを固定して処理を簡素化
- 難点:パケット全体に占めるペイロードのサイズが相対的に小さくオーバヘッドが大きい
P.410 輻輳¶
- フレームリレー:パケット交換方式の一種
- 1 つの回線を多数のユーザで共有。
- 回線がもつ潜在的な伝送能力(ワイヤスピード)を十分に引き出すうえで効果がある
- 輻輳:ユーザの利用が一時期に集中すると,ワイヤスピードを超えるパケットがネットワーク上に流れる
- ネットワークが輻輳状態になるとスループットが落ちる
- フレームリレーサービスを提供する事業者は,ネットワークが輻輳状態に陥ってスループットが低下しても最低限保証する通信速度を決めている
- CIR(Committed Information Rate:認定情 報速度)
P.370 7 ネットワーク¶
- 確か 7.4 から始めた気がするので 7 章はじめから
P.370 7.1.1 OSI基本参照モデル¶
- 改めて復習
- OSI(Open System Interconnection)基本参照モデル- 異なる設計思想・世代のシステムと円滑に通信するのが目的に標準化
- プロトコルの単機能化,交換の容易さが目的
- 階層化のおかげで一部の階層の技術体系が変わっても、その階層だけ取り替えればいい
- コスト・リスクを小さくする
P.370 プロトコルとサービス¶
- N 層:それぞれの階層のこと
- エンティティ:N 層に存在する通信機器などの実体
- この言葉はいろいろなところで出てきていろいろな意味で使われる
- もちろん気分的には適当な実体を指すことが多い
- プロトコル:N 層に属するエンティティが通信するための取り決め
- 上位の層が下位の層を利用しながら通信する
- 別の階層間のエンティティどうしが通信する窓口が必要
- これを提供するのが下位層:この機能をサービスと呼ぶ
- プロトコルに沿った仕様で製品を開発すれば別のベンダの機器でも通信できる
- 参考:ベンダーロックイン
特定ベンダー(メーカー)の独自技術に大きく依存した製品、サービス、システム等を採用した際に、他ベンダーの提供する同種の製品、サービス、システム等への乗り換えが困難になる現象のこと。
出来上がった情報システムの正確な仕様が、システムを開発・構築したベンダーにしか解らなくなる場合がある。結果、システムの保守・拡張・改修等の際、現存システムを開発・構築したベンダーに引き続き発注せざるを得なくなる。
- 「Excel で行政に提出する書類を作れ」事案もそれ。
- Apple 製品で身の回りを固めるのも同じ。
- 「多様性が大事」事案でもある。
7.1.2 TCP/IPプロトコルスイート¶
- プロトコル同士には相性がある
- 「ネットワーク層がこのプロトコルならトランスポート層はこのプロトコルにしておくとトラブルが少ない」
- 一般に同じ団体が作ったプロトコルはセットで使われることが多い
- このセットがプロトコルスイート ^ 最も代表的なのは IP を中心に組まれた TCP/IP プロトコルスイート
- 独自の階層モデルをもつ
P.372 TCP/IPの通信¶
- データをパケットに区切る
- 各パケットにヘッダを付けて送信
- ヘッダは各階層ごとに付加されて次の階層へと渡される
- 各ヘッダにはその階層で必要となる送信元や送信先,大きさ,順番などパケット自体に関する情報を含む
- TCPヘッダを付加したパケット:TCP セグメント
- IP ヘッダを付加したパケット:IP パケット
- MACヘッダを付加したパケット:MAC フレームあるいはイーサネットフレーム
P.372 MAC(Media Access Control)アドレス¶
- イーサネットや FDDI で使用される物理アドレス
- イーサネット (Ethernet):コンピューターネットワークの規格の1つ。オフィスや家庭で一般的に使用されている有線LAN (Local Area Network) の技術規格
- FDDI:LAN でデータ転送を行うための標準の一つ
- Fiber distributed data interface
- データリンク層
- 同じネットワークに接続された隣接ノード間の通信で相手を識別するために使う
- MACアドレスの長さ:6バイト
- 先頭24ビットの OUI(ベンダID)
- 後続24ビットの固有製造番号(製品に割り当てた番号)
- MAC アドレスは機器が固有にもつ番号
- 必ず一意に定まるように IEEE が管理
P372 ポート番号¶
- トランスポート層にでノード内のアプリケーションの識別に使う識別子番号
- 0-65535の範囲
- TCP/IPではパケット交換方式でデータをやり取りする
- よく使われるアプリケーションについてのポート番号は Well-Known ポートとして標準化
- TCP・UDPそれぞれで 0-1023 番までの番号を割り当てている
- SSH:TCP22番
- Telnet:TCP23番
- SMTP:TCP25番
- HTTP:TCP80番
- POP3:TCP110番
- IMAP4:TCP143番
- HTTPS :TCP443番
- NTP:UDP123番
- SNMP:UDP161番
- SNMP Trap :UDP162番
- セキュリティ対策のために標準とはポート番号を変えることもある
- Web 開発の本を読んでいると、いろいろな都合から http のポートを 80 以外にしていることもよくある。
- 80 の場合はポートを指定しなくてもいい
- 例:http://localhost/hoge/fuga
- 例:http://localhost:5000/hoge/fuga
- 80 の場合はポートを指定しなくてもいい
P.373 ネットワーク間の通信¶
- 同じネットワークに接続されたノード間はデータリンク層(第 2 層)の通信
- ネットワークを超えたノード間はネットワーク層(第 3 層)の通信 -実際に図 7.1.4 を見よう
- どこが IP アドレスでのやりとりか?
- どこが MAC アドレスでのやり取りか?
P.374 7.2 ネットワーク接続装置と関連技術¶
P.374 7.2.1 物理層の接続¶
P.374 リピータ¶
- ネットワーク上を流れる電流の増幅装置・整流装置
- 物理層:第 1 層
- データ通信はネットワーク上を流れる電流
- ケーブルが長いと電流が減衰・波形が乱れが起きる
- データが読み取れなくなる
- これを増幅するのがリピータ
- 大昔の電話は距離が遠いと音が小さく聞こえにくかった
- まさにこの減衰が問題
- リピータは 1:1 で繋ぐ
- 現在では複数のノードを接続できるマルチポートリピータ(ハブ)が使われるのが一般的
P.374 7.2.2 データリンク層の接続¶
- 第2層
P374 ブリッジ¶
- データリンク層に位置
- ネットワーク上を流れているフレーム(情報の単位)の MAC アドレスを認識して通信を中継する
- 接続されているノードをコリジョンドメイン(セグメント)という単位に分割
- MAC アドレスで判定したフレームのあて先のあるセグメントだけにフレームを送信
- 無駄なトラフィックの回避
- ポートの記憶
- 通信のたびにある MAC アドレスをもつノードがどのポート に接続されているか学習
- 次回の通信時には余分なポートには通信を中継しない。
- ブリッジの動作
- あて先MACアドレスをもとにMACアドレステーブルを参照する
- あて先MACアドレスの接続ポートがフレームを受信したポー トと別ポートであれば,そのポートにフレームを送信し
- 同一ポートであればフレームを破棄する
- あて先MACアドレスが記憶されていない場合やブロードキャス トアドレス(FF-FF-FF-FF-FF-FF)の場合は,受信ポート以外のすべてのポートにフレームを送信する
P.375 スイッチングハブ¶
- レイヤ2スイッチ(L2スイッチ)とも呼ばれる
- データリンク層に位置
- ブリッジと同じ働きをする
- MAC アドレスを認識してフレームのあて先を決めて通信を行います。
- 試験での問われ方
- スイッチングハブはフレームの蓄積機能、速度変換機能や交換機 能をもっている。
- このようなスイッチングハブと同等の機能をもち,同じプロトコル階層で動作する装置はどれか
- 答えは「ブリッジ」
P.375 ブロードキャストストリーム¶
- データリンク層で動作するブリッジやスイッチングハブなどの LANスイッチはブロードキャストフレームを受信ポート以外 のすべてのポートに転送
- これらの機器をループ状に接続し冗長化させると信頼性はあがる
- ブロードキャストフレームは永遠に回り続けながら増える
- 最終的にはネットワークダウンを招く
- この現象をブロードキャストストームという
- ブロードキャストストームを防ぐプロトコル:スパニングツリープロトコル(Spanning Tree Protocol:STP)
- ループを構成している一部のポートを通常運用時にはブロック(論理的に切断)する
- ネットワーク全体をループをもたない論理的なツリー構造にする
P.376 ネットワーク層の接続¶
- 第 3 層(レイヤ 3)
P.376 ルータ¶
- ルータはネットワーク層(第 3 層)に位置する
- あて先IPアドレスを見てパケットの送り先を決め通信を制御する
- IP のローカルネットワークの境界線に設置して利用され,ネットワークの基本単位として機能
- 世界中に散在しているローカルネットワークどうしをルータが結ぶ
- 全体としてインターネットというインフラが機能
- ルータで分けられたネットワークの単位をブロードキャストドメインという
- ルータがパケットを受け取ったあと
- あて先IPアドレスを見る
- 自分のネットワークあてであれば,破棄
- 他のネットワークあてであれば転送
- どのルータへ送ればあて先のネットワークへの通信が速く行えるかを判断することを経路制御(ルーティング)
- ルータはそのための経路表(ルーティングテーブル)を備えている
P.376 デフォルトゲートウェイ¶
- 会社Aのネットワークに属するPCは会社BのPCと直接通信できない
- 会社AのPCは他ネットワークへの接点であるルータAに転送を依頼
- デフォルトゲートウェイ:会社AのPCから見て直近のルータA
- 自分と直接接続していない相手と通信するときはすべてデフォルト ゲートウェイを中継する
P.376 ルーティング¶
- 経路表(ルーティングテーブル)の作成方法
- 手作業で作る:スタティックルーティング
- ルーティングプロトコル利用:ルータ同士が経路情報を交換し、自立的に経路表を作るダイナミックルーティング
- ダイナミックルーティングのための代表的なルーティングプロトコル:RIP、OSPF
- RIP:ディスタンスベクタ型(距離ベクトル型)
- ルーティングテーブルの情報(経路情報)を一定時間間隔で交換しあう
- あて先ネットワークにいたるまでに経由するルータの数(ホップ数)最小経路を選ぶ
- あて先に到達可能な最大ホップ数は 15
- これを超えた経路は採用されない
- OSPF:リンクステート型
- コストを経路選択の要素に取り入れ、コスト最小経路を選ぶ
- コスト値は,回線速度を基に自動的に算出されるが手動設定もできる
- コスト算出式「コスト=100Mbps/経路の通信帯域(bps)」
- コスト計算例は P.377 の図を見ること
P.377 ルータの冗長構成¶
- ルータを冗長構成のために使うプロトコル:VRRP(Virtual Router Redundancy Protocol )
- 同じ LAN に接続された複数のルータを仮想的に 1 台のルータ として見えるようにして冗長構成を実現する
- 複数のルータでグループ(VRRP グループ)を作る
- VRRP グループごとに仮想 IP アドレスと仮想 MAC アドレスを割り当て
- PC などのノードは仮想ルータの IP アドレスに対して通信
- 通常時はグループのマスタルータが仮想ルータの IP アドレス(仮想 IP アドレス)を保持
- マスタルータに障害が発生すると他のバックアップルータがこれを継承
P.377 レイヤ3スイッチ(L3スイッチ)¶
- ルータと同じネットワーク層(第 3 層)の通信機器
- 特徴
- ルータ:ソフトウェアで転送処理
- レイヤ 3 スイッチ:専用ハードウェアで転送処理
- 高速処理できる:大容量のファイルを扱うファイルサーバへのアクセスなど
P.378 トランスポート層以上の層の接続¶
P.378 ゲートウェイ¶
- トランスポート層(第 4 層)-アプリケーション層(第7層)でネットワーク接続するための装置
- 第 3 層のネットワーク層まででエンドツーエンド(E2E)の通信は完成する
- E2E = 通信を行う二者、あるいは、二者間を結ぶ経路全体
- エンドツーエンド原理:高度な通信制御や複雑な機能は末端のシステムが担い、経路上のシステムは単純に信号やデータの中継・転送だけすべし
- TCP/IP ネットワークの原理
- 誤り訂正・フロー制御・再送:TCP 層(第4層、トランスポート層)など上位側の機器やソフトウェア・プロトコル
- 単純な送受信・転送処理:IP 層(第3層、ネットワーク層)
- ゲートウェイ:第 4 層のトランスポート層以上が違う LAN システム相互間のプロトコル・データ形式の変換を担う
- ゲートウェイはアプリケーションプロトコルの内容を 解釈できる
- アプリケーションヘッダの不正な情報混入を検出可能
- ファイアウォール・プロキシサーバもゲートウェイの一種
P.378 L4スイッチ・L7スイッチ¶
- L4スイッチ(レイヤ4スイッチ)はトランスポート層(第4層)の装置
- 定義としてはゲートウェイ
- 機能的にはレイヤ2スイッチ・レイヤ3スイッチの延長上
- ルータやレイヤ3スイッチはIPアドレスを参照して経路制御する
- L4スイッチではTCPポート番号やUDPポート番号も経路制御判断に使える:第4層の機器だから
- L7スイッチ:アプリケーション層(第7層)までの情報を使って通信制御する
P.379 7.2.5 VLAN¶
- VLAN(Virtual LAN:仮想LAN)
- スイッチ(レイヤ2スイッチ,レイヤ3スイッチ)で物理的な接続形態とは独立に仮想的なLANグループを構成する仕組み,あるいはそう構成されたLAN
- 複雑な形態のネットワークを楽に構築できる
- サブネット構成も柔軟に変えられる
P.380 データリンク層の制御とプロトコル¶
- データリンク層:第2層
P.380 7.3.1 メディアアクセス制御¶
- 複数のデータを1つのケーブルを通して送受する場合,データの衝突(コリジョン)を回避するための制御が必要
- これがメディアアクセス制御(Media Access Control:MAC)
コリジョン(衝突)¶
イーサネットや無線LANで複数の端末が送信し、データが衝突する現象を指す。旧式のイーサネット規格では、端末同士を接続するときに1組の通信路で双方向の通信を行う半二重通信のため、送信と受信を同時に行うことができない。送信と受信をその都度切り替えて行うので、端末がお互いデータを送信してしまうと衝突する可能性が高くなる。
P.380 CSMA/CD¶
- CSMA/CD:Carrier Sense Multiple Access with Collision Detection:搬送波感知多重アクセ ス/衝突検出)の略。
- イーサネットで採用されている方式
- 衝突検知方式を採用
- イーサネット:IEEE 802.3として標準化されている LAN規格
- CSMA/CD
- 各ノードは伝送媒体が使用中かどうかを調べて,使用中でなければデータを送りはじめる
- 複数のノードが同時に通信しはじめるとデータの衝突が起こる
- 衝突を検知し,一定時間(ランダム)待った後で,再送
- 一定の距離以上のケーブルでは衝突が検知できない
- CSMA/CD方式の限界
- トラフィックが増加するにつれて衝突が多くなる
- 再送が増え,さらにトラフィックが増加する悪循環に陥る可能性がある
- 特に伝送路の使用率が30%を超えると実用的でなくなる
P.381トークンパッシング方式¶
- トークンによる送信制御を行う方式で
- トークンバス方式
- トークンリング方式
P.381 トークンパッシング方式¶
- ネットワーク上をフリートークンと呼ばれる送信権のためのパケットが巡回する
- フリートークンを獲得したノードだけが送信できるので衝突を避けられる
- ふつうはコンセントレータ(集線器)でネットワ ークとノードを結ぶ
- トークンパッシング方式を採用したLAN規格
- 例:FDDI:Fiber Distributed Data Interface
- FDDIは物理媒体に光ファイバを利用し,最大100Mビ ッ ト/秒の通信
- 特徴
- 伝送媒体上では衝突しない
- トラフィックが増えるにつれてトークンを獲得しにくくなり,少しずつ遅延時間が増える
- 衝突による再送制御の必要がないため伝送路の使用率に対する遅延時間の増加率はCSMA/CD方式より緩やか
P.382 TDMA 方式¶
- TDM(時分割多重)
- ネットワーク上にデータを送信する時間を割 り当てる(タイムスロット)
- タイムスロットごとに別のデータを送って多重化する
- TDM によるアクセス制御が TDMA
- TDMA(Time Division Multiple Access:時分割多重アクセス)
- CSMA/CD・トークンパッシング方式と並ぶ主要なデー タリンク技術
- TDMA ではネットワーク(伝送路)を使える時間を細かく区切る
- 割り当てられた時間は各ノードが独占する方式
- TDMAはコネクション型の通信
P.382 7.3.2 無線LANのアクセス制御方式¶
P.382 CSMA/CA方式¶
- CSMA/CA:Carrier Sense Multiple Access with Collision Avoidance、搬送波感知多重アクセス/衝突回避
- 無線 LAN の制御方式
- CSMA/CD との違い:「衝突検出」が「衝突回避」になった
- 無線 LAN:物理層媒体は電波で衝突の検出は不可能だから回避する
- 特徴
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
- 待ち時間をバックオフ制御時間とよぶ
- 衝突してフレームが壊れても検出できない
- データを受け取ったノードは ACK を返す
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
P.328 RTS/CTS¶
- 無線 LAN の話
- 隠れ端末問題
- 他のノードのデータ送信を感知できないことがある
- 通信ノード間の距離が遠い
- ノード間に障害物がある
- 回避のための RTS/CTS 方式
- 無線 LAN ノード
- データ送信前にRTS(Request ToSend:送信リクエスト)をアクセスポイントに送信
- これを受理したアクセスポイントがCTS(Clear to Send:送信OK)を返信
- 他のノードは CTS を傍受して自分以外の別のノードに送信権があると解釈
- データ送信を延期
- 無線LANノードはアクセスポイントからCTSを受信したらデータ送信開始します
- 衝突抑制:CTSに書かれた他のノードに対する送信抑制時間を使う
- データ送信開始前にデータ送信のネゴシエーシ ョンとして RTS/CTS 方式を使った CSMA/CA を CSMA/CA with RTS/CTS とよぶ
P.383 無線LANの動作モード¶
- 無線 LAN の動作モード:図7.3.4参照
- 2 つのモードがある
- インフラストラクチャモード:無線LANノードがアク セスポイントを通じて相互に通信
- アドホックモード:アクセスポイントなしに無線LANノードどうしが直接通信
P.383 COLUMN FDMA,CDMA¶
- 表7.3.1:多元接続する技術グループ
- TDMA とセット
- FDMA
- ある周波数帯をさらに細かい周波数帯に分割
- 接続できる端末数を増やす技術
- CDMA
- 周波数も時間も分割しない
- 符号で各端末の通信を識別・分離
- 接続できる端末数を増やす
P.383 7.3.3 データリンク層の主なプロトコル¶
- 第 2 層
P.384 ARP¶
- ARP(Address Resolution Protocol):通信相手のIPアドレスからMACアドレスを取るためのプロトコル
- ARPの動作
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- ブロードキャスト:ネットワークに参加するすべての機器に同時に信号やデータを送ること
- 各ノードは自分のIPアドレスと比較
- 一致したノードだけARP応答パケットに自分のMACアドレスを入れて返す(ユニキャスト)
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- 参考:GARP(Gratuitous ARP)
- 主な目的:自身に設定するIPアドレスの重複確認・ARPテ ーブルの更新
- 目的IPアドレスに自身が使うIPアドレスを指定し,MACアドレスを問い合わせる
P.384 RARP¶
- Reverse-ARP:逆アドレス解決プロトコル
- MACアドレスからIPアドレスを取る
- 電源オフ時にIPアドレスを保持できない(IPアドレスを保持するハードディスクをもたない)機器が電源オン時に自分のMACアドレスから自身に割り当てられているIPアドレスを知るために使う
- RARP サーバー
- MACアドレスとIPアドレスの対応表を持ったサーバー(RARPサーバー)が必要
P.384 PPP¶
- PPP:Point to Point Protocol
- 2 点間をポイントツーポイントでつなぐためのデータリンクプロトコル
- WANを介して2つのノードをダイヤルアップ接続するときに使う
- ネットワーク層(第3層)とネゴシエーションする NCP(ネットワーク制御プロトコル)とリンクネゴシエーションするLCP(リンク制御プロトコル)からなる
- NCP:Network Control Protocol
- LCP:Link Control Protocol
- リンク制御やエラー処理機能を持つ
P.384 PPPoE¶
- PPPoE:PPP over Ethernet
- PPPと同等な機能をイーサネット(LAN)上で実現するプロトコル
- PPPフレームをイーサネットフレームでカプセル化して実現
P.384 7.3.4 IEEE 802.3規格¶
- メディアアクセス制御に CSMA/CD 方式を使う LAN についての標準
- OSI基本参照モデルにおけるデータリンク層(第 2 層)と物理層(第 1 層)のプロトコルおよびサービスを規定
- OSI 基本参照モデルでのデータリンク層を LLC 副層と MAC 副層の2つに分割
- 物理層での LAN で使う伝送媒体や MAC 副層でのフレーム構成や衝突検出の仕組みを規定
- ツイストケーブルの企画が表 7.3.2 にまとまっている
P.386 7.4 ネットワーク層のプロトコルと技術¶
- もうやった
P.290 6.1.3 データベースの3層スキーマ¶
P.290 スキーマ¶
- schema
- データの性質・形式・ほかのデータとの関連などデータ定義の集合
P.290 ANSI/SPARC3層スキーマ¶
- データベースの3層スキーマ
- データを扱う立場を3つのグループに分け,それぞれに対応したデータ定義するためのモデル
- 目的:次の2点の確立
- 論理データ独立性:論理的なデータと利用者やアプリケーションプログラムから見たデータとの独立
- 物理データ独立性:記憶装置との独立
- cf. P.291 の図。
- 外部スキーマ
- 利用者やアプリケーションプログラムから見たデータを定義
- 実世界が変化するとそれに合わせて概念スキーマは変わる
- アプリケーションプログラムが影響を受けないようにするためにするためのスキーマ
- 例:関係データベースのビュー
- 概念スキーマ
- 実際のデータの物理的な表現方法とは別
- データベースの論理的構造とその内容を定義
- 例:論理設計段階の論理データモデル
- 内部スキーマ
- データを記憶装置上にどのような形式や編成で記録するか、物理的内容の定義
- 障害回復処理(リカバリ),セキュリティなども考えた実際にコンピュータに実装させる格納表現
P.292 6.1.4 E-R図¶
- 実世界にあるデータ構造をなるべくそのまま表現したい
- データベース管理システムに依存しないデータモデルを作りたい
- ER 図:E-Rモデルを図で表現
- Entity-Relationship Diagram
P.292 E-R図の構成要素¶
- エンティティ:データベース化の対象となる実世界を構成する実体
- 大きく分けて 2 種類
- 物理的実体がある:顧客、商品など
- 物理的実体がない:顧客と購入商品の「関係」そのもの:後の例参照
- RDB の例をいろいろ見るとわかる
- アトリビュート:エンティティがもつその性質や特徴を表すいくつかの属性
- 例:顧客エンティティ
- 顧客番号,顧客名
- 識別子:エンティティを一意に識別するための属性
- いわゆる ID:関係データベースの表の主キー
- 例:顧客番号
- 内部 ID と外部(?)ID がある。
- 内部 ID:システム内で固定の ID。よく数値を使う
- 外部(?)ID:ログイン ID などユーザーが決める ID。
- メールアドレスなどある時点では一意。
- ユーザーが変更できるのでシステム内でその値を永続的に使えない
- 関連(リレーションシップ):業務上の規則やルールなどによって発生するエンティティ間の関係
- 顧客はいくつもの商品を注文する
- カーディナリティ:エンティティ間の「1対1」、「1対 多 」、「 多 対 多 」といった対応関係の表現
- 数学で基数・濃度を cardinal number というその cardinal
P.292 「多対多」の関係¶
- 「多対多」の関係は,関係データベースとして実装できない
- 「1対多」と「多対1」の関係に分解する
- リレーションシップそれ自体を1つのエンティティとする
- 図 6.1.8 参照
- 識別子に顧客エンティティの識別子(顧客番号)と商品エンティティの識別子(商品番号)をもたせる
- 顧客と注文の関係は「1対多」、注文と商品の関係は「多対1」の関係
- このときの「注文」を連関エンティティと呼ぶ
- 注意:リレーションシップも属性をもつ
- 例:注文日、注文数量
- 顧客と商品の両方が特定されてはじめて確定する概念
- 例:注文日、注文数量
P.292 独立エンティティと依存エンティティ¶
- エンティティ間に「1対多」の関係があるとき
- 「多」側のエンティティは「1」側のエンティティの識別子を外部キーとしてもつ
- 外部キーがまさに RDB の R
- 外部キーが識別子の一部となる場合、そのエンティティは「1」側のエンティティに依存する
- cf. P.292 図6.1.8 の注文エンティティ
- 注文はある顧客がある商品を注文するという概念
- 顧客番号と商品番号がないと存在できない
- これを依存エンティティ(弱実体)と呼ぶ
- これを独立化したければしてもいい
- 注文番号を導入
- 注文エンティティを図 6.1.9 のように捉える
- 親エンティティに依存しない独立エンティティ (強実体)とみなせる
- 「発注書に ID を振りたい」といった要望も多いはずで、よくある対応
- 独立化させる必要がないケースの例も見てみよう
- e-ラーニングでの受講履歴
- 「誰がどのコースのどの単元を受講したか」
- 特に ID を振って独立に管理したいわけではない
- いつ何を受講してどういう結果だったか(テスト系ならどの問題にどう回答して正否はどうか)といったことは知りたい
P.294 6.2 関係データベース¶
P.294 6.2.1 関係データベースの特徴¶
- 関係データベース:RDB(Relational DataBase)
- 1970年 E.F.コッド博士によって提案された関係モデルをもとにしたデータベース
- 現在,最も多く使われているデータベース
- 一応集合論をもとにしているらしいが、集合論を知らなくても全く問題ない
- 計算機科学の専門家は集合を勉強しないと駄目らしいという事案ではある模様
P.294 関係データベースの構造¶
- 意味的にひとまとまりのデータを 2 次元の平坦な表で表す
- 列が「あるユーザの情報」
- 行が「ある属性の情報」:名前やメールアドレス
- 表に格納されるデータ:単位は次の通り
- 行(組、タプル)
- 列(属性、アトリビュート)
- 2 次元の平坦な表
- 行と列が交差する 1 つのマスには 1 つの値しか入らない
- 「1 つの値」とはいうが、JSON を叩き込むこともある
- 参考
- インデックスが張れず検索のパフォーマンスは厳しいので、検索したいなら JSON を張るのはやめた方がいい
- NoSQL だと列そのものが JSON だったりもする
- 第 1 正規形:cf. P.300 6.3.2
- 行と列が交差する 1 つのマスには 1 つの値しか入らない
次数と基数¶
- (この言葉を使った記憶がない)
- 次数:1 組のデータを表す行を構成する列の数
- 基数:1 つの表を構成する行の数
- テーブルを集合とみなしたときの要素数
- 本曰く「次数は変わることはありません」
- テーブル定義を変えると変わる
- 実際にテーブル定義を変えることはよくある:特に開発中は。
- 機能追加・改修案件で追加されることもよくある
- 1 行は 1 組のデータを表す:表に対するデータの追加・削除で基数はよく変わる
P.295 定義域(ドメイン)¶
- テーブル全体を $\mathcal{T} = A \times B \times \cdots \times Z$ と書いたときの各 $A,B,\dots,Z$ をドメイン(定義域、domain)と呼ぶ
- 数学の集合と違って $\mathcal{T}$ の中に同じ集合を含まない:つまり $\mathcal{T} = \mathbb{R}^n$ といったテーブルは考えない
- ドメインは「属性が取り得る値の集合」
- RDB では適当なデータ型を対応させる:日付,金額,数量,量
- ドメインを新たなデータ型として定義すると違うデー タ項目でも同じ入力チェックや同じ出力編集ができる
P.296 6.2.2 関係データベースのキー¶
- 表中の行を一意に識別するためのキー(スーパキー,候補キー,主キー)
- 別の表を参照し関連づけるための外部キー
P.296 スーパキー¶
- 表中の行を一意に特定できる属性,あるいは属性の組
- 組について:購入履歴を知るためにはユーザーID・商品ID・購入日がわからないといけない、という程度の意味
- かなり広い意味のようなのでたぶんそんなに使わない
- 補足:なぜスーパ「ー」キーではないのか
- 参考
- JIS の規格がある
- その言葉が 3 音以上の場合には,語尾に長音符号を付けない:ブラウザ、プリンタ、スキャナ、ドライバ、フォルダ、モニタなど
- その言葉が 2 音以下の場合には,語尾に長音符号を付ける: キー、バー、エラーなど
- 参考 2:「サーバー」と「サーバ」、どっちが正解? - 【ビジネス用語】
- 参考
P.296 候補キー¶
- 行を一意に決めるための必要最小限の属性で構成されるスーパーキー
- 一意性制約が必要
- 何かの履歴のように複数のIDの組になることもある
- 外部キーが入るテーブルでよくある
P.296 主キー¶
- 複数存在する候補キーの中から任意に選んだ1つの候補キーを主キー(primary key)
- 主キーに選ばれなかった残りの候補キーを代理キー(alternate key)
- 主キー制約
- 一意性制約
- 実体を保証するため空値(NULL)は許さないという NOT NULL制約
P.296 外部キー¶
- 関連する他の表を参照する属性あるいは属性の組
- 2 つの表の間に「1対多」の関係がある場合
- 「多」側の表に「1」側の表の主キーあるいは主キー以外の候補キーを参照する属性をもたせて外部キーにする
- 参照制約:外部キーの値が外部キーで参照される表に存在することを保証
- 参照制約があると「親テーブル」のカラムを勝手に消せなくなる
- 複数の表を参照するなら表内に複数の外部キーを持つ
- 外部キーの値に NOT NULL 制約がなければ NULL が許される
- 一般に外部キーは被参照表の主キーを参照
- UNIQUE 指 定 さ れ た候補キーを参照する場合もある
- cf. 参照制約:P.320
P.297 COLUMN 代用のキー設定¶
- 主キーが複数の属性から構成される複合キー(連結キー)でその構成属性数が多すぎると運用が面倒
- 連番のような必ずしも積極的な意味がない属性を追加してそれを代用のキー(surrogate key)にする
- 複合キーを構成している属性はすべて非キー属性にして代理キーにする
P.298 6.3 正規化¶
P.298 6.3.1 関数従属¶
- 関数従属:ある属性xの値が決まると他の属性yの値が一意的に決まる関係で、$x \mapsto y$ と書く
- 属性 $x$:独立属性(決定項)
- 属性 $y$:従属属性(従属項)
- 正規化:1 つの表の中の属性間にある関数従属性に着目して整理する
- 整合性を維持しやすいデータベースが設計できる
P.298 部分関数従属¶
- 関係 $x \mapsto y$ で $y$ が $x$ の真部分集合に関数従属するとき、$y$ は $x$ に部分関数従属するという
- どこの業界の用語なのかよくわからない。情報系?
