2020-07-12 課題
メモ:先に進む前に録画してあるか確認しよう
自分用メモ
- 勉強のおすすめ:AtCoder はどうか?C++の解説もあるし、仕事・評価にも割と直結するし、具体的な問題つきで勉強できる。
- https://atcoder.jp/contests/apg4b
- C++のコードをPythonで書き直してみるだけでもかなりの勉強になるはず
- Python によるアルゴリズム https://qiita.com/cabernet_rock/items/cdd12b07d213b67d0530
- 遅延型方程式に対するコメント追加
- matplotlib のチュートリアルを読もうの会
- 公式情報に触れる重要性
- 古い情報が古いと書いてあったりする:たとえば
pylab - Gallery
- 見ていて面白い
- 「どこをいじるとどう変わるか」が視覚的にわかる
- 公式情報なのできちんとアップデートしてくれている(はず)
- 公式情報にソースがあるので自分でいろいろ書き換えていて破滅したとき、必ずオリジナルを復元できる
Matplotlib
- とりあえず本当に簡単な図を描く
- 今回はシグモイド関数
\begin{align} \sigma(x) = \frac{1}{1 + e^{-x}}. \end{align}
1
2
3
4
5
6
7
8
9
10
11
12 | import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10, 10, 501)
y = 1 / (1 + np.exp(-x))
plt.plot(x, y, label="sigmoid")
plt.grid()
plt.legend()
#plt.axes().set_aspect('equal', 'datalim') # アスペクト比を合わせる
plt.show()
|
TeX の記録
- 凸不等式
- geq, nabla, langle, rangle
\begin{align} f(y) \geq f(x) + \langle \nabla f(x), \, y-x \rangle. \end{align}
競プロ、AtCoder
ABC087B - Coins
あなたは、500 円玉を A 枚、100 円玉を B 枚、50 円玉を C 枚持っています。 これらの硬貨の中から何枚かを選び、合計金額をちょうど X 円にする方法は何通りありますか。 同じ種類の硬貨どうしは区別できません。2 通りの硬貨の選び方は、ある種類の硬貨についてその硬貨を選ぶ枚数が異なるとき区別されます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | def solve(A, B, C, X):
lst = []
for a in range(A+1):
for b in range(B+1):
for c in range(C+1):
lst.append(500*a+100*b+50*c == X)
# 下のセルで補足
return sum(lst) #len(list(filter(lambda x: x == True, lst)))
[A, B, C, X] = [2, 2, 2, 100]
print(solve(A, B, C, X)) # 2
[A, B, C, X] = [30, 40, 50, 6000]
print(solve(A, B, C, X)) # 213
|
注意
ブール値は True = 1、False = 0 として足せるらしい。
| sum([True, False, True, False, False])
|
上のコードをリスト内包表記で簡潔に
1
2
3
4
5
6
7
8
9
10
11
12 | #A, B, C, X = [int(input()) for i in range(4)]
def solve(A, B, C, X):
return sum(500*a+100*b+50*c == X
for a in range(A+1)
for b in range(B+1)
for c in range(C+1))
[A, B, C, X] = [2, 2, 2, 100]
print(solve(A, B, C, X)) # 2
[A, B, C, X] = [30, 40, 50, 6000]
print(solve(A, B, C, X)) # 213
|
1 以上 N 以下の整数のうち、10 進法での各桁の和が A 以上 B 以下であるものの総和を求めてください。
サンプル
- 20 以下の整数のうち、各桁の和が 2 以上 5 以下なのは 2,3,4,5,11,12,13,14,20 です。これらの合計である 84 を出力します。
| [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
|
| a <= b && b <= c
a <= b <= c
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | def solve(N, A, B):
lst = []
for i in range(1, N+1):
if A <= sum(map(int, str(i))) <= B:
lst.append(i)
return sum(lst)
N, A, B = [20, 2, 5]
print(solve(N, A, B)) # 84
N, A, B = [10, 1, 2]
print(solve(N, A, B)) # 13
N, A, B = [100, 4, 16]
print(solve(N, A, B)) # 4554
|
わからなければ分解しよう
| i = 20
map(int, str(i))
lst = []
for a in str(i):
lst.append(int(a))
print(lst)
|
| i = 20
print(list(str(i)))
print(list(map(int, str(i))))
i = 123
print(list(map(int, str(i))))
i = 3564565
print(list(map(int, str(i))))
|
| ['2', '0']
[2, 0]
[1, 2, 3]
[3, 5, 6, 4, 5, 6, 5]
|
| i = 3564565
l = len(str(i))
int(i / (10**(l-1)))
i % 10**(l-1)
|
リスト内包表記で簡潔に
| def solve(N, A, B):
return sum(i for i in range(1, N+1) if A <= sum(map(int, str(i))) <= B)
N, A, B = [20, 2, 5]
print(solve(N, A, B)) # 84
N, A, B = [10, 1, 2]
print(solve(N, A, B)) # 13
N, A, B = [100, 4, 16]
print(solve(N, A, B)) # 4554
|
IT 一般論
- シンプルなシステムからの成長
- ハード構成の基礎:CPU・メモリ・HDD、キャッシュ
- データ構造とアルゴリズム
- 連結リストと配列:どんな特性があるか?