- 部分関数従属は独立属性 $x$ が複数の属性からなるときに起こりうる関数従属
- あまりピンとこない:P.299 に商品マスタ的な例が載っていた
- 本の例:独立属性 $x$ が $x_1$ と $x_2$ の 2 つの属性からなるとき
- ${x_1, x_2} \mapsto y$ が成り立ち、かつ $x_1 \mapsto y$ または $x_2 \mapsto y$ のどちらかが成り立つ
- このとき ${x_1, x_2 }$ と $y$ の間に部分関数従属がある
- 例:社員所属部門テーブル
- 社員番号・部門コード・部門名があるテーブル
- 主キー:社員番号と部門コード
- 部門コードに対して部門名は一意に紐づく
- このとき部門名は主キーに部分関数従属する
P.298 完全関数従属¶
- 完全関数従属:関係 $x \mapsto y$ で $y$ が $x$ のどの真部分集合にも関数従属しない
- 独立属性 $x$ が 1 つの属性かなるときは常に完全関数従属
P.299 推移的関数従属¶
- 直接ではなく間接的に関数従属している関係
- 例:社員マスタ
- 社員番号・社員名・住所・郵便番号からなるテーブル
- 社員番号から住所が一意に紐づく
- 住所から郵便番号が一意に紐づく
- 郵便番号は社員番号に推移的関数従属している
- 念のため:住所は住所マスタなどに外出し(正規化)するべきで、こういうテーブルを作ってはいけない
- 詳しくは次の 6.3.2 で議論される
P.300 6.3.2 正規化の手順¶
P.300 第 1 正規化¶
- 非正規:くり返し部分をもつテーブルのこと
- まずもってくり返しという言葉の理解自体がたぶん面倒
- いろいろな例に触れてみよう
- RDB は平坦な 2 次元の表(テーブル)
- くり返し部分をもつ表から繰り返しを排除してスリム化したい
- 第 1 正規化:くり返しを排除する操作
- 第 1 正規形:第 1 正規化して得られた表のこと
- cf. P.300 図6.3.4 の売上表
- P.300 図 6.3.5
- 売り上げ明細表:主キーの売上番号とくり返し部分を一意に決める商品番号が複合キー
- 別の表に分解する
- 外部キー:他のテーブルの主キーである売上番号を参照している
- 分解・独立させた表に元の表の主キーをもたせる理由:結合で元の表を再現するため
P.301 第1正規形におけるデータ操作での不具合¶
- 第1正規形になった表は RDB 上で定義できる
- データの冗長性のためにデータ操作時に不整合を起こさないように注意が必要:更新時異常の概念
- 種類は以下の通り
- 例は本 P.300 の売り上げ表・売上明細表から
- 第 1 正規形では以下のような更新時異常が起きる可能性がある
- 防止策が第 2 正規化・第 3 正規化
- どこまでどうやるかは状況次第
P.301 修正時異常¶
- 商品名「オレンジ」を「清見オレンジ」に変更したい
- 該当する行をすべて同時に変更しなければならない
- 1行でも変更し忘れるとデータ不整合が起きる
- 先に対策を書いておく
- 売上明細には商品番号だけ持たせて、商品名を削る
- 削った代わりに商品テーブルを作る
- (ふつう商品テーブルには単価も切り出す)
- (単価に消費税を載せるかどうかといった問題もある)
P.301 挿入時異常¶
- 売上明細表の主キーは売上番号と商品番号の複合キ ー
- 売上のない("売上番号"が空値)商品は登録できない
- どうやらこの本の「売上表」は商品テーブルも兼ねているらしい
- 先に対策
- 商品テーブルを別に作って、そこからの参照という形にする
P.301 削除時異常¶
- (先程と同じくこの本の売り上げ表は商品テーブルも兼ねている模様)
- 売上実績が 1 つしかない商品のの売上データを削除す ると商品データも削除される
- 逆に商品データを残そうとすれば売上データは削除できない
- 先に対策:商品テーブルを切り出す
P.301 第2正規化¶
- 第2正規化:すべての非キー属性が各候補キーに完全関数従属である状態にする操作
- 第1正規形の表に対して行われる操作
- 候補キーの一部に部分関数従属する非キー属性を別の表に分解する
- 第2正規化して得られた表を第2正規形という
- 例:図6.3.7の売上明細表
- 候補キーは主キーの{売上番号,商品番号}の1
- 非キー属性である商品名と単価は主キーの一部である商品番号に部分関数従属している
- 商品表として独立させる
- 分解の仕方
- 商品表の主キーを商品番号
- 図6.3.7の上の表を再現できるようにする
- 売上明細表(図6.3.7の下の表)には商品表の主キーを参照する外部キーとして"商品番号"を残す
P.302 メモ¶
- 第2正規化するのは候補キーが複数の属性で構成されている場合。
- 1つの属性で構成されているのであれば部分関数従属は存在しない
- 既に第2正規形
- 非キー属性:どの候補キーにも属さない属性
- 第2正規形:どの非キー属性も候補キーの真部分集合に対して関数従属しない
- どの非キー属性も候補キーに完全関数従属
P.302 第3正規化¶
- 第3正規化:非キー属性間の関数従属をなくしてどの非キー属性も候補キーに直接に関数従属している状態にする
- 第2正規形の表に対して行われる操作
- 候補キーに推移的関数従属している非キー属性を別の表に分解
- 第3正規化して得られた表を第3正規形
- 例:図6.3.8の売上表
- これは第2正規形
- 顧客番号→顧客名いう非キー属性間の関数従属がある
- 顧客番号を主キーとした顧客表として独立させる
- 売上表には顧客表の主キーを参照する外部キーとして顧客番号を残す
P.303 メモ¶
- 第3正規形:どの非キー属性も候補キーに推移的関数従属しない
- どの非キー属性も候補キーに直接に関数従属している
- ボイス・コッド正規形
- 第3正規形では次の関数従属が存在する可能性がある
- 候補キーの真部分集合から他の候補キーの真部分集合への関数従属
- 候補キー以外の属性から候補キーの真部分集合への関数従属
- この関係を分解したのがボイス・コッド正規形
- 第3正規形では次の関数従属が存在する可能性がある
P.303 正規化と非正規化¶
- 正規形には第1正規形から第5正規形まである
- たいていの用途ではデータベースの場合、第3正規形まで正規化されていれば十分といわれている
- 正規化の目的はデータ操作にともなう更新時異常の発生を防ぐこと
- 属性間の関数従属を少なくする
- データの重複を排除する
- 正規化のデメリット
- 表がいくつにも分割される
- 必要なデータを取り出すために表を結合しないといけない
- 処理時間がかかる
- 処理速度が必要な時や更新時異常の発生が低い場合はあえて正規化しない・正規化を解く
- たとえば更新が少ない表は正規化しない
- ここでの「非正規化」:アクセスパターンを考えたうえでどの表を統合するか、どの属性を表間に重複させるか考える
P.304 6.4 関係データベースの演算¶
P.304 6.4.1 集合演算¶
- 関係データベースでの集合演算
- 同じ型の表間での和、共通部分(積)、差
- 直積:同じ型の表でなくてもいい
P.304 和、共通(積)、差¶
- 図6.4.1の表AとBに対するそれぞれの演算結果を見る
- 本参照
P.305 直積演算(Cartesian Product:×)¶
- 社員表と部門表の直積は社員表の各行に対して部門表の行を1つずつつなぎ合わせた表
- 直積の結果として得られる新しい表を直積表と呼ぶ
- 次数(属性の数)は両方の表の次数を足した数
- 位数(タプルの数)は両方の位数を掛けた数
- 直積が役に立つイメージがない:実際には結合 (JOIN) を本当によく使う
P.305 6.4.2 関係演算¶
- 関係演算:関係データベース特有の演算
- 射影,選択,結合,商
- 関係代数:関係演算と集合演算を合わせた代数
- 導出表:これらの演算によって得られた表
P.306 SQL の例¶
- 先に持ってきてみた
SELECT 社員コード, 社員名, 部門表.部門コード, 部門名
FROM 社員表, 部門表
WHERE 社員表.部門コード = 部門表.部門コード
P.305 選択と射影¶
- 選択演算:表から指定した行を取り出す関係演算
- SQL でいう WHERE
- 射影演算:表から指定した列を取り出す関係演算
- SQL でいう SELECT column_name
P.306 結合¶
- 参考:P.306 の下の表
- 結合演算:2つの表が共通にもつ項目(結合列)で結合して新しい表をつくり出す関係演算
- まさに正規化でわけたテーブルを結合させる演算
- SQL:SELECT文のFROM句で複数の表名をカンマで区切って指定
- WHERE句で結合条件を指定
- 結合条件
- 結合列の値を>,≧,=,≠,≦,<のいずれかの比較演算子で比較して結びつける
- 等結合:比較演算子が「=(等号)」である結合
- 2つの表から作成される直積表から結合列の値が等 しいものだけを取り出す
- 得られた新たな表には結合列が重複して含まれる
- SELECT句でどちらか一方の結合列を指定して見かけ上の重複を除く
- 自然結合(natural join):重複する結合列を取り除く(一方のみ残す)ようにした結合
- 結合列の列名が2つの表で同じ場合に使える
- 参考
- (意識的に使ったことがない)
P.307 内結合と外結合¶
- 参考:P.307 の図 6.4.8
- 内結合(INNER JOIN)
- 結合列の値が等しい行だけを取り出す結合演算
- 片方の表にしか存在しない行は取り出せない
- データベース言語仕様(JIS X 3005)
- 外結合(OUTER JOIN)
- 片方の表にしか存在しない行も取り出せる結合
- 結合相手の表に該当するデータが存在しない場合はNULL(空)値で結合
- 左外結合・右外結合・完全外結合
- 等結合
- 結合する表をFROM句で指定、結合条件はWHERE句 で指定
- 内結合・外結合
- 結合する表をFROM句の中でJOINを使って指定
- 結合条件は JOIN に続くON句で指定する
- 参考:p309のコラム「内結合と外結合のSQL文」
P.307 左外結合(LEFT OUTER JOIN)¶
- 参考:P307 図 6.4.9、P309 の SQL 文
- 結合する左の表(社員表)が基準
- 右の表(部門表)に存在しない行を空値(NULL)として結合
P.308 右外結合(RIGHT OUTER JOIN)¶
- 参考:P.308 図 6.4.10
- 結合する右の表(部門表)が基準
- 左の表(社員表)に存在しない行をNULLとして結合
P.308 完全外結合(FULL OUTER JOIN)¶
- 参考:P.308 図 6.4.11
- 片方だけに存在する場合もう片方をNULLとして結合
P.308 商¶
- (これ何だろうか?where の
in?)- 普通に
inまたは =`= でよさそう? selectも含んでいる?
- 普通に
- 参考:P.308 図 6.4.12
- 関係R(X,Y1,Y2)とS(Y3,Y4)がある
- S(Y3,Y4)のすべての行がR(Y1,Y2)に含まれる場合に対応するR(X)を求める演算
- 商(R÷S)は関係Rの中から関係Sのすべての行を含む行を取り出し、そこから関係Sの項目を除く
- 重複行も除く
- 参考:P.309、図6.4.13
- 社員表から東京に住み営業2課(E02)に勤務する社員を探す場合に商演算を使う
P.309 COLUMN ない結合と外結合の SQL¶
- 本を読もう
P.310 6.5 SQL¶
P. 310 6.5.1 データベース言語SQLとは¶
- SQL(Structured Query Language)
- RDB の標準的な操作言語
- ほとんどの RDBMS が SQL を使っている
- Relational DataBase Management System
P.310 SQLの分類¶
- RDB のデータを検索(参照)、操作
- データ定義
- トランザクション制御
- 参照:表 6.5.1 に SQL 文が書いてある
P.310 表 6.5.1 重要な SQL¶
- DDL (Data Definition Language)
- CREATE, DROP, GRANT, REVOKE
- DML (Data Manipulate Language)
- SELECT, INSERT, UPDATE, DELETE, COMMIT, ROLLBACK, DECLARE CURSOR, OPEN, FETCH, CLOSE
- DECLARE CURSOR以降は親言語方式などで使用されるSQL
- 親言語方式
- CやCOBOLなどのプログラム中にSQL文を組み込んでデータベースにアクセスする方式。
- 埋込みSQL:p328参照
P.311 6.5.2 SELECT文¶
- データ操作言語(DML)
- 問合せ(SELECT)文
- 挿入(INSERT)文
- 更新(UPDATE)文
- 削除(DELETE)文
- などなど
- SELECT文以外のDMLは「6.5.3 その他のDML文」(p319)参照
P.311 SELECT文の構文¶
- SELECT文の基本構文
- [ ]内は省略可能
SELECT
[DISTINCT]
列名のリスト
FROM 表名のリスト
[WHERE 選択条件や結合条件]
[GROUP BY 列名のリスト]
[HAVING グループ選択条件]
[ORDER BY 列名のリスト]
- リスト:列名および表名をカンマ(,)で区切って列挙したもの。
P.311 行、列の取り出し¶
- 選択:WHERE句に選択条件を指定すると特定の行を取り出せる
inとリストを使うと複数行に対する- 具体例を考えないと使い分けや気分はわからなそう
- 射影:SELECT句に列名を指定すると特定の列を取り出せる
- SELECT句への
*:全部の列を取りだす - 選択条件と論理演算子(AND・OR・NOT):複数の条件を組み合わせる
- 表 6.5.2:選択条件に使う比較演算子の表
- 参考:列の値が「空値(NULL)であるか」という検索条件
WHERE 列 IS NULLWHERE 列 = NULLではない- NULL は他にもいろいろ邪悪な面がある
- 空文字列などとは違う概念でよくはまる
SQL 例¶
- P.312、図 6.5.1
- 社員表から年齢が24以上28以下の社員コード・社員名を表示するサンプル
SELECT 社員コード, 社員名 FROM 社員表 WHERE 年齢 >= 24 AND 年齢 <= 28
P.312 BETWEEN述語¶
- 先のSELECT文はBETWEEN述語やIN述語を使って同じ内容を表せる
- BETWEEN述語は「値1~値2」の範囲(値1,値2を含む)に列の値が含まれるかを選択条件にする
SELECT 社員コード, 社員名 FROM 社員表 WHERE 年齢 BETWEEN 24 AND 28
P.312 IN述語¶
- IN述語は列の値が指定された値のいずれかと等しいかを選ぶ条件にする場合に使う
- INの前にNOTをつけると指定された値のいずれでもないという選択条件になる
- IN述語の使用例については副問合せ(p317)も参照
P.313 重複行の排除¶
- 取り出された行の中から重複するものを除きたい場合
- SELECT句の列名指定にDISTINCT述語を使う
P.314 出力順の指定¶
- ORDER BY 句:特定の列の値で昇順・降順に並べ替えて表示する
- ORDER BY のあとに続けて並べ替えのキー(列名)を指定
- 降順の場合はDESC、昇順の場合はASC
- ふつう ASC がデフォルトで省略できる
SELECT 社員名, 年齢 FROM 社員表 ORDER BY 年齢 DESC
P.314 グループ化¶
- GROUP BY 句:取り出した行を指定した列の値でグループ化
- グループごとの合計や最大値などを求める
- HAVING 句:条件に合ったグループだけを取り出す
SELECT 所属, COUNT(), AVG(年齢) FROM 社員表 GROUP BY 所属 HAVING COUNT() >= 2
- SQL の簡単な解説
- 社員表のデータをGROUP BY句を使って所属でグループ化
- HAVING 句で「グループに所属する人数が2人以上」のグループだけを取り出す
- 取り出したグループごとにその所属・人数・平均年齢を求める
P.315 表の結合¶
- 2 つの結合
SELECT A FROM B WHEREによる等結合FROM句の中でのJOIN ... ONによる内結合や外結合
- どちらであっても結合表には結合条件で指定した結合列が重複して含まれる
- 列名を指定するときは「表名.列名」という形式で表す
P.316 表に別名をつける¶
- FROM句で「表名 AS 別名」あるいは「表名 別名」と指定すると表名に対して別名(相関名)を設定できる
- 自己結合:表に別名を与えると同じ表どうしを結合できる
- 自己結合については P.317 の例を参照
- 上司コードを使ってある社員とその上司の氏名や関連情報を見たい場合に使う
P.317 副問い合わせ¶
- サブクエリともいう
- SELECT文のFROM句やWHERE句・HAVING句などに指定されている入れ子になったSELECT文
SELECT 社員コード, 社員名, 年齢 FROM 社員表 WHERE 年齢 IN (SELECT 指定年齢 FROM 調査対象)
- サブクエリにはいろいろ面倒な話がある
- 参考:MySQL のサブクエリって、ほんとに遅いの?
- これは 2017 年の記事:この辺はお金になるので割と日進月歩で、3 年程度の昔の情報でも既に参考にならないことも多い。
- 簡単なまとめ
- 遅いのは2番目、DEPENDENT SUBQUERYである
- MySQL 5.5 までサブクエリはやっぱり遅い
- MySQL 5.6 からはそんなに遅くなくなった
- MySQL とはいってもバージョンによって全然違う:オプティマイザは進化している
- 現状についてはきちんと最新の話を追う、または自分が必要なケースについて実測する
P.318 EXISTS述語¶
- サブクエリはEXISTS述語でも表せる
- 参照:P.318 の例
- EXISTS は相関副問合せが何らかの結果を返した場合にTRUE(真),何も返さなかった場合にFALSE(偽)を返す
- 主問合せの結果1行に対して相関副問合せから何らかの結果が戻されれば、主問合せの選択条件は成り立ち、何も返されなければ選択条件は成り立たない
- EXISTS 述語でほかの表にも存在するものを調べられる
- ANY でも同じ操作を表せる
- 参考:P.318 の例
- 副問合せの結果のいずれか(ANY)と等しい
- どれがいいかは最終的にはテーブルの実装や使っている RDBMS とバージョンに依存する
- 実測してチューニングしよう
P.319 6.5.3 その他の DML 文¶
P.319 INSERT文¶
- 表に行を挿入する:2つ方法がある
- 参考:本の P.319
- 挿入する値をVALUES句で指定する
- 問合せの結果をすべて挿入する
- (DBMS によるかもしれないが)個別INSERTと一括INSERTもある:パフォーマンスでよく問題になる
- 一部の列に対して INSERT
- どの列に対して挿入するのか列名リストで指定
- 省略された列の値はDEFAULT制約があればその既定値、そうでなければNULL値
- NULL はなるべく使うのをやめよう
- DEFAULT は P.322 表 6.6.1
P.319 UPDATE文¶
- 表中のデータを変更
- 列の変更値を直接指定する
- 変更値をCASE式で決める
- 副問合せの結果を変更値にする
- SET句には変更したい列の値を「列名 = 変更値」の形で指定
- 1 つのUPDATE文で複数の列の値を変えるときはカンマ(,)で区切って指定
- WHERE句を省略すると表中のすべての行が変わる
- ふつうはやらない
- WHERE句を指定すれば条件に合った行だけ変わる
P.320 DELETE文¶
- 表中の行を削除する
- 表中の全行を削除しても表自体は残る
- 表を削除するのはDROP文
- WHERE句を省略すると表中のすべての行が削除される
- WHERE句を指定するとその条件に一致した行だけを削除できる
P.320 参照関係をもつ表の更新¶
- 関連する2つの表の間に参照制約が設定できる
- 被参照表の主キー(候補キー)にない値を参照表の外部キーに追加できない
- 被参照表の行の削除・変更時に制約が出る:図6.5.10参照
- 参照動作指定:削除・変更時の制約は明示的に指定できる
- 次節のCREATE TABLE文を参照
- REFERENCES句(参照指定)の後に次の構文で指定
参照動作指定 REFERENCES 被参照表(参照する列リスト) ON DELETE 参照動作] [ON UPDATE 参照動作] (*[ ]内は省略可能)
- 指摘できる参照動作:表 6.5.5 の 5つ
- デフォルトは NO ACTION
P.320 補足¶
- 参照制約
- 外部キーの値が被参照表の主キーあるいは主キー以外の候補キーに存在することを保証する制約。
- 関連する2つの表の間に参照制約を設定する目的:データ矛盾を起こすような行の追加や削除・変更を排除するため
- REFERENCES指定:p322-324を参照
- データの整合性を保つための制約
- 一意性制約
- 参照制約
- データ項目のデータ型や桁数に関する形式制約
- データ項目が取り得る値の範囲に関するドメイン制約がある。
P.322 6.6 データ定義言語(DDL)¶
P.322 6.6.1 実表の定義¶
P.322 CREATE TABLE文¶
- 表の定義はには CREATE TABLE 文
- 基本構文は P.322 参照
P.322 列制約¶
- 表を構成する列に対する制約
- 参考:表6.6.1
- 一意性制約:同一表内に同じ値が複数存在しないことを保証する制約
- 主キーとなる列には一意性制約にとNOT NULL制約を加えたPRIMARY KEY指定
- 主キー以外の候補キーにも一意性制約がある
- 一般にNULL(ナル)値は重複値とは扱われない
- 候補キーにはNULL値を許すUNIQUE指定
- 参照制約:外部キーの値が被参照表に存在することを保証する制約
- 外部キー:REFERENCES指定(参照指定)す。
P.323 表制約¶
- 一意性制約・参照制約・検査制約は表制約(表定義の要素として定義される制約)にもできる
- 列制約:1つの列に対する制約
- 主キーや外部キーが複数列から構成される場合、これを列制約として定義できない
- このときは表制約を使う
P.323 主なデータ型¶
- 一般的な文字型,数値型は覚えておくといい
P.324 実表の定義例¶
- P.324 の社員表と部門表を定義を見てみよう
P.325 6.6.2 ビューの定義¶
P.325 ビューとは¶
- 実表:ディスク装置上にあり実際にデータが格納される表
- ビュー:実表の一部または複数の表から必要な行や属性(列)を取り出してあたかも1つの表 であるかのように見せかけた仮想表
- 利用者から見れば実表と同じ
- データを検索するだけなら制約はあっても同じように操作できる
- ビューのメリット
- あくまでも仮想の表:対象となった元の表(基底表)の列名と別の名前で定義できる
- ビューに定義することで情報を公開
- ビューに定義しないことで情報を非公開にできる
- 元の表に新たな列が追加されても既存のビューには影響がなく再定義する必要がない
- ビューは仮想的な表
- 一般には実体化されずデータ格納領域をとら ない。
- 実表のように実体化されるビューもある:体現ビュー(materialized view)
P.325 CREATE VIEW文¶
- ビューの定義:CREATE VIEW文による:詳細は本の P.325
- ビュー:対象となる実表(あるいは他のビュー)からSELECT文で必要データを導出する方法で定義される定義するビューの列名に命名規則はない
- 列数はAS句に続くSELECTで問い合わせた結果の列数と同じでなければならない
- 列名は省略可能:省略した場合はSELECTで問い合わせた結果の列名がそのまま定義される
- ビューに対する参照や更新処理
- ビューの対象となった表(基底表)に対す る参照あるいは更新処理に変換されて実行される
P.326 ビューの定義例¶
- 本の P.326 参照
- 社員表と部門表から社員コードと社員名、その社員が所属する部門名からなる表をビュー「社員表2」
- JOIN して必要なカラムだけ取り出す
P.326 ビューの更新¶
- ビューへの更新処理 ビュー定義を基にビューが参照している表(基底表)への対応する処理に変換されて実行
- 更新のための条件
- 更新にかかる実際の表が更新可能
- 更新される表の列や行が一意に決まる
- 更新できないビューの例
- SELECT句で式、集合関数、DISTINCT を使ったSELECT文で定義されている
- ・GROUP BY句やHAVING句を使ったSELECT文で定義されている
P.327 6.6.3 オブジェクト(表)の処理権限¶
- スキーマに定義された実表やビューはそのスキーマ所有者(作成者)にしか処理権限が与えられない
- 複数の利用者がデータベースを利用できるようにしたければ、スキーマ所有者以外にも処理権限を付与する必要がある
- データベース管理ユーザーは全権を持っていて危険な処理もできてしまう
- できることを制限したユーザーで操作したい
- オブジェクト(表)の処理権限
- 読取(SELECT)権限
- 削除(DELETE)権限
- 挿入(INSERT)権限
- 更新(UPDATE)権限
- cf. スキーマ
- 1つのデータベースの枠組み
- スキーマ内に複数の表やビューを定義できる
P.327 処理権限の付与¶
- 権限の付与:GRANT文による
- GRANTの基本構文は次の通り
1 | |
- 権限指定
- 4 つの処理権限(SELECT,INSERT,UPDATE,DELETE)
- ALL PRIVILEGES(すべて)を指定できる
- 権限を複数付与する場合はカンマ(,)で区切って指定
P.327 処理権限の取消し(変更)¶
- 一度付与された権限を取消し(変更)できる
- 権限の取消しはREVOKE文
- REVOKEの基本構文
1 | |
P.328 6.7 埋込み方式¶
P.328 6.7.1 埋込みSQLの基本事項¶
P.328 静的SQLと動的SQL¶
- 静的 SQL:あらかじめ決められたSQL文をプログラム中に埋込んで実行する方式
- 実際のアプリケーションではあまり見かけない
- 非カーソル処理:データベースの表から1行を取り出すこと
- 次のような SELECT 文
- この
INTOを見たことがない
SELECT 社員名, 年齢 INTO :name, :age FROM 社員表 WHERE 社員コード = '100';
- 動的 SQL:実行する SQL 文がプログラム実行中でな ければ決まらない場合に SQL 文を動的に作成し実行する方式
- 上の社員コードがふつう変わる:それが「動的」。
- この動的な部分に変なコードを埋め込むとまずいというのがセキュリティ問題で、例えば SQL インジェクションの問題。
P.328 ホスト変数¶
- ホスト変数:データベースとプログラムのインタフェースとなる変数
- 埋め込み SQL では SQL を実行すると取り出されたデータをINTO句で指定したホスト変数に格納する
- ホスト変数は通常の変数としてもアクセスできる
- 出力関数で表示
- 入力関数で値を入力してそれをSELECT文の条件としても使える
P.329 6.7.2 カーソル処理とFETCH¶
P.329 カーソル処理¶
- 「SELECT・・・・INTO・・・」形式では,1行のデータしか取り出せない
- (見たことがないのでイメージがつかない)
- 検索結果が複数行の場合は1行ずつ取り出せるカーソル処理を使う
- カーソル処理は SQL 文で問い合わせた結果をあたかも1つのファイルであるかのようにとらえる
- FETCH文でそこから1行ずつ取り出す方式
- 1つのSELECT文に対してカーソルを宣言(定義)
- カーソルのオープンでSELECT文が実行
- カーソルで1行ずつ取り出せる
- FETCH文で繰返し行を取り出して処理
- 終了したらカーソルを閉じる
P.330 FETCHで取り出した行の更新¶
- 参考:図 6.7.2:FETCHで取り出した行の更新処理
- FETCH文で取り出した行を更新あるいは削除する場合,FETCH文のあとに続くUPDATE文やDELETE文のWHERE句 に「WHERE CURRENT OF カーソル名」と指定する。
- (FETCH 文を見たことがないのでイメージつかない)
P.330 処理の確定と取消し¶
2020-12-06 課題¶
- 先に進む前に録画してあるか確認しよう
進捗¶
- 前回の進捗
- 基礎知識編:次数と基数まで
- 本編:04-01 の冒頭
- 今回の進捗
- 基礎知識編:6.3.2 正規化の手順まで
- 本編:「04-01 以下、高校数学水準で」
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 勉強の日常組み込み系
- Julia:The Little Book of Julia Algorithmsを読んでみることにしました。適当に話します。
- そのうち取り組む事案:黒木さんの Julia での統計ネタ
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
TODO¶
- AWS のハンズオン
- 公式のハンズオン: 無料でできるハンズオンもたくさんある
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- 実際に競プロの問題をいくつか解いてみましょう。
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
TeX の記録¶
- ゴルディングの不等式
\begin{align} \Vert s \Vert_{H^2_{k+1}} \leq C_k \left( \Vert Ds \Vert_{H^2_k} + \Vert s \Vert_{L^2} \right) \end{align}
日々の勉強¶
Julia¶
- The Little Book of Julia Algorithms
- リポジトリの対象ディレクトリ:ここ
- その他参考
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- ネットワークの話もいい加減飽きたので、しばらく DB の話
復習¶
- 3 つのスキーマ
- ユーザーが見るレベル
- 正規化などをかけておいたデータベースにもっていけるレベル
- 個々のデータベースに合わせた具体的なレベル
- インメモリの DB:コンピューターの基本的なハードウェア構成と意味を復習しよう
本の記述を追いかける¶
P.408 7.8 交換方式¶
P.408 パケット交換方式¶
- 回線交換方式と対になる概念
- 回線交換方式:通信を行うノード間で物理的な通信路を確保してから通信する
- 例:電話
- パケット交換方式について
- データ送信するノードはデータをパケットに区切る。
- ひとつひとつのパケットにヘッダを付けて送信。
- ネットワーク内ではパケット交換機にパケットがたまる
- ネットワークの状況に応じて順次送られる
パケット通信のメリット・デメリット¶
メリット¶
耐障害性 - 通信路を固定しないため,迂回経路が取れる。 - パケット交換機にデータが蓄積されているため,復旧まで待てる。 - パケット多重 - 1 対 1 の通信で回線を占有する必要がないため,1つの回線を多くのノードで共有でき,回線を効率的につかえる - 異機種間接続性 - パケット交換機で中継するときにプロトコル変換・速度変換でエンドノードどうしが同じプロトコルをサポートしていなくても通信できる
デメリット¶
- ネットワーク内の蓄積交換処理による遅延
- 蓄積交換処理による遅延解消のために主に回線の帯域を広げることで対応してきた
- 構造上,完全には遅延をなくせない
- パケット到着順序の不整合
P.408 ATM 交換方式¶
- ATM(Asynchronous Transfer Mode:非同期転送モード)
- 遅延のない回線交換方式とパケット交換方式の利点を得たい
- パケット交換方式の発展
- 遅延の原因をつぶす:特にパケットの多様性
- 多種多様なパケットに対応するために,パケット交換機はソフトウェア処理が必要 ^ ATM での工夫の一例:最も特徴的なのは,パケット(ATMではセルという)の長さをヘッダ部 5 バイト,ペイロード 48 バイトの53バイトに統一
- パケット解析がハードウェアだけでできる。
- ソフトウェアは不要になった。
- Wikipedia から
- 当初の意図に反して非常に複雑な技術になってしまった
- ATM は次世代の主流にならず限定的な使用にとどまった
- ATM の設計思想は MPLS へと引き継がれた
- 汎用のレイヤ 2 のパケットスイッチングのプロトコルとして、ルーターを介したIPの通信網で利用されている。
P.408 ペイロード(payload)¶
- データ通信で本来転送したいデータ本体の部分、ボディを指す。
- ATM ではペイロードのサイズを固定して処理を簡素化
- 難点:パケット全体に占めるペイロードのサイズが相対的に小さくオーバヘッドが大きい
P.410 輻輳¶
- フレームリレー:パケット交換方式の一種
- 1 つの回線を多数のユーザで共有。
- 回線がもつ潜在的な伝送能力(ワイヤスピード)を十分に引き出すうえで効果がある
- 輻輳:ユーザの利用が一時期に集中すると,ワイヤスピードを超えるパケットがネットワーク上に流れる
- ネットワークが輻輳状態になるとスループットが落ちる
- フレームリレーサービスを提供する事業者は,ネットワークが輻輳状態に陥ってスループットが低下しても最低限保証する通信速度を決めている
- CIR(Committed Information Rate:認定情 報速度)
P.370 7 ネットワーク¶
- 確か 7.4 から始めた気がするので 7 章はじめから
P.370 7.1.1 OSI基本参照モデル¶
- 改めて復習
- OSI(Open System Interconnection)基本参照モデル- 異なる設計思想・世代のシステムと円滑に通信するのが目的に標準化
- プロトコルの単機能化,交換の容易さが目的
- 階層化のおかげで一部の階層の技術体系が変わっても、その階層だけ取り替えればいい
- コスト・リスクを小さくする
P.370 プロトコルとサービス¶
- N 層:それぞれの階層のこと
- エンティティ:N 層に存在する通信機器などの実体
- この言葉はいろいろなところで出てきていろいろな意味で使われる
- もちろん気分的には適当な実体を指すことが多い
- プロトコル:N 層に属するエンティティが通信するための取り決め
- 上位の層が下位の層を利用しながら通信する
- 別の階層間のエンティティどうしが通信する窓口が必要
- これを提供するのが下位層:この機能をサービスと呼ぶ
- プロトコルに沿った仕様で製品を開発すれば別のベンダの機器でも通信できる
- 参考:ベンダーロックイン
特定ベンダー(メーカー)の独自技術に大きく依存した製品、サービス、システム等を採用した際に、他ベンダーの提供する同種の製品、サービス、システム等への乗り換えが困難になる現象のこと。
出来上がった情報システムの正確な仕様が、システムを開発・構築したベンダーにしか解らなくなる場合がある。結果、システムの保守・拡張・改修等の際、現存システムを開発・構築したベンダーに引き続き発注せざるを得なくなる。
- 「Excel で行政に提出する書類を作れ」事案もそれ。
- Apple 製品で身の回りを固めるのも同じ。
- 「多様性が大事」事案でもある。
7.1.2 TCP/IPプロトコルスイート¶
- プロトコル同士には相性がある
- 「ネットワーク層がこのプロトコルならトランスポート層はこのプロトコルにしておくとトラブルが少ない」
- 一般に同じ団体が作ったプロトコルはセットで使われることが多い
- このセットがプロトコルスイート ^ 最も代表的なのは IP を中心に組まれた TCP/IP プロトコルスイート
- 独自の階層モデルをもつ
P.372 TCP/IPの通信¶
- データをパケットに区切る
- 各パケットにヘッダを付けて送信
- ヘッダは各階層ごとに付加されて次の階層へと渡される
- 各ヘッダにはその階層で必要となる送信元や送信先,大きさ,順番などパケット自体に関する情報を含む
- TCPヘッダを付加したパケット:TCP セグメント
- IP ヘッダを付加したパケット:IP パケット
- MACヘッダを付加したパケット:MAC フレームあるいはイーサネットフレーム
P.372 MAC(Media Access Control)アドレス¶
- イーサネットや FDDI で使用される物理アドレス
- イーサネット (Ethernet):コンピューターネットワークの規格の1つ。オフィスや家庭で一般的に使用されている有線LAN (Local Area Network) の技術規格
- FDDI:LAN でデータ転送を行うための標準の一つ
- Fiber distributed data interface
- データリンク層
- 同じネットワークに接続された隣接ノード間の通信で相手を識別するために使う
- MACアドレスの長さ:6バイト
- 先頭24ビットの OUI(ベンダID)
- 後続24ビットの固有製造番号(製品に割り当てた番号)
- MAC アドレスは機器が固有にもつ番号
- 必ず一意に定まるように IEEE が管理
P372 ポート番号¶
- トランスポート層にでノード内のアプリケーションの識別に使う識別子番号
- 0-65535の範囲
- TCP/IPではパケット交換方式でデータをやり取りする
- よく使われるアプリケーションについてのポート番号は Well-Known ポートとして標準化
- TCP・UDPそれぞれで 0-1023 番までの番号を割り当てている
- SSH:TCP22番
- Telnet:TCP23番
- SMTP:TCP25番
- HTTP:TCP80番
- POP3:TCP110番
- IMAP4:TCP143番
- HTTPS :TCP443番
- NTP:UDP123番
- SNMP:UDP161番
- SNMP Trap :UDP162番
- セキュリティ対策のために標準とはポート番号を変えることもある
- Web 開発の本を読んでいると、いろいろな都合から http のポートを 80 以外にしていることもよくある。
- 80 の場合はポートを指定しなくてもいい
- 例:http://localhost/hoge/fuga
- 例:http://localhost:5000/hoge/fuga
- 80 の場合はポートを指定しなくてもいい
P.373 ネットワーク間の通信¶
- 同じネットワークに接続されたノード間はデータリンク層(第 2 層)の通信
- ネットワークを超えたノード間はネットワーク層(第 3 層)の通信 -実際に図 7.1.4 を見よう
- どこが IP アドレスでのやりとりか?
- どこが MAC アドレスでのやり取りか?
P.374 7.2 ネットワーク接続装置と関連技術¶
P.374 7.2.1 物理層の接続¶
P.374 リピータ¶
- ネットワーク上を流れる電流の増幅装置・整流装置
- 物理層:第 1 層
- データ通信はネットワーク上を流れる電流
- ケーブルが長いと電流が減衰・波形が乱れが起きる
- データが読み取れなくなる
- これを増幅するのがリピータ
- 大昔の電話は距離が遠いと音が小さく聞こえにくかった
- まさにこの減衰が問題
- リピータは 1:1 で繋ぐ
- 現在では複数のノードを接続できるマルチポートリピータ(ハブ)が使われるのが一般的
P.374 7.2.2 データリンク層の接続¶
- 第2層
P374 ブリッジ¶
- データリンク層に位置
- ネットワーク上を流れているフレーム(情報の単位)の MAC アドレスを認識して通信を中継する
- 接続されているノードをコリジョンドメイン(セグメント)という単位に分割
- MAC アドレスで判定したフレームのあて先のあるセグメントだけにフレームを送信
- 無駄なトラフィックの回避
- ポートの記憶
- 通信のたびにある MAC アドレスをもつノードがどのポート に接続されているか学習
- 次回の通信時には余分なポートには通信を中継しない。
- ブリッジの動作
- あて先MACアドレスをもとにMACアドレステーブルを参照する
- あて先MACアドレスの接続ポートがフレームを受信したポー トと別ポートであれば,そのポートにフレームを送信し
- 同一ポートであればフレームを破棄する
- あて先MACアドレスが記憶されていない場合やブロードキャス トアドレス(FF-FF-FF-FF-FF-FF)の場合は,受信ポート以外のすべてのポートにフレームを送信する
P.375 スイッチングハブ¶
- レイヤ2スイッチ(L2スイッチ)とも呼ばれる
- データリンク層に位置
- ブリッジと同じ働きをする
- MAC アドレスを認識してフレームのあて先を決めて通信を行います。
- 試験での問われ方
- スイッチングハブはフレームの蓄積機能、速度変換機能や交換機 能をもっている。
- このようなスイッチングハブと同等の機能をもち,同じプロトコル階層で動作する装置はどれか
- 答えは「ブリッジ」
P.375 ブロードキャストストリーム¶
- データリンク層で動作するブリッジやスイッチングハブなどの LANスイッチはブロードキャストフレームを受信ポート以外 のすべてのポートに転送
- これらの機器をループ状に接続し冗長化させると信頼性はあがる
- ブロードキャストフレームは永遠に回り続けながら増える
- 最終的にはネットワークダウンを招く
- この現象をブロードキャストストームという
- ブロードキャストストームを防ぐプロトコル:スパニングツリープロトコル(Spanning Tree Protocol:STP)
- ループを構成している一部のポートを通常運用時にはブロック(論理的に切断)する
- ネットワーク全体をループをもたない論理的なツリー構造にする
P.376 ネットワーク層の接続¶
- 第 3 層(レイヤ 3)
P.376 ルータ¶
- ルータはネットワーク層(第 3 層)に位置する
- あて先IPアドレスを見てパケットの送り先を決め通信を制御する
- IP のローカルネットワークの境界線に設置して利用され,ネットワークの基本単位として機能
- 世界中に散在しているローカルネットワークどうしをルータが結ぶ
- 全体としてインターネットというインフラが機能
- ルータで分けられたネットワークの単位をブロードキャストドメインという
- ルータがパケットを受け取ったあと
- あて先IPアドレスを見る
- 自分のネットワークあてであれば,破棄
- 他のネットワークあてであれば転送
- どのルータへ送ればあて先のネットワークへの通信が速く行えるかを判断することを経路制御(ルーティング)
- ルータはそのための経路表(ルーティングテーブル)を備えている
P.376 デフォルトゲートウェイ¶
- 会社Aのネットワークに属するPCは会社BのPCと直接通信できない
- 会社AのPCは他ネットワークへの接点であるルータAに転送を依頼
- デフォルトゲートウェイ:会社AのPCから見て直近のルータA
- 自分と直接接続していない相手と通信するときはすべてデフォルト ゲートウェイを中継する
P.376 ルーティング¶
- 経路表(ルーティングテーブル)の作成方法
- 手作業で作る:スタティックルーティング
- ルーティングプロトコル利用:ルータ同士が経路情報を交換し、自立的に経路表を作るダイナミックルーティング
- ダイナミックルーティングのための代表的なルーティングプロトコル:RIP、OSPF
- RIP:ディスタンスベクタ型(距離ベクトル型)
- ルーティングテーブルの情報(経路情報)を一定時間間隔で交換しあう
- あて先ネットワークにいたるまでに経由するルータの数(ホップ数)最小経路を選ぶ
- あて先に到達可能な最大ホップ数は 15
- これを超えた経路は採用されない
- OSPF:リンクステート型
- コストを経路選択の要素に取り入れ、コスト最小経路を選ぶ
- コスト値は,回線速度を基に自動的に算出されるが手動設定もできる
- コスト算出式「コスト=100Mbps/経路の通信帯域(bps)」
- コスト計算例は P.377 の図を見ること
P.377 ルータの冗長構成¶
- ルータを冗長構成のために使うプロトコル:VRRP(Virtual Router Redundancy Protocol )
- 同じ LAN に接続された複数のルータを仮想的に 1 台のルータ として見えるようにして冗長構成を実現する
- 複数のルータでグループ(VRRP グループ)を作る
- VRRP グループごとに仮想 IP アドレスと仮想 MAC アドレスを割り当て
- PC などのノードは仮想ルータの IP アドレスに対して通信
- 通常時はグループのマスタルータが仮想ルータの IP アドレス(仮想 IP アドレス)を保持
- マスタルータに障害が発生すると他のバックアップルータがこれを継承
P.377 レイヤ3スイッチ(L3スイッチ)¶
- ルータと同じネットワーク層(第 3 層)の通信機器
- 特徴
- ルータ:ソフトウェアで転送処理
- レイヤ 3 スイッチ:専用ハードウェアで転送処理
- 高速処理できる:大容量のファイルを扱うファイルサーバへのアクセスなど
P.378 トランスポート層以上の層の接続¶
P.378 ゲートウェイ¶
- トランスポート層(第 4 層)-アプリケーション層(第7層)でネットワーク接続するための装置
- 第 3 層のネットワーク層まででエンドツーエンド(E2E)の通信は完成する
- E2E = 通信を行う二者、あるいは、二者間を結ぶ経路全体
- エンドツーエンド原理:高度な通信制御や複雑な機能は末端のシステムが担い、経路上のシステムは単純に信号やデータの中継・転送だけすべし
- TCP/IP ネットワークの原理
- 誤り訂正・フロー制御・再送:TCP 層(第4層、トランスポート層)など上位側の機器やソフトウェア・プロトコル
- 単純な送受信・転送処理:IP 層(第3層、ネットワーク層)
- ゲートウェイ:第 4 層のトランスポート層以上が違う LAN システム相互間のプロトコル・データ形式の変換を担う
- ゲートウェイはアプリケーションプロトコルの内容を 解釈できる
- アプリケーションヘッダの不正な情報混入を検出可能
- ファイアウォール・プロキシサーバもゲートウェイの一種
P.378 L4スイッチ・L7スイッチ¶
- L4スイッチ(レイヤ4スイッチ)はトランスポート層(第4層)の装置
- 定義としてはゲートウェイ
- 機能的にはレイヤ2スイッチ・レイヤ3スイッチの延長上
- ルータやレイヤ3スイッチはIPアドレスを参照して経路制御する
- L4スイッチではTCPポート番号やUDPポート番号も経路制御判断に使える:第4層の機器だから
- L7スイッチ:アプリケーション層(第7層)までの情報を使って通信制御する
P.379 7.2.5 VLAN¶
- VLAN(Virtual LAN:仮想LAN)
- スイッチ(レイヤ2スイッチ,レイヤ3スイッチ)で物理的な接続形態とは独立に仮想的なLANグループを構成する仕組み,あるいはそう構成されたLAN
- 複雑な形態のネットワークを楽に構築できる
- サブネット構成も柔軟に変えられる
P.380 データリンク層の制御とプロトコル¶
- データリンク層:第2層
P.380 7.3.1 メディアアクセス制御¶
- 複数のデータを1つのケーブルを通して送受する場合,データの衝突(コリジョン)を回避するための制御が必要
- これがメディアアクセス制御(Media Access Control:MAC)
コリジョン(衝突)¶
イーサネットや無線LANで複数の端末が送信し、データが衝突する現象を指す。旧式のイーサネット規格では、端末同士を接続するときに1組の通信路で双方向の通信を行う半二重通信のため、送信と受信を同時に行うことができない。送信と受信をその都度切り替えて行うので、端末がお互いデータを送信してしまうと衝突する可能性が高くなる。
P.380 CSMA/CD¶
- CSMA/CD:Carrier Sense Multiple Access with Collision Detection:搬送波感知多重アクセ ス/衝突検出)の略。
- イーサネットで採用されている方式
- 衝突検知方式を採用
- イーサネット:IEEE 802.3として標準化されている LAN規格
- CSMA/CD
- 各ノードは伝送媒体が使用中かどうかを調べて,使用中でなければデータを送りはじめる
- 複数のノードが同時に通信しはじめるとデータの衝突が起こる
- 衝突を検知し,一定時間(ランダム)待った後で,再送
- 一定の距離以上のケーブルでは衝突が検知できない
- CSMA/CD方式の限界
- トラフィックが増加するにつれて衝突が多くなる
- 再送が増え,さらにトラフィックが増加する悪循環に陥る可能性がある
- 特に伝送路の使用率が30%を超えると実用的でなくなる
P.381トークンパッシング方式¶
- トークンによる送信制御を行う方式で
- トークンバス方式
- トークンリング方式
P.381 トークンパッシング方式¶
- ネットワーク上をフリートークンと呼ばれる送信権のためのパケットが巡回する
- フリートークンを獲得したノードだけが送信できるので衝突を避けられる
- ふつうはコンセントレータ(集線器)でネットワ ークとノードを結ぶ
- トークンパッシング方式を採用したLAN規格
- 例:FDDI:Fiber Distributed Data Interface
- FDDIは物理媒体に光ファイバを利用し,最大100Mビ ッ ト/秒の通信
- 特徴
- 伝送媒体上では衝突しない
- トラフィックが増えるにつれてトークンを獲得しにくくなり,少しずつ遅延時間が増える
- 衝突による再送制御の必要がないため伝送路の使用率に対する遅延時間の増加率はCSMA/CD方式より緩やか
P.382 TDMA 方式¶
- TDM(時分割多重)
- ネットワーク上にデータを送信する時間を割 り当てる(タイムスロット)
- タイムスロットごとに別のデータを送って多重化する
- TDM によるアクセス制御が TDMA
- TDMA(Time Division Multiple Access:時分割多重アクセス)
- CSMA/CD・トークンパッシング方式と並ぶ主要なデー タリンク技術
- TDMA ではネットワーク(伝送路)を使える時間を細かく区切る
- 割り当てられた時間は各ノードが独占する方式
- TDMAはコネクション型の通信
P.382 7.3.2 無線LANのアクセス制御方式¶
P.382 CSMA/CA方式¶
- CSMA/CA:Carrier Sense Multiple Access with Collision Avoidance、搬送波感知多重アクセス/衝突回避
- 無線 LAN の制御方式
- CSMA/CD との違い:「衝突検出」が「衝突回避」になった
- 無線 LAN:物理層媒体は電波で衝突の検出は不可能だから回避する
- 特徴
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
- 待ち時間をバックオフ制御時間とよぶ
- 衝突してフレームが壊れても検出できない
- データを受け取ったノードは ACK を返す
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
P.328 RTS/CTS¶
- 無線 LAN の話
- 隠れ端末問題
- 他のノードのデータ送信を感知できないことがある
- 通信ノード間の距離が遠い
- ノード間に障害物がある
- 回避のための RTS/CTS 方式
- 無線 LAN ノード
- データ送信前にRTS(Request ToSend:送信リクエスト)をアクセスポイントに送信
- これを受理したアクセスポイントがCTS(Clear to Send:送信OK)を返信
- 他のノードは CTS を傍受して自分以外の別のノードに送信権があると解釈
- データ送信を延期
- 無線LANノードはアクセスポイントからCTSを受信したらデータ送信開始します
- 衝突抑制:CTSに書かれた他のノードに対する送信抑制時間を使う
- データ送信開始前にデータ送信のネゴシエーシ ョンとして RTS/CTS 方式を使った CSMA/CA を CSMA/CA with RTS/CTS とよぶ
P.383 無線LANの動作モード¶
- 無線 LAN の動作モード:図7.3.4参照
- 2 つのモードがある
- インフラストラクチャモード:無線LANノードがアク セスポイントを通じて相互に通信
- アドホックモード:アクセスポイントなしに無線LANノードどうしが直接通信
P.383 COLUMN FDMA,CDMA¶
- 表7.3.1:多元接続する技術グループ
- TDMA とセット
- FDMA
- ある周波数帯をさらに細かい周波数帯に分割
- 接続できる端末数を増やす技術
- CDMA
- 周波数も時間も分割しない
- 符号で各端末の通信を識別・分離
- 接続できる端末数を増やす
P.383 7.3.3 データリンク層の主なプロトコル¶
- 第 2 層
P.384 ARP¶
- ARP(Address Resolution Protocol):通信相手のIPアドレスからMACアドレスを取るためのプロトコル
- ARPの動作
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- ブロードキャスト:ネットワークに参加するすべての機器に同時に信号やデータを送ること
- 各ノードは自分のIPアドレスと比較
- 一致したノードだけARP応答パケットに自分のMACアドレスを入れて返す(ユニキャスト)
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- 参考:GARP(Gratuitous ARP)
- 主な目的:自身に設定するIPアドレスの重複確認・ARPテ ーブルの更新
- 目的IPアドレスに自身が使うIPアドレスを指定し,MACアドレスを問い合わせる
P.384 RARP¶
- Reverse-ARP:逆アドレス解決プロトコル
- MACアドレスからIPアドレスを取る
- 電源オフ時にIPアドレスを保持できない(IPアドレスを保持するハードディスクをもたない)機器が電源オン時に自分のMACアドレスから自身に割り当てられているIPアドレスを知るために使う
- RARP サーバー
- MACアドレスとIPアドレスの対応表を持ったサーバー(RARPサーバー)が必要
P.384 PPP¶
- PPP:Point to Point Protocol
- 2 点間をポイントツーポイントでつなぐためのデータリンクプロトコル
- WANを介して2つのノードをダイヤルアップ接続するときに使う
- ネットワーク層(第3層)とネゴシエーションする NCP(ネットワーク制御プロトコル)とリンクネゴシエーションするLCP(リンク制御プロトコル)からなる
- NCP:Network Control Protocol
- LCP:Link Control Protocol
- リンク制御やエラー処理機能を持つ
P.384 PPPoE¶
- PPPoE:PPP over Ethernet
- PPPと同等な機能をイーサネット(LAN)上で実現するプロトコル
- PPPフレームをイーサネットフレームでカプセル化して実現
P.384 7.3.4 IEEE 802.3規格¶
- メディアアクセス制御に CSMA/CD 方式を使う LAN についての標準
- OSI基本参照モデルにおけるデータリンク層(第 2 層)と物理層(第 1 層)のプロトコルおよびサービスを規定
- OSI 基本参照モデルでのデータリンク層を LLC 副層と MAC 副層の2つに分割
- 物理層での LAN で使う伝送媒体や MAC 副層でのフレーム構成や衝突検出の仕組みを規定
- ツイストケーブルの企画が表 7.3.2 にまとまっている
P.386 7.4 ネットワーク層のプロトコルと技術¶
- もうやった
P.295 定義域(ドメイン)¶
- テーブル全体を $\mathcal{T} = A \times B \times \cdots \times Z$ と書いたときの各 $A,B,\dots,Z$ をドメイン(定義域、domain)と呼ぶ
- 数学の集合と違って $\mathcal{T}$ の中に同じ集合を含まない:つまり $\mathcal{T} = \mathbb{R}^n$ といったテーブルは考えない
- ドメインは「属性が取り得る値の集合」
- RDB では適当なデータ型を対応させる:日付,金額,数量,量
- ドメインを新たなデータ型として定義すると違うデー タ項目でも同じ入力チェックや同じ出力編集ができる
P.296 6.2.2 関係データベースのキー¶
- 表中の行を一意に識別するためのキー(スーパキー,候補キー,主キー)
- 別の表を参照し関連づけるための外部キー
P.296 スーパキー¶
- 表中の行を一意に特定できる属性,あるいは属性の組
- 組について:購入履歴を知るためにはユーザーID・商品ID・購入日がわからないといけない、という程度の意味
- かなり広い意味のようなのでたぶんそんなに使わない
- 補足:なぜスーパ「ー」キーではないのか
- 参考
- JIS の規格がある
- その言葉が 3 音以上の場合には,語尾に長音符号を付けない:ブラウザ、プリンタ、スキャナ、ドライバ、フォルダ、モニタなど
- その言葉が 2 音以下の場合には,語尾に長音符号を付ける: キー、バー、エラーなど
- 参考 2:「サーバー」と「サーバ」、どっちが正解? - 【ビジネス用語】
- 参考
P.296 候補キー¶
- 行を一意に決めるための必要最小限の属性で構成されるスーパーキー
- 一意性制約が必要
- 何かの履歴のように複数のIDの組になることもある
- 外部キーが入るテーブルでよくある
P.296 主キー¶
- 複数存在する候補キーの中から任意に選んだ1つの候補キーを主キー(primary key)
- 主キーに選ばれなかった残りの候補キーを代理キー(alternate key)
- 主キー制約
- 一意性制約
- 実体を保証するため空値(NULL)は許さないという NOT NULL制約
P.296 外部キー¶
- 関連する他の表を参照する属性あるいは属性の組
- 2 つの表の間に「1対多」の関係がある場合
- 「多」側の表に「1」側の表の主キーあるいは主キー以外の候補キーを参照する属性をもたせて外部キーにする
- 参照制約:外部キーの値が外部キーで参照される表に存在することを保証
- 参照制約があると「親テーブル」のカラムを勝手に消せなくなる
- 複数の表を参照するなら表内に複数の外部キーを持つ
- 外部キーの値に NOT NULL 制約がなければ NULL が許される
- 一般に外部キーは被参照表の主キーを参照
- UNIQUE 指 定 さ れ た候補キーを参照する場合もある
- cf. 参照制約:P.320
P.297 COLUMN 代用のキー設定¶
- 主キーが複数の属性から構成される複合キー(連結キー)でその構成属性数が多すぎると運用が面倒
- 連番のような必ずしも積極的な意味がない属性を追加してそれを代用のキー(surrogate key)にする
- 複合キーを構成している属性はすべて非キー属性にして代理キーにする
P.298 6.3 正規化¶
P.298 6.3.1 関数従属¶
- 関数従属:ある属性xの値が決まると他の属性yの値が一意的に決まる関係で、$x \mapsto y$ と書く
- 属性 $x$:独立属性(決定項)
- 属性 $y$:従属属性(従属項)
- 正規化:1 つの表の中の属性間にある関数従属性に着目して整理する
- 整合性を維持しやすいデータベースが設計できる
テーブル1:あるユーザーが何を買ったか - ユーザーID - 商品 ID - 商品名 - 商品の値段 - 購入点数 - 支払金額
→ユーザーのテーブル、商品のテーブル、購入詳細のテーブル
- ユーザーID
- 商品ID
- 購入点数
これがあれば商品名、商品の値段、支払金額がいらない
P.298 部分関数従属¶
- 関係 $x \mapsto y$ で $y$ が $x$ の真部分集合に関数従属するとき、$y$ は $x$ に部分関数従属するという
- どこの業界の用語なのかよくわからない。情報系?
- 部分関数従属は独立属性 $x$ が複数の属性からなるときに起こりうる関数従属
- あまりピンとこない:P.299 に商品マスタ的な例が載っていた
- 本の例:独立属性 $x$ が $x_1$ と $x_2$ の 2 つの属性からなるとき
- ${x_1, x_2} \mapsto y$ が成り立ち、かつ $x_1 \mapsto y$ または $x_2 \mapsto y$ のどちらかが成り立つ
- このとき ${x_1, x_2 }$ と $y$ の間に部分関数従属がある
- 例:社員所属部門テーブル
- 社員番号・部門コード・部門名があるテーブル
- 主キー:社員番号と部門コード
- 部門コードに対して部門名は一意に紐づく
- このとき部門名は主キーに部分関数従属する
P.298 完全関数従属¶
- 完全関数従属:関係 $x \mapsto y$ で $y$ が $x$ のどの真部分集合にも関数従属しない
- 独立属性 $x$ が 1 つの属性かなるときは常に完全関数従属
P.299 推移的関数従属¶
- 直接ではなく間接的に関数従属している関係
- 例:社員マスタ
- 社員番号・社員名・住所・郵便番号からなるテーブル
- 社員番号から住所が一意に紐づく
- 住所から郵便番号が一意に紐づく
- 郵便番号は社員番号に推移的関数従属している
- 念のため:住所は住所マスタなどに外出し(正規化)するべきで、こういうテーブルを作ってはいけない
- 詳しくは次の 6.3.2 で議論される
P.300 6.3.2 正規化の手順¶
P.300 第 1 正規化¶
- 非正規:くり返し部分をもつテーブルのこと
- まずもってくり返しという言葉の理解自体がたぶん面倒
- いろいろな例に触れてみよう
- RDB は平坦な 2 次元の表(テーブル)
- くり返し部分をもつ表から繰り返しを排除してスリム化したい
- 第 1 正規化:くり返しを排除する操作
- 第 1 正規形:第 1 正規化して得られた表のこと
- cf. P.300 図6.3.4 の売上表
- P.300 図 6.3.5
- 売り上げ明細表:主キーの売上番号とくり返し部分を一意に決める商品番号が複合キー
- 別の表に分解する
- 外部キー:他のテーブルの主キーである売上番号を参照している
- 分解・独立させた表に元の表の主キーをもたせる理由:結合で元の表を再現するため
P.301 第1正規形におけるデータ操作での不具合¶
- 第1正規形になった表は RDB 上で定義できる
- データの冗長性のためにデータ操作時に不整合を起こさないように注意が必要:更新時異常の概念
- 種類は以下の通り
- 例は本 P.300 の売り上げ表・売上明細表から
- 第 1 正規形では以下のような更新時異常が起きる可能性がある
- 防止策が第 2 正規化・第 3 正規化
- どこまでどうやるかは状況次第
P.301 修正時異常¶
- 商品名「オレンジ」を「清見オレンジ」に変更したい
- 該当する行をすべて同時に変更しなければならない
- 1行でも変更し忘れるとデータ不整合が起きる
- 先に対策を書いておく
- 売上明細には商品番号だけ持たせて、商品名を削る
- 削った代わりに商品テーブルを作る
- (ふつう商品テーブルには単価も切り出す)
- (単価に消費税を載せるかどうかといった問題もある)
P.301 挿入時異常¶
- 売上明細表の主キーは売上番号と商品番号の複合キ ー
- 売上のない("売上番号"が空値)商品は登録できない
- どうやらこの本の「売上表」は商品テーブルも兼ねているらしい
- 先に対策
- 商品テーブルを別に作って、そこからの参照という形にする
P.301 削除時異常¶
- (先程と同じくこの本の売り上げ表は商品テーブルも兼ねている模様)
- 売上実績が 1 つしかない商品のの売上データを削除す ると商品データも削除される
- 逆に商品データを残そうとすれば売上データは削除できない
- 先に対策:商品テーブルを切り出す
P.301 第2正規化¶
- 第2正規化:すべての非キー属性が各候補キーに完全関数従属である状態にする操作
- 第1正規形の表に対して行われる操作
- 候補キーの一部に部分関数従属する非キー属性を別の表に分解する
- 第2正規化して得られた表を第2正規形という
- 例:図6.3.7の売上明細表
- 候補キーは主キーの{売上番号,商品番号}の1
- 非キー属性である商品名と単価は主キーの一部である商品番号に部分関数従属している
- 商品表として独立させる
- 分解の仕方
- 商品表の主キーを商品番号
- 図6.3.7の上の表を再現できるようにする
- 売上明細表(図6.3.7の下の表)には商品表の主キーを参照する外部キーとして"商品番号"を残す
P.302 メモ¶
- 第2正規化するのは候補キーが複数の属性で構成されている場合。
- 1つの属性で構成されているのであれば部分関数従属は存在しない
- 既に第2正規形
- 非キー属性:どの候補キーにも属さない属性
- 第2正規形:どの非キー属性も候補キーの真部分集合に対して関数従属しない
- どの非キー属性も候補キーに完全関数従属
P.302 第3正規化¶
- 第3正規化:非キー属性間の関数従属をなくしてどの非キー属性も候補キーに直接に関数従属している状態にする
- 第2正規形の表に対して行われる操作
- 候補キーに推移的関数従属している非キー属性を別の表に分解
- 第3正規化して得られた表を第3正規形
- 例:図6.3.8の売上表
- これは第2正規形
- 顧客番号→顧客名いう非キー属性間の関数従属がある
- 顧客番号を主キーとした顧客表として独立させる
- 売上表には顧客表の主キーを参照する外部キーとして顧客番号を残す
P.303 メモ¶
- 第3正規形:どの非キー属性も候補キーに推移的関数従属しない
- どの非キー属性も候補キーに直接に関数従属している
- ボイス・コッド正規形
- 第3正規形では次の関数従属が存在する可能性がある
- 候補キーの真部分集合から他の候補キーの真部分集合への関数従属
- 候補キー以外の属性から候補キーの真部分集合への関数従属
- この関係を分解したのがボイス・コッド正規形
- 第3正規形では次の関数従属が存在する可能性がある
P.303 正規化と非正規化¶
- 正規形には第1正規形から第5正規形まである
- たいていの用途ではデータベースの場合、第3正規形まで正規化されていれば十分といわれている
- 正規化の目的はデータ操作にともなう更新時異常の発生を防ぐこと
- 属性間の関数従属を少なくする
- データの重複を排除する
- 正規化のデメリット
- 表がいくつにも分割される
- 必要なデータを取り出すために表を結合しないといけない
- 処理時間がかかる
- 処理速度が必要な時や更新時異常の発生が低い場合はあえて正規化しない・正規化を解く
- たとえば更新が少ない表は正規化しない
- ここでの「非正規化」:アクセスパターンを考えたうえでどの表を統合するか、どの属性を表間に重複させるか考える
P.304 6.4 関係データベースの演算¶
P.304 6.4.1 集合演算¶
- 関係データベースでの集合演算
- 同じ型の表間での和、共通部分(積)、差
- 直積:同じ型の表でなくてもいい
P.304 和、共通(積)、差¶
- 図6.4.1の表AとBに対するそれぞれの演算結果を見る
- 本参照
P.305 直積演算(Cartesian Product:×)¶
- 社員表と部門表の直積は社員表の各行に対して部門表の行を1つずつつなぎ合わせた表
- 直積の結果として得られる新しい表を直積表と呼ぶ
- 次数(属性の数)は両方の表の次数を足した数
- 位数(タプルの数)は両方の位数を掛けた数
- 直積が役に立つイメージがない:実際には結合 (JOIN) を本当によく使う
P.305 6.4.2 関係演算¶
- 関係演算:関係データベース特有の演算
- 射影,選択,結合,商
- 関係代数:関係演算と集合演算を合わせた代数
- 導出表:これらの演算によって得られた表
P.306 SQL の例¶
- 先に持ってきてみた
SELECT 社員コード, 社員名, 部門表.部門コード, 部門名
FROM 社員表, 部門表
WHERE 社員表.部門コード = 部門表.部門コード
P.305 選択と射影¶
- 選択演算:表から指定した行を取り出す関係演算
- SQL でいう WHERE
- 射影演算:表から指定した列を取り出す関係演算
- SQL でいう SELECT column_name
P.306 結合¶
- 参考:P.306 の下の表
- 結合演算:2つの表が共通にもつ項目(結合列)で結合して新しい表をつくり出す関係演算
- まさに正規化でわけたテーブルを結合させる演算
- SQL:SELECT文のFROM句で複数の表名をカンマで区切って指定
- WHERE句で結合条件を指定
- 結合条件
- 結合列の値を>,≧,=,≠,≦,<のいずれかの比較演算子で比較して結びつける
- 等結合:比較演算子が「=(等号)」である結合
- 2つの表から作成される直積表から結合列の値が等 しいものだけを取り出す
- 得られた新たな表には結合列が重複して含まれる
- SELECT句でどちらか一方の結合列を指定して見かけ上の重複を除く
- 自然結合(natural join):重複する結合列を取り除く(一方のみ残す)ようにした結合
- 結合列の列名が2つの表で同じ場合に使える
- 参考
- (意識的に使ったことがない)
P.307 内結合と外結合¶
- 参考:P.307 の図 6.4.8
- 内結合(INNER JOIN)
- 結合列の値が等しい行だけを取り出す結合演算
- 片方の表にしか存在しない行は取り出せない
- データベース言語仕様(JIS X 3005)
- 外結合(OUTER JOIN)
- 片方の表にしか存在しない行も取り出せる結合
- 結合相手の表に該当するデータが存在しない場合はNULL(空)値で結合
- 左外結合・右外結合・完全外結合
- 等結合
- 結合する表をFROM句で指定、結合条件はWHERE句 で指定
- 内結合・外結合
- 結合する表をFROM句の中でJOINを使って指定
- 結合条件は JOIN に続くON句で指定する
- 参考:p309のコラム「内結合と外結合のSQL文」
P.307 左外結合(LEFT OUTER JOIN)¶
- 参考:P307 図 6.4.9、P309 の SQL 文
- 結合する左の表(社員表)が基準
- 右の表(部門表)に存在しない行を空値(NULL)として結合
P.308 右外結合(RIGHT OUTER JOIN)¶
- 参考:P.308 図 6.4.10
- 結合する右の表(部門表)が基準
- 左の表(社員表)に存在しない行をNULLとして結合
P.308 完全外結合(FULL OUTER JOIN)¶
- 参考:P.308 図 6.4.11
- 片方だけに存在する場合もう片方をNULLとして結合
P.308 商¶
- (これ何だろうか?where の
in?)- 普通に
inまたは =`= でよさそう? selectも含んでいる?
- 普通に
- 参考:P.308 図 6.4.12
- 関係R(X,Y1,Y2)とS(Y3,Y4)がある
- S(Y3,Y4)のすべての行がR(Y1,Y2)に含まれる場合に対応するR(X)を求める演算
- 商(R÷S)は関係Rの中から関係Sのすべての行を含む行を取り出し、そこから関係Sの項目を除く
- 重複行も除く
- 参考:P.309、図6.4.13
- 社員表から東京に住み営業2課(E02)に勤務する社員を探す場合に商演算を使う
P.309 COLUMN ない結合と外結合の SQL¶
- 本を読もう
P.310 6.5 SQL¶
P. 310 6.5.1 データベース言語SQLとは¶
- SQL(Structured Query Language)
- RDB の標準的な操作言語
- ほとんどの RDBMS が SQL を使っている
- Relational DataBase Management System
P.310 SQLの分類¶
- RDB のデータを検索(参照)、操作
- データ定義
- トランザクション制御
- 参照:表 6.5.1 に SQL 文が書いてある
P.310 表 6.5.1 重要な SQL¶
- DDL (Data Definition Language)
- CREATE, DROP, GRANT, REVOKE
- DML (Data Manipulate Language)
- SELECT, INSERT, UPDATE, DELETE, COMMIT, ROLLBACK, DECLARE CURSOR, OPEN, FETCH, CLOSE
- DECLARE CURSOR以降は親言語方式などで使用されるSQL
- 親言語方式
- CやCOBOLなどのプログラム中にSQL文を組み込んでデータベースにアクセスする方式。
- 埋込みSQL:p328参照
P.311 6.5.2 SELECT文¶
- データ操作言語(DML)
- 問合せ(SELECT)文
- 挿入(INSERT)文
- 更新(UPDATE)文
- 削除(DELETE)文
- などなど
- SELECT文以外のDMLは「6.5.3 その他のDML文」(p319)参照
P.311 SELECT文の構文¶
- SELECT文の基本構文
- [ ]内は省略可能
SELECT
[DISTINCT]
列名のリスト
FROM 表名のリスト
[WHERE 選択条件や結合条件]
[GROUP BY 列名のリスト]
[HAVING グループ選択条件]
[ORDER BY 列名のリスト]
- リスト:列名および表名をカンマ(,)で区切って列挙したもの。
P.311 行、列の取り出し¶
- 選択:WHERE句に選択条件を指定すると特定の行を取り出せる
inとリストを使うと複数行に対する- 具体例を考えないと使い分けや気分はわからなそう
- 射影:SELECT句に列名を指定すると特定の列を取り出せる
- SELECT句への
*:全部の列を取りだす - 選択条件と論理演算子(AND・OR・NOT):複数の条件を組み合わせる
- 表 6.5.2:選択条件に使う比較演算子の表
- 参考:列の値が「空値(NULL)であるか」という検索条件
WHERE 列 IS NULLWHERE 列 = NULLではない- NULL は他にもいろいろ邪悪な面がある
- 空文字列などとは違う概念でよくはまる
SQL 例¶
- P.312、図 6.5.1
- 社員表から年齢が24以上28以下の社員コード・社員名を表示するサンプル
SELECT 社員コード, 社員名 FROM 社員表 WHERE 年齢 >= 24 AND 年齢 <= 28
P.312 BETWEEN述語¶
- 先のSELECT文はBETWEEN述語やIN述語を使って同じ内容を表せる
- BETWEEN述語は「値1~値2」の範囲(値1,値2を含む)に列の値が含まれるかを選択条件にする
SELECT 社員コード, 社員名 FROM 社員表 WHERE 年齢 BETWEEN 24 AND 28
P.312 IN述語¶
- IN述語は列の値が指定された値のいずれかと等しいかを選ぶ条件にする場合に使う
- INの前にNOTをつけると指定された値のいずれでもないという選択条件になる
- IN述語の使用例については副問合せ(p317)も参照
P.313 重複行の排除¶
- 取り出された行の中から重複するものを除きたい場合
- SELECT句の列名指定にDISTINCT述語を使う
P.314 出力順の指定¶
- ORDER BY 句:特定の列の値で昇順・降順に並べ替えて表示する
- ORDER BY のあとに続けて並べ替えのキー(列名)を指定
- 降順の場合はDESC、昇順の場合はASC
- ふつう ASC がデフォルトで省略できる
SELECT 社員名, 年齢 FROM 社員表 ORDER BY 年齢 DESC
P.314 グループ化¶
- GROUP BY 句:取り出した行を指定した列の値でグループ化
- グループごとの合計や最大値などを求める
- HAVING 句:条件に合ったグループだけを取り出す
SELECT 所属, COUNT(), AVG(年齢) FROM 社員表 GROUP BY 所属 HAVING COUNT() >= 2
- SQL の簡単な解説
- 社員表のデータをGROUP BY句を使って所属でグループ化
- HAVING 句で「グループに所属する人数が2人以上」のグループだけを取り出す
- 取り出したグループごとにその所属・人数・平均年齢を求める
P.315 表の結合¶
- 2 つの結合
SELECT A FROM B WHEREによる等結合FROM句の中でのJOIN ... ONによる内結合や外結合
- どちらであっても結合表には結合条件で指定した結合列が重複して含まれる
- 列名を指定するときは「表名.列名」という形式で表す
P.316 表に別名をつける¶
- FROM句で「表名 AS 別名」あるいは「表名 別名」と指定すると表名に対して別名(相関名)を設定できる
- 自己結合:表に別名を与えると同じ表どうしを結合できる
- 自己結合については P.317 の例を参照
- 上司コードを使ってある社員とその上司の氏名や関連情報を見たい場合に使う
P.317 副問い合わせ¶
- サブクエリともいう
- SELECT文のFROM句やWHERE句・HAVING句などに指定されている入れ子になったSELECT文
SELECT 社員コード, 社員名, 年齢 FROM 社員表 WHERE 年齢 IN (SELECT 指定年齢 FROM 調査対象)
- サブクエリにはいろいろ面倒な話がある
- 参考:MySQL のサブクエリって、ほんとに遅いの?