- スタックとキュー:いつどこで使うか?どう実装するか?
前回
- システムの成長についていろいろ見た
- ちょっと復習してからハードの構成へ
そもそもなぜ IT 一般論の話をしだしたか
- データ構造の話をするため
- メモリの話をしないとリストと配列(とベクター)の違いが説明できない
- 一言でいうと、リストと配列はメモリ上にどうデータを置くかが違う
- データの置き方によってデータアクセスの仕方が変わり、「何が得意か」が変わる
- リスト:要素の追加・削除に都合がいいが、ランダムアクセスと値の更新処理に弱い
- 配列:要素の追加・削除は不便だが、ランダムアクセスと値の更新処理に強い
- ベクター:要素の追加・削除に比較的強く、ランダムアクセスと値の更新処理も強い
- 単純にベクターだけ使っていればいいわけでもない:メモリ効率という観点
- メモリ単独の話をしても多分わからない
- 統計学がらみの話は割とすぐにパフォーマンス(速度)の話になる
- いわゆるビッグデータというやつで、大量のデータを何回も計算しないといけない
- 計算を速くしないとやっていられない
- GPU 使うなり何なり割とすぐにハード面の話が出てくる
- 「メモリを積もう」みたいな話も出てくる
- 計算速度は直接には CPU の役割だったり
シンプルなシステムからの成長
- 適当な Web システムを考える。
- 具体的にはショッピングサイトなどをイメージすればいい。
- サーバー構成やインフラ設計という言葉で調べると色々出てくる
- サーバー構成の画像:Google 画像検索
大事で面倒な話:「サーバー」とは何か?
- 何でもいいが、とりあえず一つ参考ページ
- 物理的なモノとソフトウェア両方ある
- 1 つの物理的なサーバーの中に複数のソフトウェアとしてのサーバーが入っていることがある
- 仮想化・コンテナみたいな話をしだすともっと面倒なことになる
- 今回も多少は詳細化するが、まずは「一度は聞いたことがある」レベルにするのが目的。
基本構成
- ソフトウェアとしてのサーバーが 3 つ
- Web サーバー:Apache・Nginx:単純に HTML を返すサーバー
- アプリケーションサーバー:いわゆる「アプリケーション」。プログラマーがプログラムを書く部分で、ログインユーザーごとに処理が分かれるとか。最終的に Web サーバーがクライアントに返す HTML の形でデータをまとめる。もちろんここでデータベースのアクセスもある。
- データベースサーバー:顧客情報や製品情報を持っている。
一番単純
- 物理サーバーは 1 つ
- ソフトウェアとしての Web サーバー・アプリケーションサーバー・データベースサーバーが載っている。
- 開発者が開発するときは実際にこういう状況で開発している(こともある)
状況に応じていろいろ分かれる
- 例えば実際にシステムにかかる負荷によって変わる
- データベースの負荷が高い
- 物理サーバーを追加してデータベースサーバーをそちらに載せ替える。
- Web のリクエストがさばききれないとき
- Web サーバーを切り分けた上で 2 台にわける
- アプリケーションサーバー・データベースサーバーは 1 つの物理サーバーに載せる。
他の状況
- データベースの読み込み負荷が高い:Memcache や Redis のようなキャッシュサーバーを(物理サーバーごと)追加する。
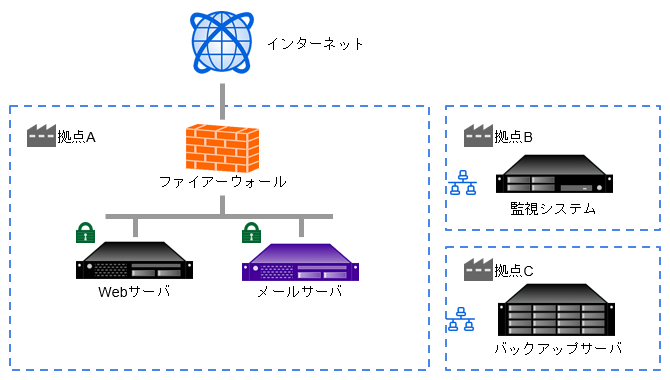
- セキュリティが気になってきた:Web サーバーの前にセキュリティ用のファイアーウォール