- これは 2017 年の記事:この辺はお金になるので割と日進月歩で、3 年程度の昔の情報でも既に参考にならないことも多い。
- 簡単なまとめ
- 遅いのは2番目、DEPENDENT SUBQUERYである
- MySQL 5.5 までサブクエリはやっぱり遅い
- MySQL 5.6 からはそんなに遅くなくなった
- MySQL とはいってもバージョンによって全然違う:オプティマイザは進化している
- 現状についてはきちんと最新の話を追う、または自分が必要なケースについて実測する
P.318 EXISTS述語¶
- サブクエリはEXISTS述語でも表せる
- 参照:P.318 の例
- EXISTS は相関副問合せが何らかの結果を返した場合にTRUE(真),何も返さなかった場合にFALSE(偽)を返す
- 主問合せの結果1行に対して相関副問合せから何らかの結果が戻されれば、主問合せの選択条件は成り立ち、何も返されなければ選択条件は成り立たない
- EXISTS 述語でほかの表にも存在するものを調べられる
- ANY でも同じ操作を表せる
- 参考:P.318 の例
- 副問合せの結果のいずれか(ANY)と等しい
- どれがいいかは最終的にはテーブルの実装や使っている RDBMS とバージョンに依存する
- 実測してチューニングしよう
P.319 6.5.3 その他の DML 文¶
P.319 INSERT文¶
- 表に行を挿入する:2つ方法がある
- 参考:本の P.319
- 挿入する値をVALUES句で指定する
- 問合せの結果をすべて挿入する
- (DBMS によるかもしれないが)個別INSERTと一括INSERTもある:パフォーマンスでよく問題になる
- 一部の列に対して INSERT
- どの列に対して挿入するのか列名リストで指定
- 省略された列の値はDEFAULT制約があればその既定値、そうでなければNULL値
- NULL はなるべく使うのをやめよう
- DEFAULT は P.322 表 6.6.1
P.319 UPDATE文¶
- 表中のデータを変更
- 列の変更値を直接指定する
- 変更値をCASE式で決める
- 副問合せの結果を変更値にする
- SET句には変更したい列の値を「列名 = 変更値」の形で指定
- 1 つのUPDATE文で複数の列の値を変えるときはカンマ(,)で区切って指定
- WHERE句を省略すると表中のすべての行が変わる
- ふつうはやらない
- WHERE句を指定すれば条件に合った行だけ変わる
P.320 DELETE文¶
- 表中の行を削除する
- 表中の全行を削除しても表自体は残る
- 表を削除するのはDROP文
- WHERE句を省略すると表中のすべての行が削除される
- WHERE句を指定するとその条件に一致した行だけを削除できる
P.320 参照関係をもつ表の更新¶
- 関連する2つの表の間に参照制約が設定できる
- 被参照表の主キー(候補キー)にない値を参照表の外部キーに追加できない
- 被参照表の行の削除・変更時に制約が出る:図6.5.10参照
- 参照動作指定:削除・変更時の制約は明示的に指定できる
- 次節のCREATE TABLE文を参照
- REFERENCES句(参照指定)の後に次の構文で指定
参照動作指定 REFERENCES 被参照表(参照する列リスト) ON DELETE 参照動作] [ON UPDATE 参照動作] (*[ ]内は省略可能)
- 指摘できる参照動作:表 6.5.5 の 5つ
- デフォルトは NO ACTION
P.320 補足¶
- 参照制約
- 外部キーの値が被参照表の主キーあるいは主キー以外の候補キーに存在することを保証する制約。
- 関連する2つの表の間に参照制約を設定する目的:データ矛盾を起こすような行の追加や削除・変更を排除するため
- REFERENCES指定:p322-324を参照
- データの整合性を保つための制約
- 一意性制約
- 参照制約
- データ項目のデータ型や桁数に関する形式制約
- データ項目が取り得る値の範囲に関するドメイン制約がある。
P.322 6.6 データ定義言語(DDL)¶
P.322 6.6.1 実表の定義¶
P.322 CREATE TABLE文¶
- 表の定義はには CREATE TABLE 文
- 基本構文は P.322 参照
P.322 列制約¶
- 表を構成する列に対する制約
- 参考:表6.6.1
- 一意性制約:同一表内に同じ値が複数存在しないことを保証する制約
- 主キーとなる列には一意性制約にとNOT NULL制約を加えたPRIMARY KEY指定
- 主キー以外の候補キーにも一意性制約がある
- 一般にNULL(ナル)値は重複値とは扱われない
- 候補キーにはNULL値を許すUNIQUE指定
- 参照制約:外部キーの値が被参照表に存在することを保証する制約
- 外部キー:REFERENCES指定(参照指定)す。
P.323 表制約¶
- 一意性制約・参照制約・検査制約は表制約(表定義の要素として定義される制約)にもできる
- 列制約:1つの列に対する制約
- 主キーや外部キーが複数列から構成される場合、これを列制約として定義できない
- このときは表制約を使う
P.323 主なデータ型¶
- 一般的な文字型,数値型は覚えておくといい
P.324 実表の定義例¶
- P.324 の社員表と部門表を定義を見てみよう
P.325 6.6.2 ビューの定義¶
P.325 ビューとは¶
- 実表:ディスク装置上にあり実際にデータが格納される表
- ビュー:実表の一部または複数の表から必要な行や属性(列)を取り出してあたかも1つの表 であるかのように見せかけた仮想表
- 利用者から見れば実表と同じ
- データを検索するだけなら制約はあっても同じように操作できる
- ビューのメリット
- あくまでも仮想の表:対象となった元の表(基底表)の列名と別の名前で定義できる
- ビューに定義することで情報を公開
- ビューに定義しないことで情報を非公開にできる
- 元の表に新たな列が追加されても既存のビューには影響がなく再定義する必要がない
- ビューは仮想的な表
- 一般には実体化されずデータ格納領域をとら ない。
- 実表のように実体化されるビューもある:体現ビュー(materialized view)
P.325 CREATE VIEW文¶
- ビューの定義:CREATE VIEW文による:詳細は本の P.325
- ビュー:対象となる実表(あるいは他のビュー)からSELECT文で必要データを導出する方法で定義される定義するビューの列名に命名規則はない
- 列数はAS句に続くSELECTで問い合わせた結果の列数と同じでなければならない
- 列名は省略可能:省略した場合はSELECTで問い合わせた結果の列名がそのまま定義される
- ビューに対する参照や更新処理
- ビューの対象となった表(基底表)に対す る参照あるいは更新処理に変換されて実行される
P.326 ビューの定義例¶
- 本の P.326 参照
- 社員表と部門表から社員コードと社員名、その社員が所属する部門名からなる表をビュー「社員表2」
- JOIN して必要なカラムだけ取り出す
P.326 ビューの更新¶
- ビューへの更新処理 ビュー定義を基にビューが参照している表(基底表)への対応する処理に変換されて実行
- 更新のための条件
- 更新にかかる実際の表が更新可能
- 更新される表の列や行が一意に決まる
- 更新できないビューの例
- SELECT句で式、集合関数、DISTINCT を使ったSELECT文で定義されている
- ・GROUP BY句やHAVING句を使ったSELECT文で定義されている
P.327 6.6.3 オブジェクト(表)の処理権限¶
- スキーマに定義された実表やビューはそのスキーマ所有者(作成者)にしか処理権限が与えられない
- 複数の利用者がデータベースを利用できるようにしたければ、スキーマ所有者以外にも処理権限を付与する必要がある
- データベース管理ユーザーは全権を持っていて危険な処理もできてしまう
- できることを制限したユーザーで操作したい
- オブジェクト(表)の処理権限
- 読取(SELECT)権限
- 削除(DELETE)権限
- 挿入(INSERT)権限
- 更新(UPDATE)権限
- cf. スキーマ
- 1つのデータベースの枠組み
- スキーマ内に複数の表やビューを定義できる
P.327 処理権限の付与¶
- 権限の付与:GRANT文による
- GRANTの基本構文は次の通り
1 | |
- 権限指定
- 4 つの処理権限(SELECT,INSERT,UPDATE,DELETE)
- ALL PRIVILEGES(すべて)を指定できる
- 権限を複数付与する場合はカンマ(,)で区切って指定
P.327 処理権限の取消し(変更)¶
- 一度付与された権限を取消し(変更)できる
- 権限の取消しはREVOKE文
- REVOKEの基本構文
1 | |
P.328 6.7 埋込み方式¶
P.328 6.7.1 埋込みSQLの基本事項¶
P.328 静的SQLと動的SQL¶
- 静的 SQL:あらかじめ決められたSQL文をプログラム中に埋込んで実行する方式
- 実際のアプリケーションではあまり見かけない
- 非カーソル処理:データベースの表から1行を取り出すこと
- 次のような SELECT 文
- この
INTOを見たことがない
SELECT 社員名, 年齢 INTO :name, :age FROM 社員表 WHERE 社員コード = '100';
- 動的 SQL:実行する SQL 文がプログラム実行中でな ければ決まらない場合に SQL 文を動的に作成し実行する方式
- 上の社員コードがふつう変わる:それが「動的」。
- この動的な部分に変なコードを埋め込むとまずいというのがセキュリティ問題で、例えば SQL インジェクションの問題。
P.328 ホスト変数¶
- ホスト変数:データベースとプログラムのインタフェースとなる変数
- 埋め込み SQL では SQL を実行すると取り出されたデータをINTO句で指定したホスト変数に格納する
- ホスト変数は通常の変数としてもアクセスできる
- 出力関数で表示
- 入力関数で値を入力してそれをSELECT文の条件としても使える
P.329 6.7.2 カーソル処理とFETCH¶
P.329 カーソル処理¶
- 「SELECT・・・・INTO・・・」形式では,1行のデータしか取り出せない
- (見たことがないのでイメージがつかない)
- 検索結果が複数行の場合は1行ずつ取り出せるカーソル処理を使う
- カーソル処理は SQL 文で問い合わせた結果をあたかも1つのファイルであるかのようにとらえる
- FETCH文でそこから1行ずつ取り出す方式
- 1つのSELECT文に対してカーソルを宣言(定義)
- カーソルのオープンでSELECT文が実行
- カーソルで1行ずつ取り出せる
- FETCH文で繰返し行を取り出して処理
- 終了したらカーソルを閉じる
P.330 FETCHで取り出した行の更新¶
- 参考:図 6.7.2:FETCHで取り出した行の更新処理
- FETCH文で取り出した行を更新あるいは削除する場合,FETCH文のあとに続くUPDATE文やDELETE文のWHERE句 に「WHERE CURRENT OF カーソル名」と指定する。
- (FETCH 文を見たことがないのでイメージつかない)
P.330 処理の確定と取消し¶
- 一連のデータを更新している途中でエラーが出た場合
- それまでの更新処理を取り消して元に戻す必要がある
- 整合性を取らないといけない:いわゆるロールバックが必要
- トランザクションが正常終了したときは「コミット」する:更新処理の確定
P.331 6.8 データベース管理システム¶
P.331 6.8.1 トランザクション管理¶
P.331 トランザクションとは¶
- 複数の利用者が同時にデータベースにアクセスしてもデータが矛盾してはいけない
- この仕組みがトランザクション管理
- トランザクション:データの整合性を取るための SQL 処理の最小単位
- 「回復の単位(Unit of Re-covery)」とも呼ぶ
P.331 ACID 特性¶
- トランザクション処理は原子性・一貫性・隔離性・耐久性の 4 特性が必要
- 厳密な一貫性(完全一貫性)が必要
- トランザクションではそのすべての処理が完了するか(All)、あるいはまったく実行されていない状態か(Nothing)のどちらか一方で終了しなければならない
- これは,COMMIT(正常終了),、ROLLBACK(異常終了)で実現できる
- COMMIT(コミット):更新処理を確定し、データベ ースへの反映を保証する
- ROLLBACK(ロールバック):更新処理をすべて取 消し,トランザクション開始時点の状態へ戻す
- 参考:結果整合性
- 完全一貫性に対する概念
- 分散トランザクションやいわゆる NoSQL で使われる
- 参考:分散トランザクション
- トランザクション管理するべきテーブルが複数のデータベースにまたがっているとき
- すべてのデータベースをロールバックしなければいけない
P.331 表 6.8.1 ACID 特性¶
- 原子性(Atomicity)
- 更新処理トランザクションが正常終了した場合だけデータベースへの反映を保証する
- 異常終了時は処理が何もなかった状態に戻す
- 一貫性(Consistency)
- トランザクションの処理によってデータベース内のデ ータに矛盾が生じないこと
- 常に整合性のある状態が保たれていること
- 隔離性(Isolation)
- 複数のトランザクションを同時(並行)に実行した場合 と,順(直列)に実行した場合の処理結果が一致するこ と
- 独立性ともいう
- トランザクションのスケーリング:複数のトランザクションを同時実行してもそれが正しい順で実行されるように順序づけること
- 基本は並行実行の結果と直列実行の結果が等しくなるように調整する
- ロック:直列可能性を保証する方法
- 耐久性(Durability)
- いったん正常終了したトランザクションの結果はそ の後に障害が発生してもデータベースから消失しないこと
- トランザクションの再実行を必要としないこと
P.332 6.8.2 同時実行制御¶
2020-12-20 課題¶
- 先に進む前に録画してあるか確認しよう
進捗¶
- 前回の進捗
- 基礎知識編:6.3.2 正規化の手順まで
- 本編:「04-01 以下、高校数学水準で」
- 今回の進捗
- 基礎知識編:P.319 6.5.3 その他の DML 文
- 本編:「期待値をコードで表す」まで
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 勉強の日常組み込み系
- Julia:The Little Book of Julia Algorithmsを読んでみることにしました。適当に話します。
- そのうち取り組む事案:黒木さんの Julia での統計ネタ
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
TODO¶
- AWS のハンズオン
- 公式のハンズオン: 無料でできるハンズオンもたくさんある
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- 実際に競プロの問題をいくつか解いてみましょう。
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
TeX の記録¶
- TODO
\begin{align} a \end{align}
日々の勉強¶
Julia¶
- The Little Book of Julia Algorithms
- リポジトリの対象ディレクトリ:ここ
- その他参考
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- ネットワークの話もいい加減飽きたので、しばらく DB の話
復習¶
- 3 つのスキーマ
- ユーザーが見るレベル
- 正規化などをかけておいたデータベースにもっていけるレベル
- 個々のデータベースに合わせた具体的なレベル
- インメモリの DB:コンピューターの基本的なハードウェア構成と意味を復習しよう
本の記述を追いかける¶
P.408 7.8 交換方式¶
P.408 パケット交換方式¶
- 回線交換方式と対になる概念
- 回線交換方式:通信を行うノード間で物理的な通信路を確保してから通信する
- 例:電話
- パケット交換方式について
- データ送信するノードはデータをパケットに区切る。
- ひとつひとつのパケットにヘッダを付けて送信。
- ネットワーク内ではパケット交換機にパケットがたまる
- ネットワークの状況に応じて順次送られる
パケット通信のメリット・デメリット¶
メリット¶
耐障害性 - 通信路を固定しないため,迂回経路が取れる。 - パケット交換機にデータが蓄積されているため,復旧まで待てる。 - パケット多重 - 1 対 1 の通信で回線を占有する必要がないため,1つの回線を多くのノードで共有でき,回線を効率的につかえる - 異機種間接続性 - パケット交換機で中継するときにプロトコル変換・速度変換でエンドノードどうしが同じプロトコルをサポートしていなくても通信できる
デメリット¶
- ネットワーク内の蓄積交換処理による遅延
- 蓄積交換処理による遅延解消のために主に回線の帯域を広げることで対応してきた
- 構造上,完全には遅延をなくせない
- パケット到着順序の不整合
P.408 ATM 交換方式¶
- ATM(Asynchronous Transfer Mode:非同期転送モード)
- 遅延のない回線交換方式とパケット交換方式の利点を得たい
- パケット交換方式の発展
- 遅延の原因をつぶす:特にパケットの多様性
- 多種多様なパケットに対応するために,パケット交換機はソフトウェア処理が必要 ^ ATM での工夫の一例:最も特徴的なのは,パケット(ATMではセルという)の長さをヘッダ部 5 バイト,ペイロード 48 バイトの53バイトに統一
- パケット解析がハードウェアだけでできる。
- ソフトウェアは不要になった。
- Wikipedia から
- 当初の意図に反して非常に複雑な技術になってしまった
- ATM は次世代の主流にならず限定的な使用にとどまった
- ATM の設計思想は MPLS へと引き継がれた
- 汎用のレイヤ 2 のパケットスイッチングのプロトコルとして、ルーターを介したIPの通信網で利用されている。
P.408 ペイロード(payload)¶
- データ通信で本来転送したいデータ本体の部分、ボディを指す。
- ATM ではペイロードのサイズを固定して処理を簡素化
- 難点:パケット全体に占めるペイロードのサイズが相対的に小さくオーバヘッドが大きい
P.410 輻輳¶
- フレームリレー:パケット交換方式の一種
- 1 つの回線を多数のユーザで共有。
- 回線がもつ潜在的な伝送能力(ワイヤスピード)を十分に引き出すうえで効果がある
- 輻輳:ユーザの利用が一時期に集中すると,ワイヤスピードを超えるパケットがネットワーク上に流れる
- ネットワークが輻輳状態になるとスループットが落ちる
- フレームリレーサービスを提供する事業者は,ネットワークが輻輳状態に陥ってスループットが低下しても最低限保証する通信速度を決めている
- CIR(Committed Information Rate:認定情 報速度)
P.370 7 ネットワーク¶
- 確か 7.4 から始めた気がするので 7 章はじめから
P.370 7.1.1 OSI基本参照モデル¶
- 改めて復習
- OSI(Open System Interconnection)基本参照モデル- 異なる設計思想・世代のシステムと円滑に通信するのが目的に標準化
- プロトコルの単機能化,交換の容易さが目的
- 階層化のおかげで一部の階層の技術体系が変わっても、その階層だけ取り替えればいい
- コスト・リスクを小さくする
P.370 プロトコルとサービス¶
- N 層:それぞれの階層のこと
- エンティティ:N 層に存在する通信機器などの実体
- この言葉はいろいろなところで出てきていろいろな意味で使われる
- もちろん気分的には適当な実体を指すことが多い
- プロトコル:N 層に属するエンティティが通信するための取り決め
- 上位の層が下位の層を利用しながら通信する
- 別の階層間のエンティティどうしが通信する窓口が必要
- これを提供するのが下位層:この機能をサービスと呼ぶ
- プロトコルに沿った仕様で製品を開発すれば別のベンダの機器でも通信できる
- 参考:ベンダーロックイン
特定ベンダー(メーカー)の独自技術に大きく依存した製品、サービス、システム等を採用した際に、他ベンダーの提供する同種の製品、サービス、システム等への乗り換えが困難になる現象のこと。
出来上がった情報システムの正確な仕様が、システムを開発・構築したベンダーにしか解らなくなる場合がある。結果、システムの保守・拡張・改修等の際、現存システムを開発・構築したベンダーに引き続き発注せざるを得なくなる。
- 「Excel で行政に提出する書類を作れ」事案もそれ。
- Apple 製品で身の回りを固めるのも同じ。
- 「多様性が大事」事案でもある。
7.1.2 TCP/IPプロトコルスイート¶
- プロトコル同士には相性がある
- 「ネットワーク層がこのプロトコルならトランスポート層はこのプロトコルにしておくとトラブルが少ない」
- 一般に同じ団体が作ったプロトコルはセットで使われることが多い
- このセットがプロトコルスイート ^ 最も代表的なのは IP を中心に組まれた TCP/IP プロトコルスイート
- 独自の階層モデルをもつ
P.372 TCP/IPの通信¶
- データをパケットに区切る
- 各パケットにヘッダを付けて送信
- ヘッダは各階層ごとに付加されて次の階層へと渡される
- 各ヘッダにはその階層で必要となる送信元や送信先,大きさ,順番などパケット自体に関する情報を含む
- TCPヘッダを付加したパケット:TCP セグメント
- IP ヘッダを付加したパケット:IP パケット
- MACヘッダを付加したパケット:MAC フレームあるいはイーサネットフレーム
P.372 MAC(Media Access Control)アドレス¶
- イーサネットや FDDI で使用される物理アドレス
- イーサネット (Ethernet):コンピューターネットワークの規格の1つ。オフィスや家庭で一般的に使用されている有線LAN (Local Area Network) の技術規格
- FDDI:LAN でデータ転送を行うための標準の一つ
- Fiber distributed data interface
- データリンク層
- 同じネットワークに接続された隣接ノード間の通信で相手を識別するために使う
- MACアドレスの長さ:6バイト
- 先頭24ビットの OUI(ベンダID)
- 後続24ビットの固有製造番号(製品に割り当てた番号)
- MAC アドレスは機器が固有にもつ番号
- 必ず一意に定まるように IEEE が管理
P372 ポート番号¶
- トランスポート層にでノード内のアプリケーションの識別に使う識別子番号
- 0-65535の範囲
- TCP/IPではパケット交換方式でデータをやり取りする
- よく使われるアプリケーションについてのポート番号は Well-Known ポートとして標準化
- TCP・UDPそれぞれで 0-1023 番までの番号を割り当てている
- SSH:TCP22番
- Telnet:TCP23番
- SMTP:TCP25番
- HTTP:TCP80番
- POP3:TCP110番
- IMAP4:TCP143番
- HTTPS :TCP443番
- NTP:UDP123番
- SNMP:UDP161番
- SNMP Trap :UDP162番
- セキュリティ対策のために標準とはポート番号を変えることもある
- Web 開発の本を読んでいると、いろいろな都合から http のポートを 80 以外にしていることもよくある。
- 80 の場合はポートを指定しなくてもいい
- 例:http://localhost/hoge/fuga
- 例:http://localhost:5000/hoge/fuga
- 80 の場合はポートを指定しなくてもいい
P.373 ネットワーク間の通信¶
- 同じネットワークに接続されたノード間はデータリンク層(第 2 層)の通信
- ネットワークを超えたノード間はネットワーク層(第 3 層)の通信 -実際に図 7.1.4 を見よう
- どこが IP アドレスでのやりとりか?
- どこが MAC アドレスでのやり取りか?
P.374 7.2 ネットワーク接続装置と関連技術¶
P.374 7.2.1 物理層の接続¶
P.374 リピータ¶
- ネットワーク上を流れる電流の増幅装置・整流装置
- 物理層:第 1 層
- データ通信はネットワーク上を流れる電流
- ケーブルが長いと電流が減衰・波形が乱れが起きる
- データが読み取れなくなる
- これを増幅するのがリピータ
- 大昔の電話は距離が遠いと音が小さく聞こえにくかった
- まさにこの減衰が問題
- リピータは 1:1 で繋ぐ
- 現在では複数のノードを接続できるマルチポートリピータ(ハブ)が使われるのが一般的
P.374 7.2.2 データリンク層の接続¶
- 第2層
P374 ブリッジ¶
- データリンク層に位置
- ネットワーク上を流れているフレーム(情報の単位)の MAC アドレスを認識して通信を中継する
- 接続されているノードをコリジョンドメイン(セグメント)という単位に分割
- MAC アドレスで判定したフレームのあて先のあるセグメントだけにフレームを送信
- 無駄なトラフィックの回避
- ポートの記憶
- 通信のたびにある MAC アドレスをもつノードがどのポート に接続されているか学習
- 次回の通信時には余分なポートには通信を中継しない。
- ブリッジの動作
- あて先MACアドレスをもとにMACアドレステーブルを参照する
- あて先MACアドレスの接続ポートがフレームを受信したポー トと別ポートであれば,そのポートにフレームを送信し
- 同一ポートであればフレームを破棄する
- あて先MACアドレスが記憶されていない場合やブロードキャス トアドレス(FF-FF-FF-FF-FF-FF)の場合は,受信ポート以外のすべてのポートにフレームを送信する
P.375 スイッチングハブ¶
- レイヤ2スイッチ(L2スイッチ)とも呼ばれる
- データリンク層に位置
- ブリッジと同じ働きをする
- MAC アドレスを認識してフレームのあて先を決めて通信を行います。
- 試験での問われ方
- スイッチングハブはフレームの蓄積機能、速度変換機能や交換機 能をもっている。
- このようなスイッチングハブと同等の機能をもち,同じプロトコル階層で動作する装置はどれか
- 答えは「ブリッジ」
P.375 ブロードキャストストリーム¶
- データリンク層で動作するブリッジやスイッチングハブなどの LANスイッチはブロードキャストフレームを受信ポート以外 のすべてのポートに転送
- これらの機器をループ状に接続し冗長化させると信頼性はあがる
- ブロードキャストフレームは永遠に回り続けながら増える
- 最終的にはネットワークダウンを招く
- この現象をブロードキャストストームという
- ブロードキャストストームを防ぐプロトコル:スパニングツリープロトコル(Spanning Tree Protocol:STP)
- ループを構成している一部のポートを通常運用時にはブロック(論理的に切断)する
- ネットワーク全体をループをもたない論理的なツリー構造にする
P.376 ネットワーク層の接続¶
- 第 3 層(レイヤ 3)
P.376 ルータ¶
- ルータはネットワーク層(第 3 層)に位置する
- あて先IPアドレスを見てパケットの送り先を決め通信を制御する
- IP のローカルネットワークの境界線に設置して利用され,ネットワークの基本単位として機能
- 世界中に散在しているローカルネットワークどうしをルータが結ぶ
- 全体としてインターネットというインフラが機能
- ルータで分けられたネットワークの単位をブロードキャストドメインという
- ルータがパケットを受け取ったあと
- あて先IPアドレスを見る
- 自分のネットワークあてであれば,破棄
- 他のネットワークあてであれば転送
- どのルータへ送ればあて先のネットワークへの通信が速く行えるかを判断することを経路制御(ルーティング)
- ルータはそのための経路表(ルーティングテーブル)を備えている
P.376 デフォルトゲートウェイ¶
- 会社Aのネットワークに属するPCは会社BのPCと直接通信できない
- 会社AのPCは他ネットワークへの接点であるルータAに転送を依頼
- デフォルトゲートウェイ:会社AのPCから見て直近のルータA
- 自分と直接接続していない相手と通信するときはすべてデフォルト ゲートウェイを中継する
P.376 ルーティング¶
- 経路表(ルーティングテーブル)の作成方法
- 手作業で作る:スタティックルーティング
- ルーティングプロトコル利用:ルータ同士が経路情報を交換し、自立的に経路表を作るダイナミックルーティング
- ダイナミックルーティングのための代表的なルーティングプロトコル:RIP、OSPF
- RIP:ディスタンスベクタ型(距離ベクトル型)
- ルーティングテーブルの情報(経路情報)を一定時間間隔で交換しあう
- あて先ネットワークにいたるまでに経由するルータの数(ホップ数)最小経路を選ぶ
- あて先に到達可能な最大ホップ数は 15
- これを超えた経路は採用されない
- OSPF:リンクステート型
- コストを経路選択の要素に取り入れ、コスト最小経路を選ぶ
- コスト値は,回線速度を基に自動的に算出されるが手動設定もできる
- コスト算出式「コスト=100Mbps/経路の通信帯域(bps)」
- コスト計算例は P.377 の図を見ること
P.377 ルータの冗長構成¶
- ルータを冗長構成のために使うプロトコル:VRRP(Virtual Router Redundancy Protocol )
- 同じ LAN に接続された複数のルータを仮想的に 1 台のルータ として見えるようにして冗長構成を実現する
- 複数のルータでグループ(VRRP グループ)を作る
- VRRP グループごとに仮想 IP アドレスと仮想 MAC アドレスを割り当て
- PC などのノードは仮想ルータの IP アドレスに対して通信
- 通常時はグループのマスタルータが仮想ルータの IP アドレス(仮想 IP アドレス)を保持
- マスタルータに障害が発生すると他のバックアップルータがこれを継承
P.377 レイヤ3スイッチ(L3スイッチ)¶
- ルータと同じネットワーク層(第 3 層)の通信機器
- 特徴
- ルータ:ソフトウェアで転送処理
- レイヤ 3 スイッチ:専用ハードウェアで転送処理
- 高速処理できる:大容量のファイルを扱うファイルサーバへのアクセスなど
P.378 トランスポート層以上の層の接続¶
P.378 ゲートウェイ¶
- トランスポート層(第 4 層)-アプリケーション層(第7層)でネットワーク接続するための装置
- 第 3 層のネットワーク層まででエンドツーエンド(E2E)の通信は完成する
- E2E = 通信を行う二者、あるいは、二者間を結ぶ経路全体
- エンドツーエンド原理:高度な通信制御や複雑な機能は末端のシステムが担い、経路上のシステムは単純に信号やデータの中継・転送だけすべし
- TCP/IP ネットワークの原理
- 誤り訂正・フロー制御・再送:TCP 層(第4層、トランスポート層)など上位側の機器やソフトウェア・プロトコル
- 単純な送受信・転送処理:IP 層(第3層、ネットワーク層)
- ゲートウェイ:第 4 層のトランスポート層以上が違う LAN システム相互間のプロトコル・データ形式の変換を担う
- ゲートウェイはアプリケーションプロトコルの内容を 解釈できる
- アプリケーションヘッダの不正な情報混入を検出可能
- ファイアウォール・プロキシサーバもゲートウェイの一種
P.378 L4スイッチ・L7スイッチ¶
- L4スイッチ(レイヤ4スイッチ)はトランスポート層(第4層)の装置
- 定義としてはゲートウェイ
- 機能的にはレイヤ2スイッチ・レイヤ3スイッチの延長上
- ルータやレイヤ3スイッチはIPアドレスを参照して経路制御する
- L4スイッチではTCPポート番号やUDPポート番号も経路制御判断に使える:第4層の機器だから
- L7スイッチ:アプリケーション層(第7層)までの情報を使って通信制御する
P.379 7.2.5 VLAN¶
- VLAN(Virtual LAN:仮想LAN)
- スイッチ(レイヤ2スイッチ,レイヤ3スイッチ)で物理的な接続形態とは独立に仮想的なLANグループを構成する仕組み,あるいはそう構成されたLAN
- 複雑な形態のネットワークを楽に構築できる
- サブネット構成も柔軟に変えられる
P.380 データリンク層の制御とプロトコル¶
- データリンク層:第2層
P.380 7.3.1 メディアアクセス制御¶
- 複数のデータを1つのケーブルを通して送受する場合,データの衝突(コリジョン)を回避するための制御が必要
- これがメディアアクセス制御(Media Access Control:MAC)
コリジョン(衝突)¶
イーサネットや無線LANで複数の端末が送信し、データが衝突する現象を指す。旧式のイーサネット規格では、端末同士を接続するときに1組の通信路で双方向の通信を行う半二重通信のため、送信と受信を同時に行うことができない。送信と受信をその都度切り替えて行うので、端末がお互いデータを送信してしまうと衝突する可能性が高くなる。
P.380 CSMA/CD¶
- CSMA/CD:Carrier Sense Multiple Access with Collision Detection:搬送波感知多重アクセ ス/衝突検出)の略。
- イーサネットで採用されている方式
- 衝突検知方式を採用
- イーサネット:IEEE 802.3として標準化されている LAN規格
- CSMA/CD
- 各ノードは伝送媒体が使用中かどうかを調べて,使用中でなければデータを送りはじめる
- 複数のノードが同時に通信しはじめるとデータの衝突が起こる
- 衝突を検知し,一定時間(ランダム)待った後で,再送
- 一定の距離以上のケーブルでは衝突が検知できない
- CSMA/CD方式の限界
- トラフィックが増加するにつれて衝突が多くなる
- 再送が増え,さらにトラフィックが増加する悪循環に陥る可能性がある
- 特に伝送路の使用率が30%を超えると実用的でなくなる
P.381トークンパッシング方式¶
- トークンによる送信制御を行う方式で
- トークンバス方式
- トークンリング方式
P.381 トークンパッシング方式¶
- ネットワーク上をフリートークンと呼ばれる送信権のためのパケットが巡回する
- フリートークンを獲得したノードだけが送信できるので衝突を避けられる
- ふつうはコンセントレータ(集線器)でネットワ ークとノードを結ぶ
- トークンパッシング方式を採用したLAN規格
- 例:FDDI:Fiber Distributed Data Interface
- FDDIは物理媒体に光ファイバを利用し,最大100Mビ ッ ト/秒の通信
- 特徴
- 伝送媒体上では衝突しない
- トラフィックが増えるにつれてトークンを獲得しにくくなり,少しずつ遅延時間が増える
- 衝突による再送制御の必要がないため伝送路の使用率に対する遅延時間の増加率はCSMA/CD方式より緩やか
P.382 TDMA 方式¶
- TDM(時分割多重)
- ネットワーク上にデータを送信する時間を割 り当てる(タイムスロット)
- タイムスロットごとに別のデータを送って多重化する
- TDM によるアクセス制御が TDMA
- TDMA(Time Division Multiple Access:時分割多重アクセス)
- CSMA/CD・トークンパッシング方式と並ぶ主要なデー タリンク技術
- TDMA ではネットワーク(伝送路)を使える時間を細かく区切る
- 割り当てられた時間は各ノードが独占する方式
- TDMAはコネクション型の通信
P.382 7.3.2 無線LANのアクセス制御方式¶
P.382 CSMA/CA方式¶
- CSMA/CA:Carrier Sense Multiple Access with Collision Avoidance、搬送波感知多重アクセス/衝突回避
- 無線 LAN の制御方式
- CSMA/CD との違い:「衝突検出」が「衝突回避」になった
- 無線 LAN:物理層媒体は電波で衝突の検出は不可能だから回避する
- 特徴
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
- 待ち時間をバックオフ制御時間とよぶ
- 衝突してフレームが壊れても検出できない
- データを受け取ったノードは ACK を返す
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
P.328 RTS/CTS¶
- 無線 LAN の話
- 隠れ端末問題
- 他のノードのデータ送信を感知できないことがある
- 通信ノード間の距離が遠い
- ノード間に障害物がある
- 回避のための RTS/CTS 方式
- 無線 LAN ノード
- データ送信前にRTS(Request ToSend:送信リクエスト)をアクセスポイントに送信
- これを受理したアクセスポイントがCTS(Clear to Send:送信OK)を返信
- 他のノードは CTS を傍受して自分以外の別のノードに送信権があると解釈
- データ送信を延期
- 無線LANノードはアクセスポイントからCTSを受信したらデータ送信開始します
- 衝突抑制:CTSに書かれた他のノードに対する送信抑制時間を使う
- データ送信開始前にデータ送信のネゴシエーシ ョンとして RTS/CTS 方式を使った CSMA/CA を CSMA/CA with RTS/CTS とよぶ
P.383 無線LANの動作モード¶
- 無線 LAN の動作モード:図7.3.4参照
- 2 つのモードがある
- インフラストラクチャモード:無線LANノードがアク セスポイントを通じて相互に通信
- アドホックモード:アクセスポイントなしに無線LANノードどうしが直接通信
P.383 COLUMN FDMA,CDMA¶
- 表7.3.1:多元接続する技術グループ
- TDMA とセット
- FDMA
- ある周波数帯をさらに細かい周波数帯に分割
- 接続できる端末数を増やす技術
- CDMA
- 周波数も時間も分割しない
- 符号で各端末の通信を識別・分離
- 接続できる端末数を増やす
P.383 7.3.3 データリンク層の主なプロトコル¶
- 第 2 層
P.384 ARP¶
- ARP(Address Resolution Protocol):通信相手のIPアドレスからMACアドレスを取るためのプロトコル
- ARPの動作
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- ブロードキャスト:ネットワークに参加するすべての機器に同時に信号やデータを送ること
- 各ノードは自分のIPアドレスと比較
- 一致したノードだけARP応答パケットに自分のMACアドレスを入れて返す(ユニキャスト)
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- 参考:GARP(Gratuitous ARP)
- 主な目的:自身に設定するIPアドレスの重複確認・ARPテ ーブルの更新
- 目的IPアドレスに自身が使うIPアドレスを指定し,MACアドレスを問い合わせる
P.384 RARP¶
- Reverse-ARP:逆アドレス解決プロトコル
- MACアドレスからIPアドレスを取る
- 電源オフ時にIPアドレスを保持できない(IPアドレスを保持するハードディスクをもたない)機器が電源オン時に自分のMACアドレスから自身に割り当てられているIPアドレスを知るために使う
- RARP サーバー
- MACアドレスとIPアドレスの対応表を持ったサーバー(RARPサーバー)が必要
P.384 PPP¶
- PPP:Point to Point Protocol
- 2 点間をポイントツーポイントでつなぐためのデータリンクプロトコル
- WANを介して2つのノードをダイヤルアップ接続するときに使う
- ネットワーク層(第3層)とネゴシエーションする NCP(ネットワーク制御プロトコル)とリンクネゴシエーションするLCP(リンク制御プロトコル)からなる
- NCP:Network Control Protocol
- LCP:Link Control Protocol
- リンク制御やエラー処理機能を持つ
P.384 PPPoE¶
- PPPoE:PPP over Ethernet
- PPPと同等な機能をイーサネット(LAN)上で実現するプロトコル
- PPPフレームをイーサネットフレームでカプセル化して実現
P.384 7.3.4 IEEE 802.3規格¶
- メディアアクセス制御に CSMA/CD 方式を使う LAN についての標準
- OSI基本参照モデルにおけるデータリンク層(第 2 層)と物理層(第 1 層)のプロトコルおよびサービスを規定
- OSI 基本参照モデルでのデータリンク層を LLC 副層と MAC 副層の2つに分割
- 物理層での LAN で使う伝送媒体や MAC 副層でのフレーム構成や衝突検出の仕組みを規定
- ツイストケーブルの企画が表 7.3.2 にまとまっている
P.386 7.4 ネットワーク層のプロトコルと技術¶
- もうやった
P.300 6.3.2 正規化の手順¶
P.300 第 1 正規化¶
- 非正規:くり返し部分をもつテーブルのこと
- まずもってくり返しという言葉の理解自体がたぶん面倒
- いろいろな例に触れてみよう
- RDB は平坦な 2 次元の表(テーブル)
- くり返し部分をもつ表から繰り返しを排除してスリム化したい
- 第 1 正規化:くり返しを排除する操作
- 第 1 正規形:第 1 正規化して得られた表のこと
- cf. P.300 図6.3.4 の売上表
- P.300 図 6.3.5
- 売り上げ明細表:主キーの売上番号とくり返し部分を一意に決める商品番号が複合キー
- 別の表に分解する
- 外部キー:他のテーブルの主キーである売上番号を参照している
- 分解・独立させた表に元の表の主キーをもたせる理由:結合で元の表を再現するため
P.301 第1正規形におけるデータ操作での不具合¶
- 第1正規形になった表は RDB 上で定義できる
- データの冗長性のためにデータ操作時に不整合を起こさないように注意が必要:更新時異常の概念
- 種類は以下の通り
- 例は本 P.300 の売り上げ表・売上明細表から
- 第 1 正規形では以下のような更新時異常が起きる可能性がある
- 防止策が第 2 正規化・第 3 正規化
- どこまでどうやるかは状況次第
P.301 修正時異常¶
- 商品名「オレンジ」を「清見オレンジ」に変更したい
- 該当する行をすべて同時に変更しなければならない
- 1行でも変更し忘れるとデータ不整合が起きる
- 先に対策を書いておく
- 売上明細には商品番号だけ持たせて、商品名を削る
- 削った代わりに商品テーブルを作る
- (ふつう商品テーブルには単価も切り出す)
- (単価に消費税を載せるかどうかといった問題もある)
P.301 挿入時異常¶
- 売上明細表の主キーは売上番号と商品番号の複合キ ー
- 売上のない("売上番号"が空値)商品は登録できない
- どうやらこの本の「売上表」は商品テーブルも兼ねているらしい
- 先に対策
- 商品テーブルを別に作って、そこからの参照という形にする
P.301 削除時異常¶
- (先程と同じくこの本の売り上げ表は商品テーブルも兼ねている模様)
- 売上実績が 1 つしかない商品のの売上データを削除す ると商品データも削除される
- 逆に商品データを残そうとすれば売上データは削除できない
- 先に対策:商品テーブルを切り出す
P.301 第2正規化¶
- 第2正規化:すべての非キー属性が各候補キーに完全関数従属である状態にする操作
- 第1正規形の表に対して行われる操作
- 候補キーの一部に部分関数従属する非キー属性を別の表に分解する
- 第2正規化して得られた表を第2正規形という
- 例:図6.3.7の売上明細表
- 候補キーは主キーの{売上番号,商品番号}の1
- 非キー属性である商品名と単価は主キーの一部である商品番号に部分関数従属している
- 商品表として独立させる
- 分解の仕方
- 商品表の主キーを商品番号
- 図6.3.7の上の表を再現できるようにする
- 売上明細表(図6.3.7の下の表)には商品表の主キーを参照する外部キーとして"商品番号"を残す
P.302 メモ¶
- 第2正規化するのは候補キーが複数の属性で構成されている場合。
- 1つの属性で構成されているのであれば部分関数従属は存在しない
- 既に第2正規形
- 非キー属性:どの候補キーにも属さない属性
- 第2正規形:どの非キー属性も候補キーの真部分集合に対して関数従属しない
- どの非キー属性も候補キーに完全関数従属
P.302 第3正規化¶
- 第3正規化:非キー属性間の関数従属をなくしてどの非キー属性も候補キーに直接に関数従属している状態にする
- 第2正規形の表に対して行われる操作
- 候補キーに推移的関数従属している非キー属性を別の表に分解
- 第3正規化して得られた表を第3正規形
- 例:図6.3.8の売上表
- これは第2正規形
- 顧客番号→顧客名いう非キー属性間の関数従属がある
- 顧客番号を主キーとした顧客表として独立させる
- 売上表には顧客表の主キーを参照する外部キーとして顧客番号を残す
P.303 メモ¶
- 第3正規形:どの非キー属性も候補キーに推移的関数従属しない
- どの非キー属性も候補キーに直接に関数従属している
- ボイス・コッド正規形
- 第3正規形では次の関数従属が存在する可能性がある
- 候補キーの真部分集合から他の候補キーの真部分集合への関数従属
- 候補キー以外の属性から候補キーの真部分集合への関数従属
- この関係を分解したのがボイス・コッド正規形
- 第3正規形では次の関数従属が存在する可能性がある
P.303 正規化と非正規化¶
- 正規形には第1正規形から第5正規形まである
- たいていの用途ではデータベースの場合、第3正規形まで正規化されていれば十分といわれている
- 正規化の目的はデータ操作にともなう更新時異常の発生を防ぐこと
- 属性間の関数従属を少なくする
- データの重複を排除する
- 正規化のデメリット
- 表がいくつにも分割される
- 必要なデータを取り出すために表を結合しないといけない
- 処理時間がかかる
- 処理速度が必要な時や更新時異常の発生が低い場合はあえて正規化しない・正規化を解く
- たとえば更新が少ない表は正規化しない
- ここでの「非正規化」:アクセスパターンを考えたうえでどの表を統合するか、どの属性を表間に重複させるか考える
P.304 6.4 関係データベースの演算¶
P.304 6.4.1 集合演算¶
- 関係データベースでの集合演算
- 同じ型の表間での和、共通部分(積)、差
- 直積:同じ型の表でなくてもいい
P.304 和、共通(積)、差¶
- 図6.4.1の表AとBに対するそれぞれの演算結果を見る
- 本参照
P.305 直積演算(Cartesian Product:×)¶
- 社員表と部門表の直積は社員表の各行に対して部門表の行を1つずつつなぎ合わせた表
- 直積の結果として得られる新しい表を直積表と呼ぶ
- 次数(属性の数)は両方の表の次数を足した数
- 位数(タプルの数)は両方の位数を掛けた数
- 直積が役に立つイメージがない:実際には結合 (JOIN) を本当によく使う
P.305 6.4.2 関係演算¶
- 関係演算:関係データベース特有の演算
- 射影,選択,結合,商
- 関係代数:関係演算と集合演算を合わせた代数
- 導出表:これらの演算によって得られた表
P.306 SQL の例¶
- 先に持ってきてみた
SELECT 社員コード, 社員名, 部門表.部門コード, 部門名
FROM 社員表, 部門表
WHERE 社員表.部門コード = 部門表.部門コード
P.305 選択と射影¶
- 選択演算:表から指定した行を取り出す関係演算
- SQL でいう WHERE
- 射影演算:表から指定した列を取り出す関係演算
- SQL でいう SELECT column_name
P.306 結合¶
- 参考:P.306 の下の表
- 結合演算:2つの表が共通にもつ項目(結合列)で結合して新しい表をつくり出す関係演算
- まさに正規化でわけたテーブルを結合させる演算
- SQL:SELECT文のFROM句で複数の表名をカンマで区切って指定
- WHERE句で結合条件を指定
- 結合条件
- 結合列の値を>,≧,=,≠,≦,<のいずれかの比較演算子で比較して結びつける
- 等結合:比較演算子が「=(等号)」である結合
- 2つの表から作成される直積表から結合列の値が等 しいものだけを取り出す
- 得られた新たな表には結合列が重複して含まれる
- SELECT句でどちらか一方の結合列を指定して見かけ上の重複を除く
- 自然結合(natural join):重複する結合列を取り除く(一方のみ残す)ようにした結合
- 結合列の列名が2つの表で同じ場合に使える
- 参考
- (意識的に使ったことがない)
P.307 内結合と外結合¶
- 参考:P.307 の図 6.4.8
- 内結合(INNER JOIN)
- 結合列の値が等しい行だけを取り出す結合演算
- 片方の表にしか存在しない行は取り出せない
- データベース言語仕様(JIS X 3005)
- 外結合(OUTER JOIN)
- 片方の表にしか存在しない行も取り出せる結合
- 結合相手の表に該当するデータが存在しない場合はNULL(空)値で結合
- 左外結合・右外結合・完全外結合
- 等結合
- 結合する表をFROM句で指定、結合条件はWHERE句 で指定
- 内結合・外結合
- 結合する表をFROM句の中でJOINを使って指定
- 結合条件は JOIN に続くON句で指定する
- 参考:p309のコラム「内結合と外結合のSQL文」
P.307 左外結合(LEFT OUTER JOIN)¶
- 参考:P307 図 6.4.9、P309 の SQL 文
- 結合する左の表(社員表)が基準
- 右の表(部門表)に存在しない行を空値(NULL)として結合
P.308 右外結合(RIGHT OUTER JOIN)¶
- 参考:P.308 図 6.4.10
- 結合する右の表(部門表)が基準
- 左の表(社員表)に存在しない行をNULLとして結合
P.308 完全外結合(FULL OUTER JOIN)¶
- 参考:P.308 図 6.4.11
- 片方だけに存在する場合もう片方をNULLとして結合
P.308 商¶
- (これ何だろうか?where の
in?)- 普通に
inまたは =`= でよさそう? selectも含んでいる?