- セキュリティが絡むとサーバー構成がまた複雑になる。
- 上記画像参考
- 直接外とやり取りするところに外部向けファイアーウォール
- DMZ の中で外部とやり取りするサーバーが置かれる:いわゆるアプリケーションサーバー
- アプリケーションサーバーと「内部」がやり取りするところにまたファイアウォールを置く
- 「内部」というのは顧客データベースなどの社外に公開しないサーバー
- ファイアウォールを二重に置くことで、絶対に触ってはいけないところに対して二重の防御を敷く
- 外部公開しているサーバーがクラックされても内部にアクセスできないようにする
- 内部から危険な情報を外に出せないようにする
ハードウェア構成の基礎
- CPU、キャッシュ(キャッシュメモリ)、メモリ、HDD・SSD、キーボード・マウスくらいまでの大まかな話
コンピューター構成の5大要素
- 参考
- 制御装置:命令の実行・周辺装置の制御。担当は CPU
- 演算装置:データを処理。担当は CPU
- 記憶装置:データを保存。担当はメモリ・ハードディスク・SSD
- 人間でいうと脳(短期記憶)、「机」、「本棚」
- それぞれの「記憶装置」に意味がある
- 短期記憶は容量が小さいが高速に計算に回せる
- 机は本が置ける
- 本棚に取りに行く手間が省ける分だけデータを取り出すのは速い
- もちろん脳内短期記憶から取り出すよりは遅い
- 本を置ける量は本棚より少ない
- 本棚はたくさん本が置ける
- データを本棚まで取りに行くのは大変(時間がかかる)
- たくさんモノが置ける
- 入力装置:データを受けつける。担当はキーボード・マウスなど
- 出力装置:データや処理の結果を外に出す。ディスプレイ・プリンタ等
CPU からキャッシュ

補足コメント
- CPU にはコアという概念がある
- 「CPU がクアッドコア」とか何とかいうときの「コア」
- 最近の分散コンピューティングで重要な要素
- 他人の CPU を借りることもよくある
- 「コロナの解析のためにあなたのマシンパワーを貸してください」
- 「ブロックチェーン・ビットコインの計算をさせていた」
- 各コアが計算の単位:コアがたくさんあると並列に計算させられて、処理速度が上がる(類の処理もある)
- コアがたくさんある CPU を使うと個人のコンピューターレベルでもある程度並列処理できる
- 構成はいろいろあるが「スパコン」でも適当な意味で CPU をたくさん並べて使っている
- 1 つ 1 つのスペックが高いコンピューターをたくさん並べる
- 1 つ 1 つのスペックは大したことがないかもしれないが、冗談のようなコンピューター数・並列数で性能を出す
- Google などではトラックに「PC」レベルのコンピューターを大量に積み込み、それで並列計算させていることもあるらしい
- しばらく使っていると各トラックごとにどんどんマシンが壊れていく
- いくつ以上のマシンが壊れたらトラックに積んであるマシンをすべて廃棄して全取り換えする、みたいな話を見たことがある
- どれが故障しているかをいちいち調べるよりも一定の稼働率から下がったら全部つぶす方が「コスパが高い」
- トヨタなどで「不良品のねじが入ったらその箱は全部捨てる」みたいなエピソードを聞くが、まさにそういう感じ
- スケールによってコスパの概念自体が大きく変わるのも大事な認識
- コアに対してキャッシュがある
- 距離が近い順に L1, L2, L3
- キャッシュの容量が大きくなっていく順
- 速度は落ちていく
- キャッシュの後ろにいわゆるメモリがある
- 参考ページ
- レジスターやら何やら細かく見ていくといろいろある
- 大事なこと
- 何はともあれ、現実的にそういう風にできている
- 必要だからそうなっている:少なくとも何かしら、歴史的な理由はある
複数のキャッシュレベル
- 前にやったレイテンシー比較
- L1 cache reference
- Read 1 MB sequentially
- 次のセルで細かい説明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from disk 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
|
追加説明
「それぞれのキャッシュには役割があるから」
「キャッシュは容量が大きいほどデータ転送速度が遅く、記憶密度が高く、省電力という性質を持つため、必要性に応じて異なる種類のキャッシュを使い分けるのが有利だから」
- 省電力の意義:単純にエコなだけではない
- 省電力だと熱も出にくい
- 熱が高くなると熱暴走が起こりうる:逆に計算効率が悪くなる
- マシンを物理的に傷つけにくくので故障もしにくくなる
補足:いろいろなキャッシュ
- キャッシュはいろいろなところにある
- ブラウザのキャッシュ:一度読み込んだwebサイトのデータを取っておいて次に読み込むときのロードを速くする
- サイトのロゴなどの画像はそうそう変わらないうえ、画像ファイルは重い(容量が大きい)のでダウンロードにも時間がかかる
- 「自分だけサイトが更新されない?」みたいなことがあったら、それはキャッシュを見ている可能性がある
- webシステムでのメモリデータベース(メモリキャッシュ)
- データベースを使うときのデータベースサーバーでのメモリキャッシュ(Redis などのメモリデータベースのキャッシュとはまた違う)
- ブラウザのキャッシュについては、「ブラウザが重くなった時」などで調べると「キャッシュを削除しよう」みたいな話が出てくる。
- cf. このページ
- 「GoogleのWebブラウザ「Chrome(クローム)」が重いときに考えられる原因には、キャッシュや履歴などの問題が考えられます。」
- ここでコメントしたタイプの「キャッシュ」は日々の PC 利用を快適にする上でも大事
- 快適にする上での情報収集やその意味を理解する上で大事というべきか
補足その 2:「キャッシュ」があるとなぜ重くなる?
- ブラウザの話
- キャッシュが大量にあると必要なキャッシュを探す手間が出てくる
- 数十くらいの中ならまだしも、数百・数千・数万から探すとなると探すだけで時間がかかる
- ブラウザを長いこと使っていると、実際にキャッシュがそのくらいに膨れてくる
- 削除して余計な検索処理(計算)がなくなれば、かえって早くなる
- こういうところで「検索」「探索」問題が出てくる
- Google が出てきたのもある意味でこういう文脈
- 検索はデータ構造・アルゴリズムの中でも一番基本的なテーマ
補足
- 世の勉強系基本コンテンツの主流はたいてい次の 2 つ
- 前者の基本コンテンツとその内容は大事だが、構造的に全体像・そこから広がる世界の広がりが見えにくい
- もちろん各種テーマ特化型のコンテンツやオムニバス型のコンテンツもある
- 状況に合わせて適切なコンテンツを組み合わせて勉強するべき
- 複数の本をあえて並行して勉強する意義・意味もある
データ構造とアルゴリズム
- 鶏と卵で、同時に考えるべきテーマ:何かをするためにはどンな風にデータを持ってどんな処理をすれば効率がいいか?