- 普通に
- 参考:P.308 図 6.4.12
- 関係R(X,Y1,Y2)とS(Y3,Y4)がある
- S(Y3,Y4)のすべての行がR(Y1,Y2)に含まれる場合に対応するR(X)を求める演算
- 商(R÷S)は関係Rの中から関係Sのすべての行を含む行を取り出し、そこから関係Sの項目を除く
- 重複行も除く
- 参考:P.309、図6.4.13
- 社員表から東京に住み営業2課(E02)に勤務する社員を探す場合に商演算を使う
P.309 COLUMN 内結合と外結合の SQL¶
- 本を読もう
P.310 6.5 SQL¶
P. 310 6.5.1 データベース言語SQLとは¶
- SQL(Structured Query Language)
- RDB の標準的な操作言語
- ほとんどの RDBMS が SQL を使っている
- Relational DataBase Management System
P.310 SQLの分類¶
- RDB のデータを検索(参照)、操作
- データ定義
- トランザクション制御
- 参照:表 6.5.1 に SQL 文が書いてある
P.310 表 6.5.1 重要な SQL¶
- DDL (Data Definition Language)
- CREATE, DROP, GRANT, REVOKE
- DML (Data Manipulate Language)
- SELECT, INSERT, UPDATE, DELETE, COMMIT, ROLLBACK, DECLARE CURSOR, OPEN, FETCH, CLOSE
- DECLARE CURSOR以降は親言語方式などで使用されるSQL
- 親言語方式
- CやCOBOLなどのプログラム中にSQL文を組み込んでデータベースにアクセスする方式。
- 埋込みSQL:p328参照
P.311 6.5.2 SELECT文¶
- データ操作言語(DML)
- 問合せ(SELECT)文
- 挿入(INSERT)文
- 更新(UPDATE)文
- 削除(DELETE)文
- などなど
- SELECT文以外のDMLは「6.5.3 その他のDML文」(p319)参照
P.311 SELECT文の構文¶
- SELECT文の基本構文
- [ ]内は省略可能
SELECT
[DISTINCT]
列名のリスト
FROM 表名のリスト
[WHERE 選択条件や結合条件]
[GROUP BY 列名のリスト]
[HAVING グループ選択条件]
[ORDER BY 列名のリスト]
- リスト:列名および表名をカンマ(,)で区切って列挙したもの。
P.311 行、列の取り出し¶
- 選択:WHERE句に選択条件を指定すると特定の行を取り出せる
inとリストを使うと複数行に対する- 具体例を考えないと使い分けや気分はわからなそう
- 射影:SELECT句に列名を指定すると特定の列を取り出せる
- SELECT句への
*:全部の列を取りだす - 選択条件と論理演算子(AND・OR・NOT):複数の条件を組み合わせる
- 表 6.5.2:選択条件に使う比較演算子の表
- 参考:列の値が「空値(NULL)であるか」という検索条件
WHERE 列 IS NULLWHERE 列 = NULLではない- NULL は他にもいろいろ邪悪な面がある
- 空文字列などとは違う概念でよくはまる
SQL 例¶
- P.312、図 6.5.1
- 社員表から年齢が24以上28以下の社員コード・社員名を表示するサンプル
SELECT 社員コード, 社員名 FROM 社員表 WHERE 年齢 >= 24 AND 年齢 <= 28
P.312 BETWEEN述語¶
- 先のSELECT文はBETWEEN述語やIN述語を使って同じ内容を表せる
- BETWEEN述語は「値1~値2」の範囲(値1,値2を含む)に列の値が含まれるかを選択条件にする
SELECT 社員コード, 社員名 FROM 社員表 WHERE 年齢 BETWEEN 24 AND 28
P.312 IN述語¶
- IN述語は列の値が指定された値のいずれかと等しいかを選ぶ条件にする場合に使う
- INの前にNOTをつけると指定された値のいずれでもないという選択条件になる
- IN述語の使用例については副問合せ(p317)も参照
P.313 重複行の排除¶
- 取り出された行の中から重複するものを除きたい場合
- SELECT句の列名指定にDISTINCT述語を使う
P.314 出力順の指定¶
- ORDER BY 句:特定の列の値で昇順・降順に並べ替えて表示する
- ORDER BY のあとに続けて並べ替えのキー(列名)を指定
- 降順の場合はDESC、昇順の場合はASC
- ふつう ASC がデフォルトで省略できる
SELECT 社員名, 年齢 FROM 社員表 ORDER BY 年齢 DESC
P.314 グループ化¶
- GROUP BY 句:取り出した行を指定した列の値でグループ化
- グループごとの合計や最大値などを求める
- HAVING 句:条件に合ったグループだけを取り出す
SELECT 所属, COUNT(), AVG(年齢) FROM 社員表 GROUP BY 所属 HAVING COUNT() >= 2
- SQL の簡単な解説
- 社員表のデータをGROUP BY句を使って所属でグループ化
- HAVING 句で「グループに所属する人数が2人以上」のグループだけを取り出す
- 取り出したグループごとにその所属・人数・平均年齢を求める
P.315 表の結合¶
- 2 つの結合
SELECT A FROM B WHEREによる等結合FROM句の中でのJOIN ... ONによる内結合や外結合
- どちらであっても結合表には結合条件で指定した結合列が重複して含まれる
- 列名を指定するときは「表名.列名」という形式で表す
P.316 表に別名をつける¶
- FROM句で「表名 AS 別名」あるいは「表名 別名」と指定すると表名に対して別名(相関名)を設定できる
- 自己結合:表に別名を与えると同じ表どうしを結合できる
- 自己結合については P.317 の例を参照
- 上司コードを使ってある社員とその上司の氏名や関連情報を見たい場合に使う
P.317 副問い合わせ¶
- サブクエリともいう
- SELECT文のFROM句やWHERE句・HAVING句などに指定されている入れ子になったSELECT文
SELECT 社員コード, 社員名, 年齢 FROM 社員表 WHERE 年齢 IN (SELECT 指定年齢 FROM 調査対象)
- サブクエリにはいろいろ面倒な話がある
- 参考:MySQL のサブクエリって、ほんとに遅いの?
- これは 2017 年の記事:この辺はお金になるので割と日進月歩で、3 年程度の昔の情報でも既に参考にならないことも多い。
- 簡単なまとめ
- 遅いのは2番目、DEPENDENT SUBQUERYである
- MySQL 5.5 までサブクエリはやっぱり遅い
- MySQL 5.6 からはそんなに遅くなくなった
- MySQL とはいってもバージョンによって全然違う:オプティマイザは進化している
- 現状についてはきちんと最新の話を追う、または自分が必要なケースについて実測する
P.318 EXISTS述語¶
- サブクエリはEXISTS述語でも表せる
- 参照:P.318 の例
- EXISTS は相関副問合せが何らかの結果を返した場合にTRUE(真),何も返さなかった場合にFALSE(偽)を返す
- 主問合せの結果1行に対して相関副問合せから何らかの結果が戻されれば、主問合せの選択条件は成り立ち、何も返されなければ選択条件は成り立たない
- EXISTS 述語でほかの表にも存在するものを調べられる
- ANY でも同じ操作を表せる
- 参考:P.318 の例
- 副問合せの結果のいずれか(ANY)と等しい
- どれがいいかは最終的にはテーブルの実装や使っている RDBMS とバージョンに依存する
- 実測してチューニングしよう
P.319 6.5.3 その他の DML 文¶
P.319 INSERT文¶
- 表に行を挿入する:2つ方法がある
- 参考:本の P.319
- 挿入する値をVALUES句で指定する
- 問合せの結果をすべて挿入する
- (DBMS によるかもしれないが)個別INSERTと一括INSERTもある:パフォーマンスでよく問題になる
- 一部の列に対して INSERT
- どの列に対して挿入するのか列名リストで指定
- 省略された列の値はDEFAULT制約があればその既定値、そうでなければNULL値
- NULL はなるべく使うのをやめよう
- DEFAULT は P.322 表 6.6.1
P.319 UPDATE文¶
- 表中のデータを変更
- 列の変更値を直接指定する
- 変更値をCASE式で決める
- 副問合せの結果を変更値にする
- SET句には変更したい列の値を「列名 = 変更値」の形で指定
- 1 つのUPDATE文で複数の列の値を変えるときはカンマ(,)で区切って指定
- WHERE句を省略すると表中のすべての行が変わる
- ふつうはやらない
- WHERE句を指定すれば条件に合った行だけ変わる
P.320 DELETE文¶
- 表中の行を削除する
- 表中の全行を削除しても表自体は残る
- 表を削除するのはDROP文
- WHERE句を省略すると表中のすべての行が削除される
- WHERE句を指定するとその条件に一致した行だけを削除できる
P.320 参照関係をもつ表の更新¶
- 関連する2つの表の間に参照制約が設定できる
- 被参照表の主キー(候補キー)にない値を参照表の外部キーに追加できない
- 被参照表の行の削除・変更時に制約が出る:図6.5.10参照
- 参照動作指定:削除・変更時の制約は明示的に指定できる
- 次節のCREATE TABLE文を参照
- REFERENCES句(参照指定)の後に次の構文で指定
参照動作指定 REFERENCES 被参照表(参照する列リスト) ON DELETE 参照動作] [ON UPDATE 参照動作] (*[ ]内は省略可能)
- 指摘できる参照動作:表 6.5.5 の 5つ
- デフォルトは NO ACTION
P.320 補足¶
- 参照制約
- 外部キーの値が被参照表の主キーあるいは主キー以外の候補キーに存在することを保証する制約。
- 関連する2つの表の間に参照制約を設定する目的:データ矛盾を起こすような行の追加や削除・変更を排除するため
- REFERENCES指定:p322-324を参照
- データの整合性を保つための制約
- 一意性制約
- 参照制約
- データ項目のデータ型や桁数に関する形式制約
- データ項目が取り得る値の範囲に関するドメイン制約がある。
P.322 6.6 データ定義言語(DDL)¶
P.322 6.6.1 実表の定義¶
P.322 CREATE TABLE文¶
- 表の定義はには CREATE TABLE 文
- 基本構文は P.322 参照
P.322 列制約¶
- 表を構成する列に対する制約
- 参考:表6.6.1
- 一意性制約:同一表内に同じ値が複数存在しないことを保証する制約
- 主キーとなる列には一意性制約にとNOT NULL制約を加えたPRIMARY KEY指定
- 主キー以外の候補キーにも一意性制約がある
- 一般にNULL(ナル)値は重複値とは扱われない
- 候補キーにはNULL値を許すUNIQUE指定
- 参照制約:外部キーの値が被参照表に存在することを保証する制約
- 外部キー:REFERENCES指定(参照指定)す。
P.323 表制約¶
- 一意性制約・参照制約・検査制約は表制約(表定義の要素として定義される制約)にもできる
- 列制約:1つの列に対する制約
- 主キーや外部キーが複数列から構成される場合、これを列制約として定義できない
- このときは表制約を使う
P.323 主なデータ型¶
- 一般的な文字型,数値型は覚えておくといい
P.324 実表の定義例¶
- P.324 の社員表と部門表を定義を見てみよう
P.325 6.6.2 ビューの定義¶
P.325 ビューとは¶
- 実表:ディスク装置上にあり実際にデータが格納される表
- ビュー:実表の一部または複数の表から必要な行や属性(列)を取り出してあたかも1つの表 であるかのように見せかけた仮想表
- 利用者から見れば実表と同じ
- データを検索するだけなら制約はあっても同じように操作できる
- ビューのメリット
- あくまでも仮想の表:対象となった元の表(基底表)の列名と別の名前で定義できる
- ビューに定義することで情報を公開
- ビューに定義しないことで情報を非公開にできる
- 元の表に新たな列が追加されても既存のビューには影響がなく再定義する必要がない
- ビューは仮想的な表
- 一般には実体化されずデータ格納領域をとら ない。
- 実表のように実体化されるビューもある:体現ビュー(materialized view)
P.325 CREATE VIEW文¶
- ビューの定義:CREATE VIEW文による:詳細は本の P.325
- ビュー:対象となる実表(あるいは他のビュー)からSELECT文で必要データを導出する方法で定義される定義するビューの列名に命名規則はない
- 列数はAS句に続くSELECTで問い合わせた結果の列数と同じでなければならない
- 列名は省略可能:省略した場合はSELECTで問い合わせた結果の列名がそのまま定義される
- ビューに対する参照や更新処理
- ビューの対象となった表(基底表)に対す る参照あるいは更新処理に変換されて実行される
P.326 ビューの定義例¶
- 本の P.326 参照
- 社員表と部門表から社員コードと社員名、その社員が所属する部門名からなる表をビュー「社員表2」
- JOIN して必要なカラムだけ取り出す
P.326 ビューの更新¶
- ビューへの更新処理 ビュー定義を基にビューが参照している表(基底表)への対応する処理に変換されて実行
- 更新のための条件
- 更新にかかる実際の表が更新可能
- 更新される表の列や行が一意に決まる
- 更新できないビューの例
- SELECT句で式、集合関数、DISTINCT を使ったSELECT文で定義されている
- ・GROUP BY句やHAVING句を使ったSELECT文で定義されている
P.327 6.6.3 オブジェクト(表)の処理権限¶
- スキーマに定義された実表やビューはそのスキーマ所有者(作成者)にしか処理権限が与えられない
- 複数の利用者がデータベースを利用できるようにしたければ、スキーマ所有者以外にも処理権限を付与する必要がある
- データベース管理ユーザーは全権を持っていて危険な処理もできてしまう
- できることを制限したユーザーで操作したい
- オブジェクト(表)の処理権限
- 読取(SELECT)権限
- 削除(DELETE)権限
- 挿入(INSERT)権限
- 更新(UPDATE)権限
- cf. スキーマ
- 1つのデータベースの枠組み
- スキーマ内に複数の表やビューを定義できる
P.327 処理権限の付与¶
- 権限の付与:GRANT文による
- GRANTの基本構文は次の通り
1 | |
- 権限指定
- 4 つの処理権限(SELECT,INSERT,UPDATE,DELETE)
- ALL PRIVILEGES(すべて)を指定できる
- 権限を複数付与する場合はカンマ(,)で区切って指定
P.327 処理権限の取消し(変更)¶
- 一度付与された権限を取消し(変更)できる
- 権限の取消しはREVOKE文
- REVOKEの基本構文
1 | |
P.328 6.7 埋込み方式¶
P.328 6.7.1 埋込みSQLの基本事項¶
P.328 静的SQLと動的SQL¶
- 静的 SQL:あらかじめ決められたSQL文をプログラム中に埋込んで実行する方式
- 実際のアプリケーションではあまり見かけない
- 非カーソル処理:データベースの表から1行を取り出すこと
- 次のような SELECT 文
- この
INTOを見たことがない
SELECT 社員名, 年齢 INTO :name, :age FROM 社員表 WHERE 社員コード = '100';
- 動的 SQL:実行する SQL 文がプログラム実行中でな ければ決まらない場合に SQL 文を動的に作成し実行する方式
- 上の社員コードがふつう変わる:それが「動的」。
- この動的な部分に変なコードを埋め込むとまずいというのがセキュリティ問題で、例えば SQL インジェクションの問題。
P.328 ホスト変数¶
- ホスト変数:データベースとプログラムのインタフェースとなる変数
- 埋め込み SQL では SQL を実行すると取り出されたデータをINTO句で指定したホスト変数に格納する
- ホスト変数は通常の変数としてもアクセスできる
- 出力関数で表示
- 入力関数で値を入力してそれをSELECT文の条件としても使える
P.329 6.7.2 カーソル処理とFETCH¶
P.329 カーソル処理¶
- 「SELECT・・・・INTO・・・」形式では,1行のデータしか取り出せない
- (見たことがないのでイメージがつかない)
- 検索結果が複数行の場合は1行ずつ取り出せるカーソル処理を使う
- カーソル処理は SQL 文で問い合わせた結果をあたかも1つのファイルであるかのようにとらえる
- FETCH文でそこから1行ずつ取り出す方式
- 1つのSELECT文に対してカーソルを宣言(定義)
- カーソルのオープンでSELECT文が実行
- カーソルで1行ずつ取り出せる
- FETCH文で繰返し行を取り出して処理
- 終了したらカーソルを閉じる
P.330 FETCHで取り出した行の更新¶
- 参考:図 6.7.2:FETCHで取り出した行の更新処理
- FETCH文で取り出した行を更新あるいは削除する場合,FETCH文のあとに続くUPDATE文やDELETE文のWHERE句 に「WHERE CURRENT OF カーソル名」と指定する。
- (FETCH 文を見たことがないのでイメージつかない)
P.330 処理の確定と取消し¶
- 一連のデータを更新している途中でエラーが出た場合
- それまでの更新処理を取り消して元に戻す必要がある
- 整合性を取らないといけない:いわゆるロールバックが必要
- トランザクションが正常終了したときは「コミット」する:更新処理の確定
P.331 6.8 データベース管理システム¶
P.331 6.8.1 トランザクション管理¶
P.331 トランザクションとは¶
- 複数の利用者が同時にデータベースにアクセスしてもデータが矛盾してはいけない
- この仕組みがトランザクション管理
- トランザクション:データの整合性を取るための SQL 処理の最小単位
- 「回復の単位(Unit of Re-covery)」とも呼ぶ
P.331 ACID 特性¶
- トランザクション処理は原子性・一貫性・隔離性・耐久性の 4 特性が必要
- 厳密な一貫性(完全一貫性)が必要
- トランザクションではそのすべての処理が完了するか(All)、あるいはまったく実行されていない状態か(Nothing)のどちらか一方で終了しなければならない
- これは,COMMIT(正常終了),、ROLLBACK(異常終了)で実現できる
- COMMIT(コミット):更新処理を確定し、データベ ースへの反映を保証する
- ROLLBACK(ロールバック):更新処理をすべて取 消し,トランザクション開始時点の状態へ戻す
- 参考:結果整合性
- 完全一貫性に対する概念
- 分散トランザクションやいわゆる NoSQL で使われる
- 参考:分散トランザクション
- トランザクション管理するべきテーブルが複数のデータベースにまたがっているとき
- すべてのデータベースをロールバックしなければいけない
P.331 表 6.8.1 ACID 特性¶
- 原子性(Atomicity)
- 更新処理トランザクションが正常終了した場合だけデータベースへの反映を保証する
- 異常終了時は処理が何もなかった状態に戻す
- 一貫性(Consistency)
- トランザクションの処理によってデータベース内のデ ータに矛盾が生じないこと
- 常に整合性のある状態が保たれていること
- 隔離性(Isolation)
- 複数のトランザクションを同時(並行)に実行した場合 と,順(直列)に実行した場合の処理結果が一致するこ と
- 独立性ともいう
- トランザクションのスケーリング:複数のトランザクションを同時実行してもそれが正しい順で実行されるように順序づけること
- 基本は並行実行の結果と直列実行の結果が等しくなるように調整する
- ロック:直列可能性を保証する方法
- 耐久性(Durability)
- いったん正常終了したトランザクションの結果はそ の後に障害が発生してもデータベースから消失しないこと
- トランザクションの再実行を必要としないこと
P.332 6.8.2 同時実行制御¶
- 同時実行制御(並行性制御):複数のトランザクションを同時に実行しても矛盾を起こすことなく処理を実行するメカニズム
- 実現する方法:ロック・多版同時実行制御・時刻印アルゴリズム
- 多版同時実行制御に対してロックによる通常の同時実行制御を単版同時実行制御という
P.331 ロック¶
- 複数のトランザクションを同時実行してもその結果はトランザクションを直列実行した結果と同じでなければならない(ACID 特性の隔離性)
- 同時実行制御が行われない環境では結果が変わる場合もある
- 例:図 6.8.1 を見ること
- トランザクションTR1とトランザクションTR2が同じデータaを①→②の順に読み込む
- それぞれのトランザクションでデータaを③→④の順に更
- COMMITした場合トランザクションTR1がデータaを「a+5→10」に更新してもトランザクションTR2が aの値を「a+10→15」に更新してしまう
- トランザクションTR1における更新内容が失われる
- これを変更消失(ロストアップデート)という
- こうした問題を防ぐための対処法
- データベース管理システムではデータaにロック(鍵)をかける
- 咲にデータaをアクセスしたトランザクションの処理が終了するか、あるいはロックが解除されるまでほかのトランザクションを待たせる制御をする
- 参考 ダーティリード:他のトランザクションが更新中のコミットされていないデータを読み込むこと
P.333 デッドロック¶
- P.250 5.2.5 も参考にすること
- デッドロック:複数のデータに対してロックしようとして互いにロックの解除を待ち続けてしまう
- 例:図 6.8.2
- データA、B、Cを専有して処理するトランザクションTR1,TR2,TR3がある
- 各トランザクションは処理の進行に合わせて表に示される順(①→②→③)にデータを専有
- トランザクション終了時に3つの資源を一括して解放
- トランザクションTR1とトランザクションTR2はデッドロックを起こす可能性がある
- 再び図 6.8.2 を見る
- データを専有する順序が等しいトランザションTR1とTR3の間ではデッドロックは起こらない
- 異なる順や逆順でデータを専有するトランザクション間ではデッドロックが起きうる
- デッドロックが起きたときロールバックなどで 1 つのトランザクションを強制的に終了させてデッドロックを解除する
P.334 ロック方式¶
- 2相ロック方式・木規約
- ロック方式
- 第1相:使用するデータすべてにロックをかける
- 第2相:処理後にロックを解除する
- トランザクション内でのロック・解除はそれぞれ1回だけ
- 直列可能性は保証されるがデッドロック発生の可能性は 残る
- 木規約
- データに順番をつけてその順番どおりにロックをかける
- デッドロックが起きず、直列可能性を保証する
- データへの順番づけには木(有向木)を使う
- トランザクションの同時実行性が低くなるため特殊な用途で使う(どんなところで使うのだろう?)
- 参考:有向木
- 方向をもった有向グラフ(の 1 つ)
- データ構造とアルゴリズムを勉強しよう
- データベースは検索の便宜もあってデータ構造とアルゴリズムが大事
P.334 ロックの種類¶
- 占有ロック・共有ロックの 2 モード
- DBMS でトランザクションの同時実行性を高めるため
- 専有ロック
- データ更新するときに使うロック
- データに対するほかのトランザクションからのアクセスは一切禁止
- 共有ロックは
- ふつうデータの読取りの際に使用されるロックで
- 参照だけを許可
- 表 6.8.2 参照:2 つのロックモードの組み合わせによる同時実行の可否
- 専有:占有または排他ともいう
- 共有:共用ともいう
- 共有ロックで同時実行性を高める
- 先行トランザクションがロックしたデータを後続トランザクションが参照できる
- 待ちがなくなり同時実行性が高まる
- たいていのシステムでは書き込みよりも読み込みの方が多い
2021-01-17 課題¶
- 先に進む前に録画してあるか確認しよう
進捗¶
- 前回の進捗
- 基礎知識編:P.319 6.5.3 その他の DML 文
- 本編:04-01「期待値をコードで表す」まで
- 今回の進捗
- 基礎知識編:P.326 ビューの更新
- 本編:04-02「よくある条件付き確率密度関数(確率分布)」まで
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 勉強の日常組み込み系
- Julia:The Little Book of Julia Algorithmsを読んでみることにしました。適当に話します。
- そのうち取り組む事案:黒木さんの Julia での統計ネタ
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
TODO¶
- AWS のハンズオン
- 公式のハンズオン: 無料でできるハンズオンもたくさんある
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- 実際に競プロの問題をいくつか解いてみましょう。
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
日々の勉強¶
Julia¶
- The Little Book of Julia Algorithms
- リポジトリの対象ディレクトリ:ここ
- その他参考
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- ネットワークの話もいい加減飽きたので、しばらく DB の話
復習¶
- 3 つのスキーマ
- ユーザーが見るレベル
- 正規化などをかけておいたデータベースにもっていけるレベル
- 個々のデータベースに合わせた具体的なレベル
- インメモリの DB:コンピューターの基本的なハードウェア構成と意味を復習しよう
本の記述を追いかける¶
P.408 7.8 交換方式¶
P.408 パケット交換方式¶
- 回線交換方式と対になる概念
- 回線交換方式:通信を行うノード間で物理的な通信路を確保してから通信する
- 例:電話
- パケット交換方式について
- データ送信するノードはデータをパケットに区切る。
- ひとつひとつのパケットにヘッダを付けて送信。
- ネットワーク内ではパケット交換機にパケットがたまる
- ネットワークの状況に応じて順次送られる
パケット通信のメリット・デメリット¶
メリット¶
耐障害性 - 通信路を固定しないため,迂回経路が取れる。 - パケット交換機にデータが蓄積されているため,復旧まで待てる。 - パケット多重 - 1 対 1 の通信で回線を占有する必要がないため,1つの回線を多くのノードで共有でき,回線を効率的につかえる - 異機種間接続性 - パケット交換機で中継するときにプロトコル変換・速度変換でエンドノードどうしが同じプロトコルをサポートしていなくても通信できる
デメリット¶
- ネットワーク内の蓄積交換処理による遅延
- 蓄積交換処理による遅延解消のために主に回線の帯域を広げることで対応してきた
- 構造上,完全には遅延をなくせない
- パケット到着順序の不整合
P.408 ATM 交換方式¶
- ATM(Asynchronous Transfer Mode:非同期転送モード)
- 遅延のない回線交換方式とパケット交換方式の利点を得たい
- パケット交換方式の発展
- 遅延の原因をつぶす:特にパケットの多様性
- 多種多様なパケットに対応するために,パケット交換機はソフトウェア処理が必要 ^ ATM での工夫の一例:最も特徴的なのは,パケット(ATMではセルという)の長さをヘッダ部 5 バイト,ペイロード 48 バイトの53バイトに統一
- パケット解析がハードウェアだけでできる。
- ソフトウェアは不要になった。
- Wikipedia から
- 当初の意図に反して非常に複雑な技術になってしまった
- ATM は次世代の主流にならず限定的な使用にとどまった
- ATM の設計思想は MPLS へと引き継がれた
- 汎用のレイヤ 2 のパケットスイッチングのプロトコルとして、ルーターを介したIPの通信網で利用されている。
P.408 ペイロード(payload)¶
- データ通信で本来転送したいデータ本体の部分、ボディを指す。
- ATM ではペイロードのサイズを固定して処理を簡素化
- 難点:パケット全体に占めるペイロードのサイズが相対的に小さくオーバヘッドが大きい
P.410 輻輳¶
- フレームリレー:パケット交換方式の一種
- 1 つの回線を多数のユーザで共有。
- 回線がもつ潜在的な伝送能力(ワイヤスピード)を十分に引き出すうえで効果がある
- 輻輳:ユーザの利用が一時期に集中すると,ワイヤスピードを超えるパケットがネットワーク上に流れる
- ネットワークが輻輳状態になるとスループットが落ちる
- フレームリレーサービスを提供する事業者は,ネットワークが輻輳状態に陥ってスループットが低下しても最低限保証する通信速度を決めている
- CIR(Committed Information Rate:認定情 報速度)
P.370 7 ネットワーク¶
- 確か 7.4 から始めた気がするので 7 章はじめから
P.370 7.1.1 OSI基本参照モデル¶
- 改めて復習
- OSI(Open System Interconnection)基本参照モデル- 異なる設計思想・世代のシステムと円滑に通信するのが目的に標準化
- プロトコルの単機能化,交換の容易さが目的
- 階層化のおかげで一部の階層の技術体系が変わっても、その階層だけ取り替えればいい
- コスト・リスクを小さくする
P.370 プロトコルとサービス¶
- N 層:それぞれの階層のこと
- エンティティ:N 層に存在する通信機器などの実体
- この言葉はいろいろなところで出てきていろいろな意味で使われる
- もちろん気分的には適当な実体を指すことが多い
- プロトコル:N 層に属するエンティティが通信するための取り決め
- 上位の層が下位の層を利用しながら通信する
- 別の階層間のエンティティどうしが通信する窓口が必要
- これを提供するのが下位層:この機能をサービスと呼ぶ
- プロトコルに沿った仕様で製品を開発すれば別のベンダの機器でも通信できる
- 参考:ベンダーロックイン
特定ベンダー(メーカー)の独自技術に大きく依存した製品、サービス、システム等を採用した際に、他ベンダーの提供する同種の製品、サービス、システム等への乗り換えが困難になる現象のこと。
出来上がった情報システムの正確な仕様が、システムを開発・構築したベンダーにしか解らなくなる場合がある。結果、システムの保守・拡張・改修等の際、現存システムを開発・構築したベンダーに引き続き発注せざるを得なくなる。
- 「Excel で行政に提出する書類を作れ」事案もそれ。
- Apple 製品で身の回りを固めるのも同じ。
- 「多様性が大事」事案でもある。
7.1.2 TCP/IPプロトコルスイート¶
- プロトコル同士には相性がある
- 「ネットワーク層がこのプロトコルならトランスポート層はこのプロトコルにしておくとトラブルが少ない」
- 一般に同じ団体が作ったプロトコルはセットで使われることが多い
- このセットがプロトコルスイート ^ 最も代表的なのは IP を中心に組まれた TCP/IP プロトコルスイート
- 独自の階層モデルをもつ
P.372 TCP/IPの通信¶
- データをパケットに区切る
- 各パケットにヘッダを付けて送信
- ヘッダは各階層ごとに付加されて次の階層へと渡される
- 各ヘッダにはその階層で必要となる送信元や送信先,大きさ,順番などパケット自体に関する情報を含む
- TCPヘッダを付加したパケット:TCP セグメント
- IP ヘッダを付加したパケット:IP パケット
- MACヘッダを付加したパケット:MAC フレームあるいはイーサネットフレーム
P.372 MAC(Media Access Control)アドレス¶
- イーサネットや FDDI で使用される物理アドレス
- イーサネット (Ethernet):コンピューターネットワークの規格の1つ。オフィスや家庭で一般的に使用されている有線LAN (Local Area Network) の技術規格
- FDDI:LAN でデータ転送を行うための標準の一つ
- Fiber distributed data interface
- データリンク層
- 同じネットワークに接続された隣接ノード間の通信で相手を識別するために使う
- MACアドレスの長さ:6バイト
- 先頭24ビットの OUI(ベンダID)
- 後続24ビットの固有製造番号(製品に割り当てた番号)
- MAC アドレスは機器が固有にもつ番号
- 必ず一意に定まるように IEEE が管理
P372 ポート番号¶
- トランスポート層にでノード内のアプリケーションの識別に使う識別子番号
- 0-65535の範囲
- TCP/IPではパケット交換方式でデータをやり取りする
- よく使われるアプリケーションについてのポート番号は Well-Known ポートとして標準化
- TCP・UDPそれぞれで 0-1023 番までの番号を割り当てている
- SSH:TCP22番
- Telnet:TCP23番
- SMTP:TCP25番
- HTTP:TCP80番
- POP3:TCP110番
- IMAP4:TCP143番
- HTTPS :TCP443番
- NTP:UDP123番
- SNMP:UDP161番
- SNMP Trap :UDP162番
- セキュリティ対策のために標準とはポート番号を変えることもある
- Web 開発の本を読んでいると、いろいろな都合から http のポートを 80 以外にしていることもよくある。
- 80 の場合はポートを指定しなくてもいい
- 例:http://localhost/hoge/fuga
- 例:http://localhost:5000/hoge/fuga
- 80 の場合はポートを指定しなくてもいい
P.373 ネットワーク間の通信¶
- 同じネットワークに接続されたノード間はデータリンク層(第 2 層)の通信
- ネットワークを超えたノード間はネットワーク層(第 3 層)の通信 -実際に図 7.1.4 を見よう
- どこが IP アドレスでのやりとりか?
- どこが MAC アドレスでのやり取りか?
P.374 7.2 ネットワーク接続装置と関連技術¶
P.374 7.2.1 物理層の接続¶
P.374 リピータ¶
- ネットワーク上を流れる電流の増幅装置・整流装置
- 物理層:第 1 層
- データ通信はネットワーク上を流れる電流
- ケーブルが長いと電流が減衰・波形が乱れが起きる
- データが読み取れなくなる
- これを増幅するのがリピータ
- 大昔の電話は距離が遠いと音が小さく聞こえにくかった
- まさにこの減衰が問題
- リピータは 1:1 で繋ぐ
- 現在では複数のノードを接続できるマルチポートリピータ(ハブ)が使われるのが一般的
P.374 7.2.2 データリンク層の接続¶
- 第2層
P374 ブリッジ¶
- データリンク層に位置
- ネットワーク上を流れているフレーム(情報の単位)の MAC アドレスを認識して通信を中継する
- 接続されているノードをコリジョンドメイン(セグメント)という単位に分割
- MAC アドレスで判定したフレームのあて先のあるセグメントだけにフレームを送信
- 無駄なトラフィックの回避
- ポートの記憶
- 通信のたびにある MAC アドレスをもつノードがどのポート に接続されているか学習
- 次回の通信時には余分なポートには通信を中継しない。
- ブリッジの動作
- あて先MACアドレスをもとにMACアドレステーブルを参照する
- あて先MACアドレスの接続ポートがフレームを受信したポー トと別ポートであれば,そのポートにフレームを送信し
- 同一ポートであればフレームを破棄する
- あて先MACアドレスが記憶されていない場合やブロードキャス トアドレス(FF-FF-FF-FF-FF-FF)の場合は,受信ポート以外のすべてのポートにフレームを送信する
P.375 スイッチングハブ¶
- レイヤ2スイッチ(L2スイッチ)とも呼ばれる
- データリンク層に位置
- ブリッジと同じ働きをする
- MAC アドレスを認識してフレームのあて先を決めて通信を行います。
- 試験での問われ方
- スイッチングハブはフレームの蓄積機能、速度変換機能や交換機 能をもっている。
- このようなスイッチングハブと同等の機能をもち,同じプロトコル階層で動作する装置はどれか
- 答えは「ブリッジ」
P.375 ブロードキャストストリーム¶
- データリンク層で動作するブリッジやスイッチングハブなどの LANスイッチはブロードキャストフレームを受信ポート以外 のすべてのポートに転送
- これらの機器をループ状に接続し冗長化させると信頼性はあがる
- ブロードキャストフレームは永遠に回り続けながら増える
- 最終的にはネットワークダウンを招く
- この現象をブロードキャストストームという
- ブロードキャストストームを防ぐプロトコル:スパニングツリープロトコル(Spanning Tree Protocol:STP)
- ループを構成している一部のポートを通常運用時にはブロック(論理的に切断)する
- ネットワーク全体をループをもたない論理的なツリー構造にする
P.376 ネットワーク層の接続¶
- 第 3 層(レイヤ 3)
P.376 ルータ¶
- ルータはネットワーク層(第 3 層)に位置する
- あて先IPアドレスを見てパケットの送り先を決め通信を制御する
- IP のローカルネットワークの境界線に設置して利用され,ネットワークの基本単位として機能
- 世界中に散在しているローカルネットワークどうしをルータが結ぶ
- 全体としてインターネットというインフラが機能
- ルータで分けられたネットワークの単位をブロードキャストドメインという
- ルータがパケットを受け取ったあと
- あて先IPアドレスを見る
- 自分のネットワークあてであれば,破棄
- 他のネットワークあてであれば転送
- どのルータへ送ればあて先のネットワークへの通信が速く行えるかを判断することを経路制御(ルーティング)
- ルータはそのための経路表(ルーティングテーブル)を備えている
P.376 デフォルトゲートウェイ¶
- 会社Aのネットワークに属するPCは会社BのPCと直接通信できない
- 会社AのPCは他ネットワークへの接点であるルータAに転送を依頼
- デフォルトゲートウェイ:会社AのPCから見て直近のルータA
- 自分と直接接続していない相手と通信するときはすべてデフォルト ゲートウェイを中継する
P.376 ルーティング¶
- 経路表(ルーティングテーブル)の作成方法
- 手作業で作る:スタティックルーティング
- ルーティングプロトコル利用:ルータ同士が経路情報を交換し、自立的に経路表を作るダイナミックルーティング
- ダイナミックルーティングのための代表的なルーティングプロトコル:RIP、OSPF
- RIP:ディスタンスベクタ型(距離ベクトル型)
- ルーティングテーブルの情報(経路情報)を一定時間間隔で交換しあう
- あて先ネットワークにいたるまでに経由するルータの数(ホップ数)最小経路を選ぶ
- あて先に到達可能な最大ホップ数は 15
- これを超えた経路は採用されない
- OSPF:リンクステート型
- コストを経路選択の要素に取り入れ、コスト最小経路を選ぶ
- コスト値は,回線速度を基に自動的に算出されるが手動設定もできる
- コスト算出式「コスト=100Mbps/経路の通信帯域(bps)」
- コスト計算例は P.377 の図を見ること
P.377 ルータの冗長構成¶
- ルータを冗長構成のために使うプロトコル:VRRP(Virtual Router Redundancy Protocol )
- 同じ LAN に接続された複数のルータを仮想的に 1 台のルータ として見えるようにして冗長構成を実現する
- 複数のルータでグループ(VRRP グループ)を作る
- VRRP グループごとに仮想 IP アドレスと仮想 MAC アドレスを割り当て
- PC などのノードは仮想ルータの IP アドレスに対して通信
- 通常時はグループのマスタルータが仮想ルータの IP アドレス(仮想 IP アドレス)を保持
- マスタルータに障害が発生すると他のバックアップルータがこれを継承
P.377 レイヤ3スイッチ(L3スイッチ)¶
- ルータと同じネットワーク層(第 3 層)の通信機器
- 特徴
- ルータ:ソフトウェアで転送処理
- レイヤ 3 スイッチ:専用ハードウェアで転送処理
- 高速処理できる:大容量のファイルを扱うファイルサーバへのアクセスなど
P.378 トランスポート層以上の層の接続¶
P.378 ゲートウェイ¶
- トランスポート層(第 4 層)-アプリケーション層(第7層)でネットワーク接続するための装置
- 第 3 層のネットワーク層まででエンドツーエンド(E2E)の通信は完成する
- E2E = 通信を行う二者、あるいは、二者間を結ぶ経路全体
- エンドツーエンド原理:高度な通信制御や複雑な機能は末端のシステムが担い、経路上のシステムは単純に信号やデータの中継・転送だけすべし
- TCP/IP ネットワークの原理
- 誤り訂正・フロー制御・再送:TCP 層(第4層、トランスポート層)など上位側の機器やソフトウェア・プロトコル
- 単純な送受信・転送処理:IP 層(第3層、ネットワーク層)
- ゲートウェイ:第 4 層のトランスポート層以上が違う LAN システム相互間のプロトコル・データ形式の変換を担う
- ゲートウェイはアプリケーションプロトコルの内容を 解釈できる
- アプリケーションヘッダの不正な情報混入を検出可能
- ファイアウォール・プロキシサーバもゲートウェイの一種
P.378 L4スイッチ・L7スイッチ¶
- L4スイッチ(レイヤ4スイッチ)はトランスポート層(第4層)の装置
- 定義としてはゲートウェイ
- 機能的にはレイヤ2スイッチ・レイヤ3スイッチの延長上
- ルータやレイヤ3スイッチはIPアドレスを参照して経路制御する
- L4スイッチではTCPポート番号やUDPポート番号も経路制御判断に使える:第4層の機器だから
- L7スイッチ:アプリケーション層(第7層)までの情報を使って通信制御する
P.379 7.2.5 VLAN¶
- VLAN(Virtual LAN:仮想LAN)
- スイッチ(レイヤ2スイッチ,レイヤ3スイッチ)で物理的な接続形態とは独立に仮想的なLANグループを構成する仕組み,あるいはそう構成されたLAN
- 複雑な形態のネットワークを楽に構築できる
- サブネット構成も柔軟に変えられる
P.380 データリンク層の制御とプロトコル¶
- データリンク層:第2層
P.380 7.3.1 メディアアクセス制御¶
- 複数のデータを1つのケーブルを通して送受する場合,データの衝突(コリジョン)を回避するための制御が必要
- これがメディアアクセス制御(Media Access Control:MAC)
コリジョン(衝突)¶
イーサネットや無線LANで複数の端末が送信し、データが衝突する現象を指す。旧式のイーサネット規格では、端末同士を接続するときに1組の通信路で双方向の通信を行う半二重通信のため、送信と受信を同時に行うことができない。送信と受信をその都度切り替えて行うので、端末がお互いデータを送信してしまうと衝突する可能性が高くなる。
P.380 CSMA/CD¶
- CSMA/CD:Carrier Sense Multiple Access with Collision Detection:搬送波感知多重アクセ ス/衝突検出)の略。
- イーサネットで採用されている方式
- 衝突検知方式を採用
- イーサネット:IEEE 802.3として標準化されている LAN規格
- CSMA/CD
- 各ノードは伝送媒体が使用中かどうかを調べて,使用中でなければデータを送りはじめる
- 複数のノードが同時に通信しはじめるとデータの衝突が起こる
- 衝突を検知し,一定時間(ランダム)待った後で,再送
- 一定の距離以上のケーブルでは衝突が検知できない
- CSMA/CD方式の限界
- トラフィックが増加するにつれて衝突が多くなる
- 再送が増え,さらにトラフィックが増加する悪循環に陥る可能性がある
- 特に伝送路の使用率が30%を超えると実用的でなくなる
P.381トークンパッシング方式¶
- トークンによる送信制御を行う方式で
- トークンバス方式
- トークンリング方式
P.381 トークンパッシング方式¶
- ネットワーク上をフリートークンと呼ばれる送信権のためのパケットが巡回する
- フリートークンを獲得したノードだけが送信できるので衝突を避けられる
- ふつうはコンセントレータ(集線器)でネットワ ークとノードを結ぶ
- トークンパッシング方式を採用したLAN規格
- 例:FDDI:Fiber Distributed Data Interface
- FDDIは物理媒体に光ファイバを利用し,最大100Mビ ッ ト/秒の通信
- 特徴
- 伝送媒体上では衝突しない
- トラフィックが増えるにつれてトークンを獲得しにくくなり,少しずつ遅延時間が増える
- 衝突による再送制御の必要がないため伝送路の使用率に対する遅延時間の増加率はCSMA/CD方式より緩やか
P.382 TDMA 方式¶
- TDM(時分割多重)
- ネットワーク上にデータを送信する時間を割 り当てる(タイムスロット)
- タイムスロットごとに別のデータを送って多重化する
- TDM によるアクセス制御が TDMA
- TDMA(Time Division Multiple Access:時分割多重アクセス)
- CSMA/CD・トークンパッシング方式と並ぶ主要なデー タリンク技術
- TDMA ではネットワーク(伝送路)を使える時間を細かく区切る
- 割り当てられた時間は各ノードが独占する方式
- TDMAはコネクション型の通信
P.382 7.3.2 無線LANのアクセス制御方式¶
P.382 CSMA/CA方式¶
- CSMA/CA:Carrier Sense Multiple Access with Collision Avoidance、搬送波感知多重アクセス/衝突回避
- 無線 LAN の制御方式
- CSMA/CD との違い:「衝突検出」が「衝突回避」になった
- 無線 LAN:物理層媒体は電波で衝突の検出は不可能だから回避する
- 特徴
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
- 待ち時間をバックオフ制御時間とよぶ
- 衝突してフレームが壊れても検出できない
- データを受け取ったノードは ACK を返す
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
P.328 RTS/CTS¶
- 無線 LAN の話
- 隠れ端末問題
- 他のノードのデータ送信を感知できないことがある
- 通信ノード間の距離が遠い
- ノード間に障害物がある
- 回避のための RTS/CTS 方式
- 無線 LAN ノード
- データ送信前にRTS(Request ToSend:送信リクエスト)をアクセスポイントに送信
- これを受理したアクセスポイントがCTS(Clear to Send:送信OK)を返信
- 他のノードは CTS を傍受して自分以外の別のノードに送信権があると解釈
- データ送信を延期
- 無線LANノードはアクセスポイントからCTSを受信したらデータ送信開始します
- 衝突抑制:CTSに書かれた他のノードに対する送信抑制時間を使う
- データ送信開始前にデータ送信のネゴシエーシ ョンとして RTS/CTS 方式を使った CSMA/CA を CSMA/CA with RTS/CTS とよぶ
P.383 無線LANの動作モード¶
- 無線 LAN の動作モード:図7.3.4参照
- 2 つのモードがある
- インフラストラクチャモード:無線LANノードがアク セスポイントを通じて相互に通信
- アドホックモード:アクセスポイントなしに無線LANノードどうしが直接通信
P.383 COLUMN FDMA,CDMA¶
- 表7.3.1:多元接続する技術グループ
- TDMA とセット
- FDMA
- ある周波数帯をさらに細かい周波数帯に分割
- 接続できる端末数を増やす技術
- CDMA
- 周波数も時間も分割しない
- 符号で各端末の通信を識別・分離
- 接続できる端末数を増やす
P.383 7.3.3 データリンク層の主なプロトコル¶
- 第 2 層
P.384 ARP¶
- ARP(Address Resolution Protocol):通信相手のIPアドレスからMACアドレスを取るためのプロトコル
- ARPの動作
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- ブロードキャスト:ネットワークに参加するすべての機器に同時に信号やデータを送ること
- 各ノードは自分のIPアドレスと比較
- 一致したノードだけARP応答パケットに自分のMACアドレスを入れて返す(ユニキャスト)
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- 参考:GARP(Gratuitous ARP)
- 主な目的:自身に設定するIPアドレスの重複確認・ARPテ ーブルの更新
- 目的IPアドレスに自身が使うIPアドレスを指定し,MACアドレスを問い合わせる
P.384 RARP¶
- Reverse-ARP:逆アドレス解決プロトコル
- MACアドレスからIPアドレスを取る
- 電源オフ時にIPアドレスを保持できない(IPアドレスを保持するハードディスクをもたない)機器が電源オン時に自分のMACアドレスから自身に割り当てられているIPアドレスを知るために使う
- RARP サーバー
- MACアドレスとIPアドレスの対応表を持ったサーバー(RARPサーバー)が必要
P.384 PPP¶
- PPP:Point to Point Protocol
- 2 点間をポイントツーポイントでつなぐためのデータリンクプロトコル
- WANを介して2つのノードをダイヤルアップ接続するときに使う
- ネットワーク層(第3層)とネゴシエーションする NCP(ネットワーク制御プロトコル)とリンクネゴシエーションするLCP(リンク制御プロトコル)からなる
- NCP:Network Control Protocol
- LCP:Link Control Protocol
- リンク制御やエラー処理機能を持つ
P.384 PPPoE¶
- PPPoE:PPP over Ethernet
- PPPと同等な機能をイーサネット(LAN)上で実現するプロトコル
- PPPフレームをイーサネットフレームでカプセル化して実現
P.384 7.3.4 IEEE 802.3規格¶
- メディアアクセス制御に CSMA/CD 方式を使う LAN についての標準
- OSI基本参照モデルにおけるデータリンク層(第 2 層)と物理層(第 1 層)のプロトコルおよびサービスを規定
- OSI 基本参照モデルでのデータリンク層を LLC 副層と MAC 副層の2つに分割
- 物理層での LAN で使う伝送媒体や MAC 副層でのフレーム構成や衝突検出の仕組みを規定
- ツイストケーブルの企画が表 7.3.2 にまとまっている
P.386 7.4 ネットワーク層のプロトコルと技術¶
- もうやった
P.319 6.5.3 その他の DML 文¶
P.319 INSERT文¶
- 表に行を挿入する:2つ方法がある
- 参考:本の P.319
- 挿入する値をVALUES句で指定する
- 問合せの結果をすべて挿入する
- (DBMS によるかもしれないが)個別INSERTと一括INSERTもある:パフォーマンスでよく問題になる
- 一部の列に対して INSERT
- どの列に対して挿入するのか列名リストで指定
- 省略された列の値はDEFAULT制約があればその既定値、そうでなければNULL値
- NULL はなるべく使うのをやめよう
- DEFAULT は P.322 表 6.6.1
1 2 | |
1 | |
P.319 UPDATE文¶
- 表中のデータを変更
- 列の変更値を直接指定する
- 変更値をCASE式で決める
- 副問合せの結果を変更値にする
- SET句には変更したい列の値を「列名 = 変更値」の形で指定
- 1 つのUPDATE文で複数の列の値を変えるときはカンマ(,)で区切って指定
- WHERE句を省略すると表中のすべての行が変わる
- ふつうはやらない
- WHERE句を指定すれば条件に合った行だけ変わる
1 2 3 4 | |
P.320 DELETE文¶
- 表中の行を削除する
- 表中の全行を削除しても表自体は残る
- 表を削除するのはDROP文
- WHERE句を省略すると表中のすべての行が削除される
- WHERE句を指定するとその条件に一致した行だけを削除できる
P.320 参照関係をもつ表の更新¶
- 関連する2つの表の間に参照制約が設定できる
- 被参照表の主キー(候補キー)にない値を参照表の外部キーに追加できない
- 被参照表の行の削除・変更時に制約が出る:図6.5.10参照
- 参照動作指定:削除・変更時の制約は明示的に指定できる
- 次節のCREATE TABLE文を参照
- REFERENCES句(参照指定)の後に次の構文で指定
参照動作指定 REFERENCES 被参照表(参照する列リスト) ON DELETE 参照動作] [ON UPDATE 参照動作] (*[ ]内は省略可能)
- 指摘できる参照動作:表 6.5.5 の 5つ
- デフォルトは NO ACTION
P.320 補足¶
- 参照制約
- 外部キーの値が被参照表の主キーあるいは主キー以外の候補キーに存在することを保証する制約。
- 関連する2つの表の間に参照制約を設定する目的:データ矛盾を起こすような行の追加や削除・変更を排除するため
- REFERENCES指定:p322-324を参照
- データの整合性を保つための制約
- 一意性制約
- 参照制約
- データ項目のデータ型や桁数に関する形式制約
- データ項目が取り得る値の範囲に関するドメイン制約がある。
P.322 6.6 データ定義言語(DDL)¶
P.322 6.6.1 実表の定義¶
P.322 CREATE TABLE文¶
- 表の定義は CREATE TABLE 文
- 基本構文は P.322 参照
P.322 列制約¶
- 表を構成する列に対する制約
- 参考:表6.6.1
- 一意性制約:同一表内に同じ値が複数存在しないことを保証する制約
- 主キーとなる列には一意性制約とNOT NULL制約を加えたPRIMARY KEY指定
- 主キー以外の候補キーにも一意性制約がある
- 一般にNULL(ナル)値は重複値とは扱われない
- 候補キーにはNULL値を許すUNIQUE指定
- 参照制約:外部キーの値が被参照表に存在することを保証する制約
- 外部キー:REFERENCES指定(参照指定)す。
P.323 表制約¶
- 一意性制約・参照制約・検査制約は表制約(表定義の要素として定義される制約)にもできる
- 列制約:1つの列に対する制約
- 主キーや外部キーが複数列から構成される場合、これを列制約として定義できない
- このときは表制約を使う
P.323 主なデータ型¶
- 一般的な文字型,数値型は覚えておくといい
P.324 実表の定義例¶
- P.324 の社員表と部門表を定義を見てみよう
P.325 6.6.2 ビューの定義¶
P.325 ビューとは¶
- 実表:ディスク装置上にあり実際にデータが格納される表
- ビュー:実表の一部または複数の表から必要な行や属性(列)を取り出してあたかも1つの表 であるかのように見せかけた仮想表
- 利用者から見れば実表と同じ
- データを検索するだけなら制約はあっても同じように操作できる
- ビューのメリット
- あくまでも仮想の表:対象となった元の表(基底表)の列名と別の名前で定義できる
- ビューに定義することで情報を公開
- ビューに定義しないことで情報を非公開にできる
- 元の表に新たな列が追加されても既存のビューには影響がなく再定義する必要がない
- ビューは仮想的な表
- 一般には実体化されずデータ格納領域をとら ない。
- 実表のように実体化されるビューもある:体現ビュー(materialized view)
- 参考
P.325 CREATE VIEW文¶
- ビューの定義:CREATE VIEW文による:詳細は本の P.325
- ビュー:対象となる実表(あるいは他のビュー)からSELECT文で必要データを導出する方法で定義される定義するビューの列名に命名規則はない
- 列数はAS句に続くSELECTで問い合わせた結果の列数と同じでなければならない
- 列名は省略可能:省略した場合はSELECTで問い合わせた結果の列名がそのまま定義される
- ビューに対する参照や更新処理
- ビューの対象となった表(基底表)に対す る参照あるいは更新処理に変換されて実行される
P.326 ビューの定義例¶
- 本の P.326 参照
- 社員表と部門表から社員コードと社員名、その社員が所属する部門名からなる表をビュー「社員表2」
- JOIN して必要なカラムだけ取り出す
P.326 ビューの更新¶
- ビューへの更新処理 ビュー定義を基にビューが参照している表(基底表)への対応する処理に変換されて実行
- 更新のための条件
- 更新にかかる実際の表が更新可能
- 更新される表の列や行が一意に決まる
- 更新できないビューの例
- SELECT句で式、集合関数、DISTINCT を使ったSELECT文で定義されている
- ・GROUP BY句やHAVING句を使ったSELECT文で定義されている
P.327 6.6.3 オブジェクト(表)の処理権限¶
- スキーマに定義された実表やビューはそのスキーマ所有者(作成者)にしか処理権限が与えられない
- 複数の利用者がデータベースを利用できるようにしたければ、スキーマ所有者以外にも処理権限を付与する必要がある
- データベース管理ユーザーは全権を持っていて危険な処理もできてしまう
- できることを制限したユーザーで操作したい
- オブジェクト(表)の処理権限
- 読取(SELECT)権限
- 削除(DELETE)権限
- 挿入(INSERT)権限
- 更新(UPDATE)権限
- cf. スキーマ
- 1つのデータベースの枠組み
- スキーマ内に複数の表やビューを定義できる
P.327 処理権限の付与¶
- 権限の付与:GRANT文による
- GRANTの基本構文は次の通り
1 | |
- 権限指定
- 4 つの処理権限(SELECT,INSERT,UPDATE,DELETE)
- ALL PRIVILEGES(すべて)を指定できる
- 権限を複数付与する場合はカンマ(,)で区切って指定
P.327 処理権限の取消し(変更)¶
- 一度付与された権限を取消し(変更)できる
- 権限の取消しはREVOKE文
- REVOKEの基本構文
1 | |
P.328 6.7 埋込み方式¶
P.328 6.7.1 埋込みSQLの基本事項¶
P.328 静的SQLと動的SQL¶
- 静的 SQL:あらかじめ決められたSQL文をプログラム中に埋込んで実行する方式
- 実際のアプリケーションではあまり見かけない
- 非カーソル処理:データベースの表から1行を取り出すこと
- 次のような SELECT 文
- この
INTOを見たことがない
SELECT 社員名, 年齢 INTO :name, :age FROM 社員表 WHERE 社員コード = '100';
- 動的 SQL:実行する SQL 文がプログラム実行中でな ければ決まらない場合に SQL 文を動的に作成し実行する方式
- 上の社員コードがふつう変わる:それが「動的」。
- この動的な部分に変なコードを埋め込むとまずいというのがセキュリティ問題で、例えば SQL インジェクションの問題。
P.328 ホスト変数¶
- ホスト変数:データベースとプログラムのインタフェースとなる変数
- 埋め込み SQL では SQL を実行すると取り出されたデータをINTO句で指定したホスト変数に格納する
- ホスト変数は通常の変数としてもアクセスできる
- 出力関数で表示
- 入力関数で値を入力してそれをSELECT文の条件としても使える
P.329 6.7.2 カーソル処理とFETCH¶
P.329 カーソル処理¶
- 「SELECT・・・・INTO・・・」形式では,1行のデータしか取り出せない
- (見たことがないのでイメージがつかない)
- 検索結果が複数行の場合は1行ずつ取り出せるカーソル処理を使う
- カーソル処理は SQL 文で問い合わせた結果をあたかも1つのファイルであるかのようにとらえる
- FETCH文でそこから1行ずつ取り出す方式
- 1つのSELECT文に対してカーソルを宣言(定義)
- カーソルのオープンでSELECT文が実行
- カーソルで1行ずつ取り出せる
- FETCH文で繰返し行を取り出して処理
- 終了したらカーソルを閉じる
P.330 FETCHで取り出した行の更新¶
- 参考:図 6.7.2:FETCHで取り出した行の更新処理
- FETCH文で取り出した行を更新あるいは削除する場合,FETCH文のあとに続くUPDATE文やDELETE文のWHERE句 に「WHERE CURRENT OF カーソル名」と指定する。
- (FETCH 文を見たことがないのでイメージつかない)
P.330 処理の確定と取消し¶
- 一連のデータを更新している途中でエラーが出た場合
- それまでの更新処理を取り消して元に戻す必要がある
- 整合性を取らないといけない:いわゆるロールバックが必要
- トランザクションが正常終了したときは「コミット」する:更新処理の確定
P.331 6.8 データベース管理システム¶
P.331 6.8.1 トランザクション管理¶
P.331 トランザクションとは¶
- 複数の利用者が同時にデータベースにアクセスしてもデータが矛盾してはいけない
- この仕組みがトランザクション管理
- トランザクション:データの整合性を取るための SQL 処理の最小単位
- 「回復の単位(Unit of Re-covery)」とも呼ぶ
P.331 ACID 特性¶
- トランザクション処理は原子性・一貫性・隔離性・耐久性の 4 特性が必要
- 厳密な一貫性(完全一貫性)が必要
- トランザクションではそのすべての処理が完了するか(All)、あるいはまったく実行されていない状態か(Nothing)のどちらか一方で終了しなければならない
- これは,COMMIT(正常終了),、ROLLBACK(異常終了)で実現できる
- COMMIT(コミット):更新処理を確定し、データベ ースへの反映を保証する
- ROLLBACK(ロールバック):更新処理をすべて取 消し,トランザクション開始時点の状態へ戻す
- 参考:結果整合性
- 完全一貫性に対する概念
- 分散トランザクションやいわゆる NoSQL で使われる
- 参考:分散トランザクション
- トランザクション管理するべきテーブルが複数のデータベースにまたがっているとき
- すべてのデータベースをロールバックしなければいけない
P.331 表 6.8.1 ACID 特性¶
- 原子性(Atomicity)
- 更新処理トランザクションが正常終了した場合だけデータベースへの反映を保証する
- 異常終了時は処理が何もなかった状態に戻す
- 一貫性(Consistency)
- トランザクションの処理によってデータベース内のデ ータに矛盾が生じないこと
- 常に整合性のある状態が保たれていること
- 隔離性(Isolation)
- 複数のトランザクションを同時(並行)に実行した場合 と,順(直列)に実行した場合の処理結果が一致するこ と
- 独立性ともいう
- トランザクションのスケーリング:複数のトランザクションを同時実行してもそれが正しい順で実行されるように順序づけること
- 基本は並行実行の結果と直列実行の結果が等しくなるように調整する
- ロック:直列可能性を保証する方法
- 耐久性(Durability)
- いったん正常終了したトランザクションの結果はそ の後に障害が発生してもデータベースから消失しないこと
- トランザクションの再実行を必要としないこと
P.332 6.8.2 同時実行制御¶
- 同時実行制御(並行性制御):複数のトランザクションを同時に実行しても矛盾を起こすことなく処理を実行するメカニズム
- 実現する方法:ロック・多版同時実行制御・時刻印アルゴリズム
- 多版同時実行制御に対してロックによる通常の同時実行制御を単版同時実行制御という
P.331 ロック¶
- 複数のトランザクションを同時実行してもその結果はトランザクションを直列実行した結果と同じでなければならない(ACID 特性の隔離性)
- 同時実行制御が行われない環境では結果が変わる場合もある
- 例:図 6.8.1 を見ること
- トランザクションTR1とトランザクションTR2が同じデータaを①→②の順に読み込む
- それぞれのトランザクションでデータaを③→④の順に更
- COMMITした場合トランザクションTR1がデータaを「a+5→10」に更新してもトランザクションTR2が aの値を「a+10→15」に更新してしまう
- トランザクションTR1における更新内容が失われる
- これを変更消失(ロストアップデート)という
- こうした問題を防ぐための対処法
- データベース管理システムではデータaにロック(鍵)をかける
- 咲にデータaをアクセスしたトランザクションの処理が終了するか、あるいはロックが解除されるまでほかのトランザクションを待たせる制御をする
- 参考 ダーティリード:他のトランザクションが更新中のコミットされていないデータを読み込むこと
P.333 デッドロック¶
- P.250 5.2.5 も参考にすること
- デッドロック:複数のデータに対してロックしようとして互いにロックの解除を待ち続けてしまう
- 例:図 6.8.2
- データA、B、Cを専有して処理するトランザクションTR1,TR2,TR3がある
- 各トランザクションは処理の進行に合わせて表に示される順(①→②→③)にデータを専有
- トランザクション終了時に3つの資源を一括して解放
- トランザクションTR1とトランザクションTR2はデッドロックを起こす可能性がある
- 再び図 6.8.2 を見る
- データを専有する順序が等しいトランザションTR1とTR3の間ではデッドロックは起こらない
- 異なる順や逆順でデータを専有するトランザクション間ではデッドロックが起きうる
- デッドロックが起きたときロールバックなどで 1 つのトランザクションを強制的に終了させてデッドロックを解除する
P.334 ロック方式¶
- 2相ロック方式・木規約
- ロック方式
- 第1相:使用するデータすべてにロックをかける
- 第2相:処理後にロックを解除する
- トランザクション内でのロック・解除はそれぞれ1回だけ
- 直列可能性は保証されるがデッドロック発生の可能性は 残る
- 木規約
- データに順番をつけてその順番どおりにロックをかける
- デッドロックが起きず、直列可能性を保証する
- データへの順番づけには木(有向木)を使う
- トランザクションの同時実行性が低くなるため特殊な用途で使う(どんなところで使うのだろう?)