- 効率にもいろいろな観点がある
- 単純な処理速度・メモリ消費量・計算量
- 「データの持ち方」「データ構造」に関して軽く
- 本棚をどう整理するか?
- 本の名前順
- 分野を分けたうえで名前順
- 手元に置くのはよく読む本、近い本棚には比較的読む本を分野ごとに名前順、あまり読まない本は押し入れに適当に詰め込む
- 図書館のような大規模なところでは「閉架」という概念がある
- 目的に応じて適切な本の置き方は変わる
- 蔵書の数や質でも変わる
- 図書館なのか本屋なのか
- 本屋だと平積み・面陳列といった概念もある
- 図書館情報学という分野さえある
- どんなデータ構造がいいかはその時々で変わる
(連結)リストと配列
- 何が違うのか?
- メモリ上のデータの配置やデータの「つなぎ方」
- 状況によって使い分ける
リストの特徴
- 要素数は変わることが前提
- データを(先頭に)追加するのは簡単
- データの削除も比較的簡単
- 先頭から 1 つずつ順に処理するならそれなり
- 検索やデータの書き換えが遅い:連結構造をたどる必要がある
配列の特徴
- 要素数は固定
- データの追加・削除が重め
- 気分的にはその都度メモリ領域を確保しなおす必要がある:特に追加
- データの参照・書き換えが速い:アドレスが連続なので先頭さえわかれば「そこから何番先」と直指定できる
- 処理によっては「リストで遅ければ配列で書き直す」みたいなことはよくある
ベクター(参考)
- 「要素数可変の配列」
- リストのように要素追加・削除が比較的低コストで、要素の参照・書き換えも配列のように速い
- 何が問題か:要素の追加が楽なように余計なメモリ領域を確保する
- ハードウェア組み込みプログラムのように、メモリがカツカツの状況では使えない
シーケンシャルアクセス
- レイテンシーのところでも出てきた
- 配列でもリストでも、「先頭から順番になめていく」こと
参考:HDD でのシーケンシャルアクセス・断片化・ディスクデフラグ
デフラグとは、デフラグメンテーション(defragmentation)の略です。PCはハードディスクに読み書きを行っていますが、何度も繰り返すうちに連続した広い領域が確保できなくなり、狭い複数の領域に分散して書き込むようになります。データが分散している状態を「断片化」といい、断片化しているとファイルを読み込むのが遅くなり、PC速度が低下します。
断片化したデータを連続した状態に整理することをデフラグといいます。デフラグを定期的に行うことで、読み込み、書き込みが速くなるだけではなく、PC起動が早くなったり、ハードディスクの残り空き容量が増える、というメリットがあります。
なぜ遅くなるのか
- ディスク上でデータ断片化すると何が問題か?
- 例:動画が見たい
- 動画用のファイルが HDD 上でいろいろなところに散らばっている
- ある個所からある個所に行くとき、断片化していると、HDD の読み取りの針を物理的に移動させないといけない
- この時間が長い:処理が重くなる原因
- 気分的には「連結リスト」
- こうした話題は何だかんだで普段の PC ライフにも絡んでくる
- 最近は OS を入れる部分は SSD、データを大量に入れる部分は HDD という構成がよくある
- SSD はまだ高いので HDD は死んでいない
補足:なぜ空き容量が増えるのか
HDDにデータを書き込む時、データはセクタという最小単位(主に512バイトまたは4,096バイト)に切り分けられ、プラッタの同心円状に作られているトラックと呼ばれる領域に保管されます。
- データ書き込みには最小単位がある
- 断片化して「最小単位」未満のデータで書きこまれてしまっていると、その分容量が無駄になる。
- デフラグするとこの無駄が解放される
- 「配列では一括でズドンとメモリ領域を取る」という「ズドンと取った」状態はこんな感じ。
- 他に触らせない・触らせられないのでこの手の無駄ができる
- ベクターで無駄が出るといったのはこういう状況
{kind=link}
{kind=link}
{kind=link}