- 参考:有向木
- 方向をもった有向グラフ(の 1 つ)
- データ構造とアルゴリズムを勉強しよう
- データベースは検索の便宜もあってデータ構造とアルゴリズムが大事
P.334 ロックの種類¶
- 占有ロック・共有ロックの 2 モード
- DBMS でトランザクションの同時実行性を高めるため
- 専有ロック
- データ更新するときに使うロック
- データに対するほかのトランザクションからのアクセスは一切禁止
- 共有ロック
- ふつうデータの読取りの際に使用されるロックで
- 参照だけを許可
- 表 6.8.2 参照:2 つのロックモードの組み合わせによる同時実行の可否
- 専有:占有または排他ともいう
- 共有:共用ともいう
- 共有ロックで同時実行性を高める
- 先行トランザクションがロックしたデータを後続トランザクションが参照できる
- 待ちがなくなり同時実行性が高まる
- たいていのシステムでは書き込みよりも読み込みの方が多い
P.335 ロックの粒度¶
- ロックをかける単位:表・ブロック・行
- ブロック:物理的なIOの単位
- ロックの単位をロックの粒度という。
- 粒度が小さければ小さいほど同時実行性があがる代わりにロックの回数が多くなり、ロック制御のためのオーバーヘッドが増える
- 粒度が大きいほどロックの解除待ちが長くなり、同時実行性が下がる
P.336 多版同時実行制御(MVCC:MultiVersion Concurrency Control)¶
- 同時実行性を高めつつ一貫性のあるトランザクシ ョン処理を実現する仕組み
- ふつう専有ロック中(更新中)のデータは参照できない
- 後続トランザクションはロックの解除を待つ
- 多版同時実行制御での対処
- 更新中のデータに対する参照要求に更新前(トランザクション開始前)の内容を返す
- 後続トランザクションを待たずに処理できる
- 専有ロックと共有ロックの同時確保で同時実行性を高める一方で、後続トランザクションには現在からさかのぼったある時点における一貫性のあるデータを提供する
- 整合性を欠いたデータの参照を防げる
参考:整合性を欠いたデータの参照¶
- ダーティリード
- アンリピータブルリード
- 再度読み込んだデータが他のトランザクションで更新されている
- 前回読み込んだ値と一致しない
- フ ァ ン ト ム リ ー ド
- 再度読み込んだデータの中に他のトランザ クションによって追加・削除されたデータがある
- 前回と検索結果が変わる
P.335 時刻印アルゴリズム¶
- ロック制御をせずに同時実行制御を行う方法としての時刻印(タイムスタンプ)アルゴリズム
- トランザクションが発生した時刻 T とデータのもつ読込み時刻 Tr、あるいは書込み時刻 Tw を比較して読み書きを判断する
- 読み込みの場合
- Tw≦T のときだけ読み込む
- 読み取ったあとは読み込み時刻 Tr にトランザクション発生時刻 T を設定
- 書き込みの場合
- Tw≦T かつ Tr≦T のときだけ書き込む
- 書き込み後、書込み時刻 Tw にトランザクション発生時刻Tを設定
- 参考:P.336 図 6.8.4
参考:楽観ロック¶
- 楽観的方式:ロック制御をしない他の方法
- 仮定:同じデータへのアクセス(更新要求)はめったに発生しない
- 処理を進めて更新直前にほかのトランザクションでそのデータが更新されたかどうかを確認する
- 更新された場合はロールバックする
- 実装例
- データベースに「更新回数」のようなカラムを持たせる
- データ取得時に更新回数も送る
- データ更新するときは更新回数つきでサーバーにリクエストを出す
- 更新回数が同じなら更新する
- 更新回数が違うなら更新要求を却下する
- ほぼ同じタイミングで複数の更新要求が出ることはあり、このときは更新が重複して異常が出る
- これが起きない(起きにくい)というのが最初に書いた「同じデータへの更新要求はめったに発生内」という仮定
P.336 障害回復管理¶
P.336 障害の種類¶
- データベースに発生する障害の三大分類
- 媒体障害:記憶媒体の故障でデータが消失
- システム障害:DBMSやOSのバグ・オペレータの誤操作によるシステムダウン
- トランザクション障害:プログラムのバグ・デッドロック発生でのトランザクションの強制終了など、実行中のトランザクションが異常終了
P.336 目標復旧時点¶
- RPO:Recovery Point Objective
- システム再稼働時に障害発生前のどの時点の状態に復旧させるかを示す概念で、データ損失の最大許容範囲
- 目標復旧時間(RTO、Recovery Time Objective)
- 災害による業務の停止が深刻な被害とならないために許容される時間
P.336 事前対策¶
- 障害回復:障害からデータベースを復旧して一貫性が保たれた元の状態に戻すこと
- 障害回復には次のファイルを事前に取得しておく必要がある
- ログファイル
- 障害やバグ対策の基本
- トランザクション処理でデータベースが更新されるとき,更新前ログ、更新後ログなどの更新履歴(変更情報)を取り、時系列に記録する
- ジャーナルファイル、ジャーナルログともいう
- 大量に出るので復旧や原因追及に必要十分な要素をピックアップする必要がある
- ログファイル容量などを見て自動でファイルが切り替わる(ローテーション)
- バックアップファイル
- 媒体障害に備えてデータベースとログファイルを定期的に別の媒体にバックアップ(退避)する
- データベースのバックアップは定期的に取る
- ログファイル切り替え時にログファイルのバックアップも取る
- ふつうn個のログファイルに対してログデータをログファイル1から順に書き込む
- ログファイル1が一杯になるとログファイル2へと切り替える(ローテーション)
- このタイミングでバックアップ
P.337 参考 バックアップの種類¶
- フルバックアップ:すべてのデータをバックアップする
- 差分バックアップ:直前のフルバックアップ からの変更分だけをバックアップする。
- 増分バックアップ:直前のフルバックアップ または増分バックアップからの変更分だけをバックアップする。
- メリット・デメリット
- フルバックアップは何も考えずにドカンと復旧できるが容量を食う
- 差分バックアップはバックアップに使う容量を減らせるが、復旧時に手間がかかる
P.337 媒体障害からの回復¶
- 媒体障害発生時:バックアップファイルとログファイルの更新後ログを使ってロールフォワード処理でデータ ベースを回復させる
- 参考:P.338 図6.8.6
- T1:バックアップファイル取得
- T2:媒体障害発生
- バックアップファイルを別の媒体にリストア、T1時点に復帰
- T1-T2間の更新データ回復:ログファイルの更新後ログによるデータベースの各レコードを順番に再現するロールフォワード処理
- 参考:差分バックアップ方式採用時
- フルバックアップファイルをリストア
- 直近の差分バックアップファイルのデータを追加
- 更新後ログでロールフォワード
P.338 トランザクション障害からの回復¶
- アプリケーションプログラムのバグやデッドロックを解除するための強制終了などでアプリケーションが異常終了したとき
- ログファイルの更新前ログを使ったロールバック処理でデータベースの内容をトランザクション開始時点の状態に戻す
- 参考:P.338 図6.8.7
- データxとyを更新しなければならないトランザクションがT1で開始
- データyの更新を行う前にT2で異常終了
- このままではデータxとyのつじつまが合わない
- T1からT2の間に行われたxの更新を取り消す必要が出る
- ログファイルの更新前ログによるロールバック処理 でトランザクション開始時点(T1)の状態に戻す
- 参考:データとログをメモリ上にバッファリングしている場合
- まだCOMMITされていないトランザクションはログ・バッファの内容で自動的にロールバック(ROLLBACK)される
P.339 システム障害からの回復¶
- 現在のデータベース管理システムでのディスクの入出力効率向上のための工夫
- データとログをメモリ上にバッファリング
- まずデータベース・バッファに対してデータの更新
- ある時間間隔でデータベース・バッファの内容をデータファイル(データベース)へ書き出す
- 書き出し時点を行った時点:チェックポイント
- チェックポイントの発生:トランザクションのCOMMITとは非同期で、トランザクションがCOMMITされてもデータベース・バッファの内容はデータファイルに書き出されない
- チェックポイント発生時、稼働中のトランザクション情報もログファイルに書き出される
ログ・バッファの内容¶
- トランザクションのCOMMITまたはチェックポイント発生でログファイルに書き出される
- システム障害発生時の問題
- データファイルに書き出されていないデータベース・バッファ上の更新データの消失
- P.340 図6.8.9 の TR2
- システム障害が発生した時点でCOMMITされていない
- データベース・バッファの内容が消失しても問題ない:再処理で対応
- 問題になるのはチェックポイント(T1)の前に開始されたTR1
- TR1はシステム再立上げ後に更新前ログを用いたロールバック処理で
- トランザクション開始時点の内容に戻す
図6.8.10の例¶
- チェックポイント(T1)後
- システム障害発生(T2)前にCOMMITされたトランザクションTR3,TR4による更新内容はまだデータファイルに書き出されていない
- システム障害が発生した直前のチェックポイント(T1)まではデータベースの内容が保証されている
- ここから更新後ログを用いてロールフォワード処理によって回復
- システム障害における障害回復はシステム障害 発生時のトランザクションの状態に応じて変わる
- チェックポイントを作ることでそれまで行われてきた更新内容はすべてデータベース・バッファからデータファイルに書き出される
- システム障害が発生してもチェックポイント以降の更新後ログだけでロールフォワード処理で回復できる
- 回復時間が短縮される
P341 6.8.4 問合せ処理の効率化¶
P.341 インデックス¶
- インデックス():データベースへのアクセス効率を上げるために使う
- 例えばデータ構造とアルゴリズムの意味で「木」を作っている
- 一般に検索対象の項目にインデックスをつけるとアクセス(検索)速度はあがる
- しかしシステム全体のパフォーマンスが遅くなることがある
- インデックスをつけるとインデックスの更新が走る
- この処理がどれだけパフォーマンスに影響するかが問題
- インデックスのつけ方はきちんと考える必要がある
- 参考
- 各データに複数の索引語を付けて検索時に具体的な値を与えることで,その値を含むすべてのデータを高速かつ簡単に検索できるように編成
- 蓄積された索引ファイルを転置ファイル(inverted file:インバ ーテッドファイル)という。
P.341 POINT インデックス設定時の留意点¶
- アクセス頻度の高い列(検索でよく使う項目)に張る
- いわゆる内部 ID 系(これは主キーとして勝手にインデックスがつく・つける)
- 更新頻度の多い列に対してインデックスを張らない
- 外部 ID としてのメールアドレス・ログイン ID に張ることは多い
- 行数の少ない表に対してインデックスを張っても効果は低い
- データのとり得る値の種類が少ない(データ値の重複が多い)列に対して張っても効果は低い
- それでも張ることはある
- 「推測するな。計測せよ。」
- データ値の重複に大きな偏りがある場合は効果が低い
- 初期のデータ挿入など多くの行を挿入するときはいったんインデックスを削除するといい
- 参考
- インデックスには重複を許さないユニークインデックスと重複を許 すデュプリケートインデックスがある
- 主キー項目にはユニークインデックスが張られる
P.341 上記POINTの④,⑤について¶
- P.342 表はインデックスを張ったある項目Xの値とその行数
- [例1]と[例2]を比べる
- データのとり得る種類は両方とも同じ
- [例2]のほうが重複の程度が平準
- [例1]のほうが大きく偏っている
- インデックスで1項目当たりの平均の検索効率の向上が期待できるのは[例2]
- ただしあくまで一般論
P.342 例1・例2の検索効率を確率的に考える¶
- [例1]の場合
- 検索条件が「項目X=A」である確率は(20/1200)
- Aの検索はインデックスが使える
- 目的のデータを検索するにはさらに20件を順次検索する必要が ある
- このときの最大比較回数は20
- 「項目X=B」の場合、1項目当たりの検索効率(期待値)は次の式で求められる
- (20/1,200)×20+(40/1,200)×40+(80/1,200)×80 +(160/1,200)×160+(300/1,200)×300+(600/1,200)×600=403
- [例2]の場合
- 1項目当たりの検索効率(期待値)は(200/1,200)×200×6=200
- 確率的意味からも[例2]のほうが検索効率がいい
- 参考
- 効率を下げる重複が多い値で検索する機会がほとんどない場合、実際の効率は例1の方が大きい可能性がある
- いつでも実際のケースでどうかを考える必要がある
- 参考
- インデックスを張った項目を検索条件にして絞り込んだ選択率が10〜20%を大きく超える場合,インデックスの効果はあまり期待できない
P.343 連結インデックス¶
TODO
2021-01-31 課題¶
- 先に進む前に録画してあるか確認しよう
進捗¶
- 前回の進捗
- 基礎知識編:P.326 ビューの更新
- 本編:04-02「よくある条件付き確率密度関数(確率分布)」まで
- 今回の進捗
- 基礎知識編:「参考:楽観ロック」まで
- 本編:04-02終了
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 勉強の日常組み込み系
- Julia:The Little Book of Julia Algorithmsを読んでみることにしました。適当に話します。
- そのうち取り組む事案:黒木さんの Julia での統計ネタ
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
TODO¶
- AWS のハンズオン
- 公式のハンズオン: 無料でできるハンズオンもたくさんある
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- 実際に競プロの問題をいくつか解いてみましょう。
Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
日々の勉強¶
Julia¶
- The Little Book of Julia Algorithms
- リポジトリの対象ディレクトリ:ここ
- その他参考
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- ネットワークの話もいい加減飽きたので、しばらく DB の話
復習¶
- 3 つのスキーマ
- ユーザーが見るレベル
- 正規化などをかけておいたデータベースにもっていけるレベル
- 個々のデータベースに合わせた具体的なレベル
- インメモリの DB:コンピューターの基本的なハードウェア構成と意味を復習しよう
本の記述を追いかける¶
P.408 7.8 交換方式¶
P.408 パケット交換方式¶
- 回線交換方式と対になる概念
- 回線交換方式:通信を行うノード間で物理的な通信路を確保してから通信する
- 例:電話
- パケット交換方式について
- データ送信するノードはデータをパケットに区切る。
- ひとつひとつのパケットにヘッダを付けて送信。
- ネットワーク内ではパケット交換機にパケットがたまる
- ネットワークの状況に応じて順次送られる
パケット通信のメリット・デメリット¶
メリット¶
耐障害性 - 通信路を固定しないため,迂回経路が取れる。 - パケット交換機にデータが蓄積されているため,復旧まで待てる。 - パケット多重 - 1 対 1 の通信で回線を占有する必要がないため,1つの回線を多くのノードで共有でき,回線を効率的につかえる - 異機種間接続性 - パケット交換機で中継するときにプロトコル変換・速度変換でエンドノードどうしが同じプロトコルをサポートしていなくても通信できる
デメリット¶
- ネットワーク内の蓄積交換処理による遅延
- 蓄積交換処理による遅延解消のために主に回線の帯域を広げることで対応してきた
- 構造上,完全には遅延をなくせない
- パケット到着順序の不整合
P.408 ATM 交換方式¶
- ATM(Asynchronous Transfer Mode:非同期転送モード)
- 遅延のない回線交換方式とパケット交換方式の利点を得たい
- パケット交換方式の発展
- 遅延の原因をつぶす:特にパケットの多様性
- 多種多様なパケットに対応するために,パケット交換機はソフトウェア処理が必要 ^ ATM での工夫の一例:最も特徴的なのは,パケット(ATMではセルという)の長さをヘッダ部 5 バイト,ペイロード 48 バイトの53バイトに統一
- パケット解析がハードウェアだけでできる。
- ソフトウェアは不要になった。
- Wikipedia から
- 当初の意図に反して非常に複雑な技術になってしまった
- ATM は次世代の主流にならず限定的な使用にとどまった
- ATM の設計思想は MPLS へと引き継がれた
- 汎用のレイヤ 2 のパケットスイッチングのプロトコルとして、ルーターを介したIPの通信網で利用されている。
P.408 ペイロード(payload)¶
- データ通信で本来転送したいデータ本体の部分、ボディを指す。
- ATM ではペイロードのサイズを固定して処理を簡素化
- 難点:パケット全体に占めるペイロードのサイズが相対的に小さくオーバヘッドが大きい
P.410 輻輳¶
- フレームリレー:パケット交換方式の一種
- 1 つの回線を多数のユーザで共有。
- 回線がもつ潜在的な伝送能力(ワイヤスピード)を十分に引き出すうえで効果がある
- 輻輳:ユーザの利用が一時期に集中すると,ワイヤスピードを超えるパケットがネットワーク上に流れる
- ネットワークが輻輳状態になるとスループットが落ちる
- フレームリレーサービスを提供する事業者は,ネットワークが輻輳状態に陥ってスループットが低下しても最低限保証する通信速度を決めている
- CIR(Committed Information Rate:認定情 報速度)
P.370 7 ネットワーク¶
- 確か 7.4 から始めた気がするので 7 章はじめから
P.370 7.1.1 OSI基本参照モデル¶
- 改めて復習
- OSI(Open System Interconnection)基本参照モデル- 異なる設計思想・世代のシステムと円滑に通信するのが目的に標準化
- プロトコルの単機能化,交換の容易さが目的
- 階層化のおかげで一部の階層の技術体系が変わっても、その階層だけ取り替えればいい
- コスト・リスクを小さくする
P.370 プロトコルとサービス¶
- N 層:それぞれの階層のこと
- エンティティ:N 層に存在する通信機器などの実体
- この言葉はいろいろなところで出てきていろいろな意味で使われる
- もちろん気分的には適当な実体を指すことが多い
- プロトコル:N 層に属するエンティティが通信するための取り決め
- 上位の層が下位の層を利用しながら通信する
- 別の階層間のエンティティどうしが通信する窓口が必要
- これを提供するのが下位層:この機能をサービスと呼ぶ
- プロトコルに沿った仕様で製品を開発すれば別のベンダの機器でも通信できる
- 参考:ベンダーロックイン
特定ベンダー(メーカー)の独自技術に大きく依存した製品、サービス、システム等を採用した際に、他ベンダーの提供する同種の製品、サービス、システム等への乗り換えが困難になる現象のこと。
出来上がった情報システムの正確な仕様が、システムを開発・構築したベンダーにしか解らなくなる場合がある。結果、システムの保守・拡張・改修等の際、現存システムを開発・構築したベンダーに引き続き発注せざるを得なくなる。
- 「Excel で行政に提出する書類を作れ」事案もそれ。
- Apple 製品で身の回りを固めるのも同じ。
- 「多様性が大事」事案でもある。
7.1.2 TCP/IPプロトコルスイート¶
- プロトコル同士には相性がある
- 「ネットワーク層がこのプロトコルならトランスポート層はこのプロトコルにしておくとトラブルが少ない」
- 一般に同じ団体が作ったプロトコルはセットで使われることが多い
- このセットがプロトコルスイート ^ 最も代表的なのは IP を中心に組まれた TCP/IP プロトコルスイート
- 独自の階層モデルをもつ
P.372 TCP/IPの通信¶
- データをパケットに区切る
- 各パケットにヘッダを付けて送信
- ヘッダは各階層ごとに付加されて次の階層へと渡される
- 各ヘッダにはその階層で必要となる送信元や送信先,大きさ,順番などパケット自体に関する情報を含む
- TCPヘッダを付加したパケット:TCP セグメント
- IP ヘッダを付加したパケット:IP パケット
- MACヘッダを付加したパケット:MAC フレームあるいはイーサネットフレーム
P.372 MAC(Media Access Control)アドレス¶
- イーサネットや FDDI で使用される物理アドレス
- イーサネット (Ethernet):コンピューターネットワークの規格の1つ。オフィスや家庭で一般的に使用されている有線LAN (Local Area Network) の技術規格
- FDDI:LAN でデータ転送を行うための標準の一つ
- Fiber distributed data interface
- データリンク層
- 同じネットワークに接続された隣接ノード間の通信で相手を識別するために使う
- MACアドレスの長さ:6バイト
- 先頭24ビットの OUI(ベンダID)
- 後続24ビットの固有製造番号(製品に割り当てた番号)
- MAC アドレスは機器が固有にもつ番号
- 必ず一意に定まるように IEEE が管理
P372 ポート番号¶
- トランスポート層にでノード内のアプリケーションの識別に使う識別子番号
- 0-65535の範囲
- TCP/IPではパケット交換方式でデータをやり取りする
- よく使われるアプリケーションについてのポート番号は Well-Known ポートとして標準化
- TCP・UDPそれぞれで 0-1023 番までの番号を割り当てている
- SSH:TCP22番
- Telnet:TCP23番
- SMTP:TCP25番
- HTTP:TCP80番
- POP3:TCP110番
- IMAP4:TCP143番
- HTTPS :TCP443番
- NTP:UDP123番
- SNMP:UDP161番
- SNMP Trap :UDP162番
- セキュリティ対策のために標準とはポート番号を変えることもある
- Web 開発の本を読んでいると、いろいろな都合から http のポートを 80 以外にしていることもよくある。
- 80 の場合はポートを指定しなくてもいい
- 例:http://localhost/hoge/fuga
- 例:http://localhost:5000/hoge/fuga
- 80 の場合はポートを指定しなくてもいい
P.373 ネットワーク間の通信¶
- 同じネットワークに接続されたノード間はデータリンク層(第 2 層)の通信
- ネットワークを超えたノード間はネットワーク層(第 3 層)の通信 -実際に図 7.1.4 を見よう
- どこが IP アドレスでのやりとりか?
- どこが MAC アドレスでのやり取りか?
P.374 7.2 ネットワーク接続装置と関連技術¶
P.374 7.2.1 物理層の接続¶
P.374 リピータ¶
- ネットワーク上を流れる電流の増幅装置・整流装置
- 物理層:第 1 層
- データ通信はネットワーク上を流れる電流
- ケーブルが長いと電流が減衰・波形が乱れが起きる
- データが読み取れなくなる
- これを増幅するのがリピータ
- 大昔の電話は距離が遠いと音が小さく聞こえにくかった
- まさにこの減衰が問題
- リピータは 1:1 で繋ぐ
- 現在では複数のノードを接続できるマルチポートリピータ(ハブ)が使われるのが一般的
P.374 7.2.2 データリンク層の接続¶
- 第2層
P374 ブリッジ¶
- データリンク層に位置
- ネットワーク上を流れているフレーム(情報の単位)の MAC アドレスを認識して通信を中継する
- 接続されているノードをコリジョンドメイン(セグメント)という単位に分割
- MAC アドレスで判定したフレームのあて先のあるセグメントだけにフレームを送信
- 無駄なトラフィックの回避
- ポートの記憶
- 通信のたびにある MAC アドレスをもつノードがどのポート に接続されているか学習
- 次回の通信時には余分なポートには通信を中継しない。
- ブリッジの動作
- あて先MACアドレスをもとにMACアドレステーブルを参照する
- あて先MACアドレスの接続ポートがフレームを受信したポー トと別ポートであれば,そのポートにフレームを送信し
- 同一ポートであればフレームを破棄する
- あて先MACアドレスが記憶されていない場合やブロードキャス トアドレス(FF-FF-FF-FF-FF-FF)の場合は,受信ポート以外のすべてのポートにフレームを送信する
P.375 スイッチングハブ¶
- レイヤ2スイッチ(L2スイッチ)とも呼ばれる
- データリンク層に位置
- ブリッジと同じ働きをする
- MAC アドレスを認識してフレームのあて先を決めて通信を行います。
- 試験での問われ方
- スイッチングハブはフレームの蓄積機能、速度変換機能や交換機 能をもっている。
- このようなスイッチングハブと同等の機能をもち,同じプロトコル階層で動作する装置はどれか
- 答えは「ブリッジ」
P.375 ブロードキャストストリーム¶
- データリンク層で動作するブリッジやスイッチングハブなどの LANスイッチはブロードキャストフレームを受信ポート以外 のすべてのポートに転送
- これらの機器をループ状に接続し冗長化させると信頼性はあがる
- ブロードキャストフレームは永遠に回り続けながら増える
- 最終的にはネットワークダウンを招く
- この現象をブロードキャストストームという
- ブロードキャストストームを防ぐプロトコル:スパニングツリープロトコル(Spanning Tree Protocol:STP)
- ループを構成している一部のポートを通常運用時にはブロック(論理的に切断)する
- ネットワーク全体をループをもたない論理的なツリー構造にする
P.376 ネットワーク層の接続¶
- 第 3 層(レイヤ 3)
P.376 ルータ¶
- ルータはネットワーク層(第 3 層)に位置する
- あて先IPアドレスを見てパケットの送り先を決め通信を制御する
- IP のローカルネットワークの境界線に設置して利用され,ネットワークの基本単位として機能
- 世界中に散在しているローカルネットワークどうしをルータが結ぶ
- 全体としてインターネットというインフラが機能
- ルータで分けられたネットワークの単位をブロードキャストドメインという
- ルータがパケットを受け取ったあと
- あて先IPアドレスを見る
- 自分のネットワークあてであれば,破棄
- 他のネットワークあてであれば転送
- どのルータへ送ればあて先のネットワークへの通信が速く行えるかを判断することを経路制御(ルーティング)
- ルータはそのための経路表(ルーティングテーブル)を備えている
P.376 デフォルトゲートウェイ¶
- 会社Aのネットワークに属するPCは会社BのPCと直接通信できない
- 会社AのPCは他ネットワークへの接点であるルータAに転送を依頼
- デフォルトゲートウェイ:会社AのPCから見て直近のルータA
- 自分と直接接続していない相手と通信するときはすべてデフォルト ゲートウェイを中継する
P.376 ルーティング¶
- 経路表(ルーティングテーブル)の作成方法
- 手作業で作る:スタティックルーティング
- ルーティングプロトコル利用:ルータ同士が経路情報を交換し、自立的に経路表を作るダイナミックルーティング
- ダイナミックルーティングのための代表的なルーティングプロトコル:RIP、OSPF
- RIP:ディスタンスベクタ型(距離ベクトル型)
- ルーティングテーブルの情報(経路情報)を一定時間間隔で交換しあう
- あて先ネットワークにいたるまでに経由するルータの数(ホップ数)最小経路を選ぶ
- あて先に到達可能な最大ホップ数は 15
- これを超えた経路は採用されない
- OSPF:リンクステート型
- コストを経路選択の要素に取り入れ、コスト最小経路を選ぶ
- コスト値は,回線速度を基に自動的に算出されるが手動設定もできる
- コスト算出式「コスト=100Mbps/経路の通信帯域(bps)」
- コスト計算例は P.377 の図を見ること
P.377 ルータの冗長構成¶
- ルータを冗長構成のために使うプロトコル:VRRP(Virtual Router Redundancy Protocol )
- 同じ LAN に接続された複数のルータを仮想的に 1 台のルータ として見えるようにして冗長構成を実現する
- 複数のルータでグループ(VRRP グループ)を作る
- VRRP グループごとに仮想 IP アドレスと仮想 MAC アドレスを割り当て
- PC などのノードは仮想ルータの IP アドレスに対して通信
- 通常時はグループのマスタルータが仮想ルータの IP アドレス(仮想 IP アドレス)を保持
- マスタルータに障害が発生すると他のバックアップルータがこれを継承
P.377 レイヤ3スイッチ(L3スイッチ)¶
- ルータと同じネットワーク層(第 3 層)の通信機器
- 特徴
- ルータ:ソフトウェアで転送処理
- レイヤ 3 スイッチ:専用ハードウェアで転送処理
- 高速処理できる:大容量のファイルを扱うファイルサーバへのアクセスなど
P.378 トランスポート層以上の層の接続¶
P.378 ゲートウェイ¶
- トランスポート層(第 4 層)-アプリケーション層(第7層)でネットワーク接続するための装置
- 第 3 層のネットワーク層まででエンドツーエンド(E2E)の通信は完成する
- E2E = 通信を行う二者、あるいは、二者間を結ぶ経路全体
- エンドツーエンド原理:高度な通信制御や複雑な機能は末端のシステムが担い、経路上のシステムは単純に信号やデータの中継・転送だけすべし
- TCP/IP ネットワークの原理
- 誤り訂正・フロー制御・再送:TCP 層(第4層、トランスポート層)など上位側の機器やソフトウェア・プロトコル
- 単純な送受信・転送処理:IP 層(第3層、ネットワーク層)
- ゲートウェイ:第 4 層のトランスポート層以上が違う LAN システム相互間のプロトコル・データ形式の変換を担う
- ゲートウェイはアプリケーションプロトコルの内容を 解釈できる
- アプリケーションヘッダの不正な情報混入を検出可能
- ファイアウォール・プロキシサーバもゲートウェイの一種
P.378 L4スイッチ・L7スイッチ¶
- L4スイッチ(レイヤ4スイッチ)はトランスポート層(第4層)の装置
- 定義としてはゲートウェイ
- 機能的にはレイヤ2スイッチ・レイヤ3スイッチの延長上
- ルータやレイヤ3スイッチはIPアドレスを参照して経路制御する
- L4スイッチではTCPポート番号やUDPポート番号も経路制御判断に使える:第4層の機器だから
- L7スイッチ:アプリケーション層(第7層)までの情報を使って通信制御する
P.379 7.2.5 VLAN¶
- VLAN(Virtual LAN:仮想LAN)
- スイッチ(レイヤ2スイッチ,レイヤ3スイッチ)で物理的な接続形態とは独立に仮想的なLANグループを構成する仕組み,あるいはそう構成されたLAN
- 複雑な形態のネットワークを楽に構築できる
- サブネット構成も柔軟に変えられる
P.380 データリンク層の制御とプロトコル¶
- データリンク層:第2層
P.380 7.3.1 メディアアクセス制御¶
- 複数のデータを1つのケーブルを通して送受する場合,データの衝突(コリジョン)を回避するための制御が必要
- これがメディアアクセス制御(Media Access Control:MAC)
コリジョン(衝突)¶
イーサネットや無線LANで複数の端末が送信し、データが衝突する現象を指す。旧式のイーサネット規格では、端末同士を接続するときに1組の通信路で双方向の通信を行う半二重通信のため、送信と受信を同時に行うことができない。送信と受信をその都度切り替えて行うので、端末がお互いデータを送信してしまうと衝突する可能性が高くなる。
P.380 CSMA/CD¶
- CSMA/CD:Carrier Sense Multiple Access with Collision Detection:搬送波感知多重アクセ ス/衝突検出)の略。
- イーサネットで採用されている方式
- 衝突検知方式を採用
- イーサネット:IEEE 802.3として標準化されている LAN規格
- CSMA/CD
- 各ノードは伝送媒体が使用中かどうかを調べて,使用中でなければデータを送りはじめる
- 複数のノードが同時に通信しはじめるとデータの衝突が起こる
- 衝突を検知し,一定時間(ランダム)待った後で,再送
- 一定の距離以上のケーブルでは衝突が検知できない
- CSMA/CD方式の限界
- トラフィックが増加するにつれて衝突が多くなる
- 再送が増え,さらにトラフィックが増加する悪循環に陥る可能性がある
- 特に伝送路の使用率が30%を超えると実用的でなくなる
P.381トークンパッシング方式¶
- トークンによる送信制御を行う方式で
- トークンバス方式
- トークンリング方式
P.381 トークンパッシング方式¶
- ネットワーク上をフリートークンと呼ばれる送信権のためのパケットが巡回する
- フリートークンを獲得したノードだけが送信できるので衝突を避けられる
- ふつうはコンセントレータ(集線器)でネットワ ークとノードを結ぶ
- トークンパッシング方式を採用したLAN規格
- 例:FDDI:Fiber Distributed Data Interface
- FDDIは物理媒体に光ファイバを利用し,最大100Mビ ッ ト/秒の通信
- 特徴
- 伝送媒体上では衝突しない
- トラフィックが増えるにつれてトークンを獲得しにくくなり,少しずつ遅延時間が増える
- 衝突による再送制御の必要がないため伝送路の使用率に対する遅延時間の増加率はCSMA/CD方式より緩やか
P.382 TDMA 方式¶
- TDM(時分割多重)
- ネットワーク上にデータを送信する時間を割 り当てる(タイムスロット)
- タイムスロットごとに別のデータを送って多重化する
- TDM によるアクセス制御が TDMA
- TDMA(Time Division Multiple Access:時分割多重アクセス)
- CSMA/CD・トークンパッシング方式と並ぶ主要なデー タリンク技術
- TDMA ではネットワーク(伝送路)を使える時間を細かく区切る
- 割り当てられた時間は各ノードが独占する方式
- TDMAはコネクション型の通信
P.382 7.3.2 無線LANのアクセス制御方式¶
P.382 CSMA/CA方式¶
- CSMA/CA:Carrier Sense Multiple Access with Collision Avoidance、搬送波感知多重アクセス/衝突回避
- 無線 LAN の制御方式
- CSMA/CD との違い:「衝突検出」が「衝突回避」になった
- 無線 LAN:物理層媒体は電波で衝突の検出は不可能だから回避する
- 特徴
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
- 待ち時間をバックオフ制御時間とよぶ
- 衝突してフレームが壊れても検出できない
- データを受け取ったノードは ACK を返す
- 送信ノードは使いたい周波数帯の使えるか確認後、必ずランダムな時間だけ待ってから送信をはじめる
P.328 RTS/CTS¶
- 無線 LAN の話
- 隠れ端末問題
- 他のノードのデータ送信を感知できないことがある
- 通信ノード間の距離が遠い
- ノード間に障害物がある
- 回避のための RTS/CTS 方式
- 無線 LAN ノード
- データ送信前にRTS(Request ToSend:送信リクエスト)をアクセスポイントに送信
- これを受理したアクセスポイントがCTS(Clear to Send:送信OK)を返信
- 他のノードは CTS を傍受して自分以外の別のノードに送信権があると解釈
- データ送信を延期
- 無線LANノードはアクセスポイントからCTSを受信したらデータ送信開始します
- 衝突抑制:CTSに書かれた他のノードに対する送信抑制時間を使う
- データ送信開始前にデータ送信のネゴシエーシ ョンとして RTS/CTS 方式を使った CSMA/CA を CSMA/CA with RTS/CTS とよぶ
P.383 無線LANの動作モード¶
- 無線 LAN の動作モード:図7.3.4参照
- 2 つのモードがある
- インフラストラクチャモード:無線LANノードがアク セスポイントを通じて相互に通信
- アドホックモード:アクセスポイントなしに無線LANノードどうしが直接通信
P.383 COLUMN FDMA,CDMA¶
- 表7.3.1:多元接続する技術グループ
- TDMA とセット
- FDMA
- ある周波数帯をさらに細かい周波数帯に分割
- 接続できる端末数を増やす技術
- CDMA
- 周波数も時間も分割しない
- 符号で各端末の通信を識別・分離
- 接続できる端末数を増やす
P.383 7.3.3 データリンク層の主なプロトコル¶
- 第 2 層
P.384 ARP¶
- ARP(Address Resolution Protocol):通信相手のIPアドレスからMACアドレスを取るためのプロトコル
- ARPの動作
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- ブロードキャスト:ネットワークに参加するすべての機器に同時に信号やデータを送ること
- 各ノードは自分のIPアドレスと比較
- 一致したノードだけARP応答パケットに自分のMACアドレスを入れて返す(ユニキャスト)
- ブロードキャストで目的IPアドレスを指定したARP要求パケットをLAN全体に流す
- 参考:GARP(Gratuitous ARP)
- 主な目的:自身に設定するIPアドレスの重複確認・ARPテ ーブルの更新
- 目的IPアドレスに自身が使うIPアドレスを指定し,MACアドレスを問い合わせる
P.384 RARP¶
- Reverse-ARP:逆アドレス解決プロトコル
- MACアドレスからIPアドレスを取る
- 電源オフ時にIPアドレスを保持できない(IPアドレスを保持するハードディスクをもたない)機器が電源オン時に自分のMACアドレスから自身に割り当てられているIPアドレスを知るために使う
- RARP サーバー
- MACアドレスとIPアドレスの対応表を持ったサーバー(RARPサーバー)が必要
P.384 PPP¶
- PPP:Point to Point Protocol
- 2 点間をポイントツーポイントでつなぐためのデータリンクプロトコル
- WANを介して2つのノードをダイヤルアップ接続するときに使う
- ネットワーク層(第3層)とネゴシエーションする NCP(ネットワーク制御プロトコル)とリンクネゴシエーションするLCP(リンク制御プロトコル)からなる
- NCP:Network Control Protocol
- LCP:Link Control Protocol
- リンク制御やエラー処理機能を持つ
P.384 PPPoE¶
- PPPoE:PPP over Ethernet
- PPPと同等な機能をイーサネット(LAN)上で実現するプロトコル
- PPPフレームをイーサネットフレームでカプセル化して実現
P.384 7.3.4 IEEE 802.3規格¶
- メディアアクセス制御に CSMA/CD 方式を使う LAN についての標準
- OSI基本参照モデルにおけるデータリンク層(第 2 層)と物理層(第 1 層)のプロトコルおよびサービスを規定
- OSI 基本参照モデルでのデータリンク層を LLC 副層と MAC 副層の2つに分割
- 物理層での LAN で使う伝送媒体や MAC 副層でのフレーム構成や衝突検出の仕組みを規定
- ツイストケーブルの企画が表 7.3.2 にまとまっている
P.386 7.4 ネットワーク層のプロトコルと技術¶
- もうやった
P.327 6.6.3 オブジェクト(表)の処理権限¶
- スキーマに定義された実表やビューはそのスキーマ所有者(作成者)にしか処理権限が与えられない
- 複数の利用者がデータベースを利用できるようにしたければ、スキーマ所有者以外にも処理権限を付与する必要がある
- データベース管理ユーザーは全権を持っていて危険な処理もできてしまう
- できることを制限したユーザーで操作したい
- オブジェクト(表)の処理権限
- 読取(SELECT)権限
- 削除(DELETE)権限
- 挿入(INSERT)権限
- 更新(UPDATE)権限
- cf. スキーマ
- 1つのデータベースの枠組み
- スキーマ内に複数の表やビューを定義できる
P.327 処理権限の付与¶
- 権限の付与:GRANT文による
- GRANTの基本構文は次の通り
1 | |
- 権限指定
- 4 つの処理権限(SELECT,INSERT,UPDATE,DELETE)
- ALL PRIVILEGES(すべて)を指定できる
- 権限を複数付与する場合はカンマ(,)で区切って指定
P.327 処理権限の取消し(変更)¶
- 一度付与された権限を取消し(変更)できる
- 権限の取消しはREVOKE文
- REVOKEの基本構文
1 | |
P.328 6.7 埋込み方式¶
P.328 6.7.1 埋込みSQLの基本事項¶
P.328 静的SQLと動的SQL¶
- 静的 SQL:あらかじめ決められたSQL文をプログラム中に埋込んで実行する方式
- 実際のアプリケーションではあまり見かけない
- 非カーソル処理:データベースの表から1行を取り出すこと
- 次のような SELECT 文
- この
INTOを見たことがない
SELECT 社員名, 年齢 INTO :name, :age FROM 社員表 WHERE 社員コード = '100';
- 動的 SQL:実行する SQL 文がプログラム実行中でな ければ決まらない場合に SQL 文を動的に作成し実行する方式
- 上の社員コードがふつう変わる:それが「動的」。
- この動的な部分に変なコードを埋め込むとまずいというのがセキュリティ問題で、例えば SQL インジェクションの問題。
P.328 ホスト変数¶
- ホスト変数:データベースとプログラムのインタフェースとなる変数
- 埋め込み SQL では SQL を実行すると取り出されたデータをINTO句で指定したホスト変数に格納する
- ホスト変数は通常の変数としてもアクセスできる
- 出力関数で表示
- 入力関数で値を入力してそれをSELECT文の条件としても使える
P.329 6.7.2 カーソル処理とFETCH¶
P.329 カーソル処理¶
- 「SELECT・・・・INTO・・・」形式では,1行のデータしか取り出せない
- (見たことがないのでイメージがつかない)
- 検索結果が複数行の場合は1行ずつ取り出せるカーソル処理を使う
- カーソル処理は SQL 文で問い合わせた結果をあたかも1つのファイルであるかのようにとらえる
- FETCH文でそこから1行ずつ取り出す方式
- 1つのSELECT文に対してカーソルを宣言(定義)
- カーソルのオープンでSELECT文が実行
- カーソルで1行ずつ取り出せる
- FETCH文で繰返し行を取り出して処理
- 終了したらカーソルを閉じる
P.330 FETCHで取り出した行の更新¶
- 参考:図 6.7.2:FETCHで取り出した行の更新処理
- FETCH文で取り出した行を更新あるいは削除する場合,FETCH文のあとに続くUPDATE文やDELETE文のWHERE句 に「WHERE CURRENT OF カーソル名」と指定する。
- (FETCH 文を見たことがないのでイメージつかない)
P.330 処理の確定と取消し¶
- 一連のデータを更新している途中でエラーが出た場合
- それまでの更新処理を取り消して元に戻す必要がある
- 整合性を取らないといけない:いわゆるロールバックが必要
- トランザクションが正常終了したときは「コミット」する:更新処理の確定
P.331 6.8 データベース管理システム¶
P.331 6.8.1 トランザクション管理¶
P.331 トランザクションとは¶
- 複数の利用者が同時にデータベースにアクセスしてもデータが矛盾してはいけない
- この仕組みがトランザクション管理
- トランザクション:データの整合性を取るための SQL 処理の最小単位
- 「回復の単位(Unit of Re-covery)」とも呼ぶ
P.331 ACID 特性¶
- トランザクション処理は原子性・一貫性・隔離性・耐久性の 4 特性が必要
- 厳密な一貫性(完全一貫性)が必要
- トランザクションではそのすべての処理が完了するか(All)、あるいはまったく実行されていない状態か(Nothing)のどちらか一方で終了しなければならない
- これは,COMMIT(正常終了),、ROLLBACK(異常終了)で実現できる
- COMMIT(コミット):更新処理を確定し、データベ ースへの反映を保証する
- ROLLBACK(ロールバック):更新処理をすべて取 消し,トランザクション開始時点の状態へ戻す
- 参考:結果整合性
- 完全一貫性に対する概念
- 分散トランザクションやいわゆる NoSQL で使われる
- 参考:分散トランザクション
- トランザクション管理するべきテーブルが複数のデータベースにまたがっているとき
- すべてのデータベースをロールバックしなければいけない
P.331 表 6.8.1 ACID 特性¶
- 原子性(Atomicity)
- 更新処理トランザクションが正常終了した場合だけデータベースへの反映を保証する
- 異常終了時は処理が何もなかった状態に戻す
- 一貫性(Consistency)
- トランザクションの処理によってデータベース内のデ ータに矛盾が生じないこと
- 常に整合性のある状態が保たれていること
- 隔離性(Isolation)
- 複数のトランザクションを同時(並行)に実行した場合 と,順(直列)に実行した場合の処理結果が一致するこ と
- 独立性ともいう
- トランザクションのスケーリング:複数のトランザクションを同時実行してもそれが正しい順で実行されるように順序づけること
- 基本は並行実行の結果と直列実行の結果が等しくなるように調整する
- ロック:直列可能性を保証する方法
- 耐久性(Durability)
- いったん正常終了したトランザクションの結果はそ の後に障害が発生してもデータベースから消失しないこと
- トランザクションの再実行を必要としないこと
P.332 6.8.2 同時実行制御¶
- 同時実行制御(並行性制御):複数のトランザクションを同時に実行しても矛盾を起こすことなく処理を実行するメカニズム
- 実現する方法:ロック・多版同時実行制御・時刻印アルゴリズム
- 多版同時実行制御に対してロックによる通常の同時実行制御を単版同時実行制御という
P.331 ロック¶
- 複数のトランザクションを同時実行してもその結果はトランザクションを直列実行した結果と同じでなければならない(ACID 特性の隔離性)
- 同時実行制御が行われない環境では結果が変わる場合もある
- 例:図 6.8.1 を見ること
- トランザクションTR1とトランザクションTR2が同じデータaを①→②の順に読み込む
- それぞれのトランザクションでデータaを③→④の順に更
- COMMITした場合トランザクションTR1がデータaを「a+5→10」に更新してもトランザクションTR2が aの値を「a+10→15」に更新してしまう
- トランザクションTR1における更新内容が失われる
- これを変更消失(ロストアップデート)という
- こうした問題を防ぐための対処法
- データベース管理システムではデータaにロック(鍵)をかける
- 咲にデータaをアクセスしたトランザクションの処理が終了するか、あるいはロックが解除されるまでほかのトランザクションを待たせる制御をする
- 参考 ダーティリード:他のトランザクションが更新中のコミットされていないデータを読み込むこと
ロックが必要な状況
- 事務員が二人
- Aさんは給与振り込み、Bさんは書類提出チェック
- 同じテーブルに書き込まれている
- Aさんがいろいろやった
- 給与振り込みはまだ、書類の提出もまだ
- 給与の振り込み終了の情報を書き戻す
- Bさんがいろいろやった
- 給与振り込みがまだ、書類の提出もまだ
- 書類の提出確認を書き戻す
社員マスタ
- 社員ID、社員名、今月給与振り込みステータス、書類の提出ステータス
P.333 デッドロック¶
- P.250 5.2.5 も参考にすること
- デッドロック:複数のデータに対してロックしようとして互いにロックの解除を待ち続けてしまう
- 例:図 6.8.2
- データA、B、Cを専有して処理するトランザクションTR1,TR2,TR3がある
- 各トランザクションは処理の進行に合わせて表に示される順(①→②→③)にデータを専有
- トランザクション終了時に3つの資源を一括して解放
- トランザクションTR1とトランザクションTR2はデッドロックを起こす可能性がある
- 再び図 6.8.2 を見る
- データを専有する順序が等しいトランザションTR1とTR3の間ではデッドロックは起こらない
- 異なる順や逆順でデータを専有するトランザクション間ではデッドロックが起きうる
- デッドロックが起きたときロールバックなどで 1 つのトランザクションを強制的に終了させてデッドロックを解除する
P.334 ロック方式¶
- 2相ロック方式・木規約
- ロック方式
- 第1相:使用するデータすべてにロックをかける
- 第2相:処理後にロックを解除する
- トランザクション内でのロック・解除はそれぞれ1回だけ
- 直列可能性は保証されるがデッドロック発生の可能性は 残る
- 木規約
- データに順番をつけてその順番どおりにロックをかける
- デッドロックが起きず、直列可能性を保証する
- データへの順番づけには木(有向木)を使う
- トランザクションの同時実行性が低くなるため特殊な用途で使う(どんなところで使うのだろう?)
- 参考:有向木
- 方向をもった有向グラフ(の 1 つ)
- データ構造とアルゴリズムを勉強しよう
- データベースは検索の便宜もあってデータ構造とアルゴリズムが大事
P.334 ロックの種類¶
- 占有ロック・共有ロックの 2 モード
- DBMS でトランザクションの同時実行性を高めるため
- 専有ロック
- データ更新するときに使うロック
- データに対するほかのトランザクションからのアクセスは一切禁止
- 共有ロック
- ふつうデータの読取りの際に使用されるロックで
- 参照だけを許可
- 表 6.8.2 参照:2 つのロックモードの組み合わせによる同時実行の可否
- 専有:占有または排他ともいう
- 共有:共用ともいう
- 共有ロックで同時実行性を高める
- 先行トランザクションがロックしたデータを後続トランザクションが参照できる
- 待ちがなくなり同時実行性が高まる
- たいていのシステムでは書き込みよりも読み込みの方が多い
P.335 ロックの粒度¶
- ロックをかける単位:表・ブロック・行
- ブロック:物理的なIOの単位
- ロックの単位をロックの粒度という。
- 粒度が小さければ小さいほど同時実行性があがる代わりにロックの回数が多くなり、ロック制御のためのオーバーヘッドが増える
- 粒度が大きいほどロックの解除待ちが長くなり、同時実行性が下がる
P.336 多版同時実行制御(MVCC:MultiVersion Concurrency Control)¶
- 同時実行性を高めつつ一貫性のあるトランザクシ ョン処理を実現する仕組み
- ふつう専有ロック中(更新中)のデータは参照できない
- 後続トランザクションはロックの解除を待つ
- 多版同時実行制御での対処
- 更新中のデータに対する参照要求に更新前(トランザクション開始前)の内容を返す
- 後続トランザクションを待たずに処理できる
- 専有ロックと共有ロックの同時確保で同時実行性を高める一方で、後続トランザクションには現在からさかのぼったある時点における一貫性のあるデータを提供する
- 整合性を欠いたデータの参照を防げる
参考:整合性を欠いたデータの参照¶
- ダーティリード
- アンリピータブルリード
- 再度読み込んだデータが他のトランザクションで更新されている
- 前回読み込んだ値と一致しない
- フ ァ ン ト ム リ ー ド
- 再度読み込んだデータの中に他のトランザ クションによって追加・削除されたデータがある
- 前回と検索結果が変わる
P.335 時刻印アルゴリズム¶
- ロック制御をせずに同時実行制御を行う方法としての時刻印(タイムスタンプ)アルゴリズム
- トランザクションが発生した時刻 T とデータのもつ読込み時刻 Tr、あるいは書込み時刻 Tw を比較して読み書きを判断する
- 読み込みの場合
- Tw≦T のときだけ読み込む
- 読み取ったあとは読み込み時刻 Tr にトランザクション発生時刻 T を設定
- 書き込みの場合
- Tw≦T かつ Tr≦T のときだけ書き込む
- 書き込み後、書込み時刻 Tw にトランザクション発生時刻Tを設定
- 参考:P.336 図 6.8.4
参考:楽観ロック¶
- 楽観的方式:ロック制御をしない他の方法
- 仮定:同じデータへのアクセス(更新要求)はめったに発生しない
- 処理を進めて更新直前にほかのトランザクションでそのデータが更新されたかどうかを確認する
- 更新された場合はロールバックする
- 実装例
- データベースに「更新回数」のようなカラムを持たせる
- データ取得時に更新回数も送る
- データ更新するときは更新回数つきでサーバーにリクエストを出す
- 更新回数が同じなら更新する
- 更新回数が違うなら更新要求を却下する
- ほぼ同じタイミングで複数の更新要求が出ることはあり、このときは更新が重複して異常が出る
- これが起きない(起きにくい)というのが最初に書いた「同じデータへの更新要求はめったに発生内」という仮定
P.336 障害回復管理¶
P.336 障害の種類¶
- データベースに発生する障害の三大分類
- 媒体障害:記憶媒体の故障でデータが消失
- システム障害:DBMSやOSのバグ・オペレータの誤操作によるシステムダウン
- トランザクション障害:プログラムのバグ・デッドロック発生でのトランザクションの強制終了など、実行中のトランザクションが異常終了
P.336 目標復旧時点¶
- RPO:Recovery Point Objective
- システム再稼働時に障害発生前のどの時点の状態に復旧させるかを示す概念で、データ損失の最大許容範囲
- 目標復旧時間(RTO、Recovery Time Objective)
- 災害による業務の停止が深刻な被害とならないために許容される時間
P.336 事前対策¶
- 障害回復:障害からデータベースを復旧して一貫性が保たれた元の状態に戻すこと
- 障害回復には次のファイルを事前に取得しておく必要がある
- ログファイル
- 障害やバグ対策の基本
- トランザクション処理でデータベースが更新されるとき,更新前ログ、更新後ログなどの更新履歴(変更情報)を取り、時系列に記録する
- ジャーナルファイル、ジャーナルログともいう
- 大量に出るので復旧や原因追及に必要十分な要素をピックアップする必要がある
- ログファイル容量などを見て自動でファイルが切り替わる(ローテーション)
- バックアップファイル
- 媒体障害に備えてデータベースとログファイルを定期的に別の媒体にバックアップ(退避)する
- データベースのバックアップは定期的に取る
- ログファイル切り替え時にログファイルのバックアップも取る
- ふつうn個のログファイルに対してログデータをログファイル1から順に書き込む
- ログファイル1が一杯になるとログファイル2へと切り替える(ローテーション)
- このタイミングでバックアップ
P.337 参考 バックアップの種類¶
- フルバックアップ:すべてのデータをバックアップする
- 差分バックアップ:直前のフルバックアップ からの変更分だけをバックアップする。
- 増分バックアップ:直前のフルバックアップ または増分バックアップからの変更分だけをバックアップする。
- メリット・デメリット
- フルバックアップは何も考えずにドカンと復旧できるが容量を食う
- 差分バックアップはバックアップに使う容量を減らせるが、復旧時に手間がかかる
P.337 媒体障害からの回復¶
- 媒体障害発生時:バックアップファイルとログファイルの更新後ログを使ってロールフォワード処理でデータ ベースを回復させる
- 参考:P.338 図6.8.6
- T1:バックアップファイル取得
- T2:媒体障害発生
- バックアップファイルを別の媒体にリストア、T1時点に復帰
- T1-T2間の更新データ回復:ログファイルの更新後ログによるデータベースの各レコードを順番に再現するロールフォワード処理
- 参考:差分バックアップ方式採用時
- フルバックアップファイルをリストア
- 直近の差分バックアップファイルのデータを追加
- 更新後ログでロールフォワード
P.338 トランザクション障害からの回復¶
- アプリケーションプログラムのバグやデッドロックを解除するための強制終了などでアプリケーションが異常終了したとき
- ログファイルの更新前ログを使ったロールバック処理でデータベースの内容をトランザクション開始時点の状態に戻す
- 参考:P.338 図6.8.7
- データxとyを更新しなければならないトランザクションがT1で開始
- データyの更新を行う前にT2で異常終了
- このままではデータxとyのつじつまが合わない
- T1からT2の間に行われたxの更新を取り消す必要が出る
- ログファイルの更新前ログによるロールバック処理 でトランザクション開始時点(T1)の状態に戻す
- 参考:データとログをメモリ上にバッファリングしている場合
- まだCOMMITされていないトランザクションはログ・バッファの内容で自動的にロールバック(ROLLBACK)される
P.339 システム障害からの回復¶
- 現在のデータベース管理システムでのディスクの入出力効率向上のための工夫
- データとログをメモリ上にバッファリング
- まずデータベース・バッファに対してデータの更新
- ある時間間隔でデータベース・バッファの内容をデータファイル(データベース)へ書き出す
- 書き出し時点を行った時点:チェックポイント
- チェックポイントの発生:トランザクションのCOMMITとは非同期で、トランザクションがCOMMITされてもデータベース・バッファの内容はデータファイルに書き出されない
- チェックポイント発生時、稼働中のトランザクション情報もログファイルに書き出される
ログ・バッファの内容¶
- トランザクションのCOMMITまたはチェックポイント発生でログファイルに書き出される
- システム障害発生時の問題
- データファイルに書き出されていないデータベース・バッファ上の更新データの消失
- P.340 図6.8.9 の TR2
- システム障害が発生した時点でCOMMITされていない
- データベース・バッファの内容が消失しても問題ない:再処理で対応
- 問題になるのはチェックポイント(T1)の前に開始されたTR1
- TR1はシステム再立上げ後に更新前ログを用いたロールバック処理で
- トランザクション開始時点の内容に戻す
図6.8.10の例¶
- チェックポイント(T1)後
- システム障害発生(T2)前にCOMMITされたトランザクションTR3,TR4による更新内容はまだデータファイルに書き出されていない
- システム障害が発生した直前のチェックポイント(T1)まではデータベースの内容が保証されている
- ここから更新後ログを用いてロールフォワード処理によって回復
- システム障害における障害回復はシステム障害 発生時のトランザクションの状態に応じて変わる
- チェックポイントを作ることでそれまで行われてきた更新内容はすべてデータベース・バッファからデータファイルに書き出される
- システム障害が発生してもチェックポイント以降の更新後ログだけでロールフォワード処理で回復できる
- 回復時間が短縮される
P341 6.8.4 問合せ処理の効率化¶
P.341 インデックス¶
- インデックス():データベースへのアクセス効率を上げるために使う
- 例えばデータ構造とアルゴリズムの意味で「木」を作っている
- 一般に検索対象の項目にインデックスをつけるとアクセス(検索)速度はあがる
- しかしシステム全体のパフォーマンスが遅くなることがある
- インデックスをつけるとインデックスの更新が走る
- この処理がどれだけパフォーマンスに影響するかが問題
- インデックスのつけ方はきちんと考える必要がある
- 参考
- 各データに複数の索引語を付けて検索時に具体的な値を与えることで,その値を含むすべてのデータを高速かつ簡単に検索できるように編成
- 蓄積された索引ファイルを転置ファイル(inverted file:インバ ーテッドファイル)という。
P.341 POINT インデックス設定時の留意点¶
- アクセス頻度の高い列(検索でよく使う項目)に張る
- いわゆる内部 ID 系(これは主キーとして勝手にインデックスがつく・つける)
- 更新頻度の多い列に対してインデックスを張らない
- 外部 ID としてのメールアドレス・ログイン ID に張ることは多い
- 行数の少ない表に対してインデックスを張っても効果は低い
- データのとり得る値の種類が少ない(データ値の重複が多い)列に対して張っても効果は低い
- それでも張ることはある
- 「推測するな。計測せよ。」
- データ値の重複に大きな偏りがある場合は効果が低い
- 初期のデータ挿入など多くの行を挿入するときはいったんインデックスを削除するといい
- 参考
- インデックスには重複を許さないユニークインデックスと重複を許 すデュプリケートインデックスがある
- 主キー項目にはユニークインデックスが張られる
P.341 上記POINTの④,⑤について¶
- P.342 表はインデックスを張ったある項目Xの値とその行数
- [例1]と[例2]を比べる
- データのとり得る種類は両方とも同じ
- [例2]のほうが重複の程度が平準
- [例1]のほうが大きく偏っている
- インデックスで1項目当たりの平均の検索効率の向上が期待できるのは[例2]
- ただしあくまで一般論
P.342 例1・例2の検索効率を確率的に考える¶
- [例1]の場合
- 検索条件が「項目X=A」である確率は(20/1200)
- Aの検索はインデックスが使える
- 目的のデータを検索するにはさらに20件を順次検索する必要が ある
- このときの最大比較回数は20
- 「項目X=B」の場合、1項目当たりの検索効率(期待値)は次の式で求められる
- (20/1,200)×20+(40/1,200)×40+(80/1,200)×80 +(160/1,200)×160+(300/1,200)×300+(600/1,200)×600=403
- [例2]の場合
- 1項目当たりの検索効率(期待値)は(200/1,200)×200×6=200
- 確率的意味からも[例2]のほうが検索効率がいい
- 参考
- 効率を下げる重複が多い値で検索する機会がほとんどない場合、実際の効率は例1の方が大きい可能性がある
- いつでも実際のケースでどうかを考える必要がある
- 参考
- インデックスを張った項目を検索条件にして絞り込んだ選択率が10〜20%を大きく超える場合,インデックスの効果はあまり期待できない
P.343 連結インデックス¶
TODO
2021-02-07 課題¶
- 先に進む前に録画してあるか確認しよう
進捗¶
- 前回の進捗
- 基礎知識編:「参考:楽観ロック」まで
- 本編:04-02終了
- 今回の進捗
- 基礎知識編:「6.8.4 問合せ処理の効率化」まで
- 本編:05-01終了
課題¶
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 勉強の日常組み込み系
- Julia:The Little Book of Julia Algorithmsを読んでみることにしました。適当に話します。
- そのうち取り組む事案:黒木さんの Julia での統計ネタ
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
TODO¶
- AWS のハンズオン
- 公式のハンズオン: 無料でできるハンズオンもたくさんある
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- 面白そう:Julia での機械学習アルゴリズム本
- Algorithms for Optimization by Mykel J. Kochenderfer and Tim A. Wheeler @mitpress
* 自分用メモ¶
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- 実際に競プロの問題をいくつか解いてみましょう。
* Matplotlib¶
- 本当に簡単な図を描く
- これを参考に scipy お絵描き
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
日々の勉強¶
Julia¶
- The Little Book of Julia Algorithms
- リポジトリの対象ディレクトリ:ここ
- その他参考
IT 基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- ネットワークの話もいい加減飽きたので、しばらく DB の話
復習¶
- 3 つのスキーマ
- ユーザーが見るレベル
- 正規化などをかけておいたデータベースにもっていけるレベル
- 個々のデータベースに合わせた具体的なレベル
- インメモリの DB:コンピューターの基本的なハードウェア構成と意味を復習しよう
本の記述を追いかける¶
P.336 障害回復管理¶
P.336 障害の種類¶
- データベースに発生する障害の三大分類
- 媒体障害:記憶媒体の故障でデータが消失
- システム障害:DBMSやOSのバグ・オペレータの誤操作によるシステムダウン
- トランザクション障害:プログラムのバグ・デッドロック発生でのトランザクションの強制終了など、実行中のトランザクションが異常終了
P.336 目標復旧時点¶
- RPO:Recovery Point Objective
- システム再稼働時に障害発生前のどの時点の状態に復旧させるかを示す概念で、データ損失の最大許容範囲
- 目標復旧時間(RTO、Recovery Time Objective)
- 災害による業務の停止が深刻な被害とならないために許容される時間
P.336 事前対策¶
- 障害回復:障害からデータベースを復旧して一貫性が保たれた元の状態に戻すこと
- 障害回復には次のファイルを事前に取得しておく必要がある
- ログファイル
- 障害やバグ対策の基本
- トランザクション処理でデータベースが更新されるとき,更新前ログ、更新後ログなどの更新履歴(変更情報)を取り、時系列に記録する
- ジャーナルファイル、ジャーナルログともいう
- 大量に出るので復旧や原因追及に必要十分な要素をピックアップする必要がある
- ログファイル容量などを見て自動でファイルが切り替わる(ローテーション)
- バックアップファイル
- 媒体障害に備えてデータベースとログファイルを定期的に別の媒体にバックアップ(退避)する
- データベースのバックアップは定期的に取る
- ログファイル切り替え時にログファイルのバックアップも取る
- ふつうn個のログファイルに対してログデータをログファイル1から順に書き込む
- ログファイル1が一杯になるとログファイル2へと切り替える(ローテーション)
- このタイミングでバックアップ
P.337 参考 バックアップの種類¶
- フルバックアップ:すべてのデータをバックアップする
- 差分バックアップ:直前のフルバックアップ からの変更分だけをバックアップする。
- 増分バックアップ:直前のフルバックアップ または増分バックアップからの変更分だけをバックアップする。
- メリット・デメリット
- フルバックアップは何も考えずにドカンと復旧できるが容量を食う
- 差分バックアップはバックアップに使う容量を減らせるが、復旧時に手間がかかる
P.337 媒体障害からの回復¶
- 媒体障害発生時:バックアップファイルとログファイルの更新後ログを使ってロールフォワード処理でデータ ベースを回復させる
- 参考:P.338 図6.8.6
- T1:バックアップファイル取得
- T2:媒体障害発生
- バックアップファイルを別の媒体にリストア、T1時点に復帰
- T1-T2間の更新データ回復:ログファイルの更新後ログによるデータベースの各レコードを順番に再現するロールフォワード処理
- 参考:差分バックアップ方式採用時
- フルバックアップファイルをリストア
- 直近の差分バックアップファイルのデータを追加
- 更新後ログでロールフォワード
P.338 トランザクション障害からの回復¶
- アプリケーションプログラムのバグやデッドロックを解除するための強制終了などでアプリケーションが異常終了したとき
- ログファイルの更新前ログを使ったロールバック処理でデータベースの内容をトランザクション開始時点の状態に戻す
- 参考:P.338 図6.8.7
- データxとyを更新しなければならないトランザクションがT1で開始
- データyの更新を行う前にT2で異常終了
- このままではデータxとyのつじつまが合わない
- T1からT2の間に行われたxの更新を取り消す必要が出る
- ログファイルの更新前ログによるロールバック処理 でトランザクション開始時点(T1)の状態に戻す
- 参考:データとログをメモリ上にバッファリングしている場合
- まだCOMMITされていないトランザクションはログ・バッファの内容で自動的にロールバック(ROLLBACK)される
P.339 システム障害からの回復¶
- 現在のデータベース管理システムでのディスクの入出力効率向上のための工夫
- データとログをメモリ上にバッファリング
- まずデータベース・バッファに対してデータの更新
- ある時間間隔でデータベース・バッファの内容をデータファイル(データベース)へ書き出す
- 書き出し時点を行った時点:チェックポイント
- チェックポイントの発生:トランザクションのCOMMITとは非同期で、トランザクションがCOMMITされてもデータベース・バッファの内容はデータファイルに書き出されない
- チェックポイント発生時、稼働中のトランザクション情報もログファイルに書き出される
ログ・バッファの内容¶
- トランザクションのCOMMITまたはチェックポイント発生でログファイルに書き出される
- システム障害発生時の問題
- データファイルに書き出されていないデータベース・バッファ上の更新データの消失
- P.340 図6.8.9 の TR2
- システム障害が発生した時点でCOMMITされていない
- データベース・バッファの内容が消失しても問題ない:再処理で対応
- 問題になるのはチェックポイント(T1)の前に開始されたTR1
- TR1はシステム再立上げ後に更新前ログを用いたロールバック処理で
- トランザクション開始時点の内容に戻す
図6.8.10の例¶
- チェックポイント(T1)後
- システム障害発生(T2)前にCOMMITされたトランザクションTR3,TR4による更新内容はまだデータファイルに書き出されていない
- システム障害が発生した直前のチェックポイント(T1)まではデータベースの内容が保証されている
- ここから更新後ログを用いてロールフォワード処理によって回復
- システム障害における障害回復はシステム障害 発生時のトランザクションの状態に応じて変わる
- チェックポイントを作ることでそれまで行われてきた更新内容はすべてデータベース・バッファからデータファイルに書き出される
- システム障害が発生してもチェックポイント以降の更新後ログだけでロールフォワード処理で回復できる
- 回復時間が短縮される
2021-02-21 オンライン プログラミング勉強会の記録¶
- 先に進む前に録画してあるか確認しよう
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
進捗¶
- 前回の進捗
- 基礎知識編:「P.341 6.8.4 問合せ処理の効率化」まで
- 本編:05-01終了
- 今回の進捗
- 基礎知識編:「P.345 6.8.5 データベースのチューニング」まで
- 本編:05-03終了
課題¶
- 適当に選んで取り組んでみてください。
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- データ構造やアルゴリズムの勉強をしましょう: 以下参考です.
- いろいろな数学系コードを見てみましょう: github, mathcodes
TODO¶
- AWS のハンズオン
- 公式のハンズオン: 無料でできるハンズオンもたくさんある
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- 実際に競プロの問題をいくつか解いてみましょう。
Matplotlib¶
TeX¶
- 状況に応じて現代数学探険隊から適当に紹介
データ構造とアルゴリズムに関するリポジトリ¶
IT基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
2021-03-07 オンライン プログラミング勉強会の記録¶
- 先に進む前に録画してあるか確認しよう
- オリジナルコンテンツへのリンク
- 勉強会のコンテンツまとめ:GitHub へのリンク
進捗¶
- 前回の進捗
- 基礎知識編:「P.345 6.8.5 データベースのチューニング」まで
- 本編:05-03終了
- 今回の進捗
予定¶
- 基礎知識編: 本のP.345から
- 次回から何するか?
- 本編
課題¶
- 適当に選んで取り組んでみてください。
- matplotlib を忘れないように、簡単なグラフをいくつか描いてみてください。
- TeX でいろいろな式を書いてみましょう。
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。
- データ構造やアルゴリズムの勉強をしましょう: 以下参考です.
- いろいろな数学系コードを見てみましょう: github, mathcodes
TODO¶
- AWS のハンズオン
- 公式のハンズオン: 無料でできるハンズオンもたくさんある
- 東大の AWS クラウド講義資料を眺めてみてください。せっかくなので状況を見て(私の勉強も兼ねて)「勉強会前半パート」で取り上げようと思います。(とりあえず当面はやらない感じにする?)
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
- 実際に競プロの問題をいくつか解いてみましょう。
Matplotlib¶
TeX¶
- 状況に応じて現代数学探険隊から適当に紹介
データ構造とアルゴリズムに関するリポジトリ¶
IT基礎知識¶
- 応用情報の本を一日2ページくらい眺めてみてください。毎日やれば大体 1 年で読み終わります。